


Exploring the dbt Cloud semantic layer in Preset







While many teams create and manage databases, datasets, and metrics using Preset's user interface, some organizations prefer to handle them in source control using a data transformation layer like dbt. dbt simplifies the process of generating reliable, clean datasets and metrics for visualization in Preset.
Last year Preset integrated with dbt Cloud via its user interface, enabling data teams to define data models (databases, datasets, and metrics) as version-controlled assets within dbt Cloud and easily synchronize them with Preset Cloud with only a few clicks. In this blog post we’d like to show how the functionality has been upgraded to support the dbt Semantic Layer integration based on MetricFlow. This provides a path for upgrading to dbt 1.6 and 1.7, maintaining dbt as the source of truth for models and metrics in Apache Superset.
Note that in our current integration Superset uses the definitions stored in dbt in order to build its own queries and run them directly against analytical databases. This is a workflow that is appropriate for exploration and discovery (for revealing unknowns) as we will discuss below. In the future we also plan to support a separate integration where metrics are computed directly by dbt Cloud instead, which is well suited for the presentation of well defined metrics. Both workflows are, of course, well supported by Superset.
The Jaffle Shop
In this post we’re going to show how to connect Preset to the Jaffle Shop project running in dbt Cloud. In particular, we’ll be using https://github.com/dbt-labs/jaffle-sl-template for the dbt project, since it contains metrics and semantic models based on Metricflow.
After following the instructions in the repository we should end up with 14 metrics:
$ mf list metrics
✔ 🌱 We've found 14 metrics.
The list below shows metrics in the format of "metric_name: list of available dimensions"
• customers_with_orders: customer__customer_name, customer__customer_type, customer__first_ordered_at, customer__last_ordered_at, location__location_name and 6 more
• new_customer: customer__customer_name, customer__customer_type, customer__first_ordered_at, customer__last_ordered_at, location__location_name and 6 more
• order_total: customer__customer_name, customer__customer_type, customer__first_ordered_at, customer__last_ordered_at, location__location_name and 6 more
• large_order: customer__customer_name, customer__customer_type, customer__first_ordered_at, customer__last_ordered_at, location__location_name and 6 more
• orders: customer__customer_name, customer__customer_type, customer__first_ordered_at, customer__last_ordered_at, location__location_name and 6 more
• food_orders: customer__customer_name, customer__customer_type, customer__first_ordered_at, customer__last_ordered_at, location__location_name and 6 more
• revenue: metric_time, order_id__customer__customer_name, order_id__customer__customer_type, order_id__customer__first_ordered_at, order_id__customer__last_ordered_at and 15 more
• order_cost: customer__customer_name, customer__customer_type, customer__first_ordered_at, customer__last_ordered_at, location__location_name and 6 more
• median_revenue: metric_time, order_id__customer__customer_name, order_id__customer__customer_type, order_id__customer__first_ordered_at, order_id__customer__last_ordered_at and 15 more
• food_revenue: metric_time, order_id__customer__customer_name, order_id__customer__customer_type, order_id__customer__first_ordered_at, order_id__customer__last_ordered_at and 15 more
• food_revenue_pct: metric_time, order_id__customer__customer_name, order_id__customer__customer_type, order_id__customer__first_ordered_at, order_id__customer__last_ordered_at and 15 more
• revenue_growth_mom: metric_time, order_id__customer__customer_name, order_id__customer__customer_type, order_id__customer__first_ordered_at, order_id__customer__last_ordered_at and 15 more
• order_gross_profit: metric_time, metric_time, order_id__is_drink_order, order_id__is_drink_order, order_id__is_food_order and 5 more
• cumulative_revenue: metric_time, order_id__customer__customer_name, order_id__customer__customer_type, order_id__customer__first_ordered_at, order_id__customer__last_ordered_at and 15 moreTo set up the project in dbt Cloud we added a BigQuery database, and gave access to a GitHub repo containing the Jaffle Shop project. Then we set up two jobs; the first one was simply:
dbt parseAnd the second one:
dbt buildAfter those two jobs have ran successfully we’re ready to start syncing our models and metrics to a Preset workspace. But first, let’s talk about metrics.
What’s in a metric?
Here, we need to make an important distinction between a metric in dbt and a metric in Superset. dbt is a tool designed to transform data in a declarative way through code, so that transformations can be reviewed, tested, versioned, and have their governance tracked. Because of that, in dbt a metric is the final product. It has been joined with relevant dimensions, and is defined for certain time grains.
On the other hand, in Superset the metric is just a starting point for data exploration and visualization. Because of that, metrics are less strictly defined than in dbt. Metrics in Superset are simple aggregations, and Superset allows users to freely filter metrics and apply any time grain that they want. And while dimensional joins are not supported in the Superset semantic layer, existing feature proposals make them happen at exploration time, after metrics have been defined.
This impedance mismatch means that not all dbt metrics can be represented in Superset. Because a Superset metric is simply an aggregation on top of a dataset (very similar to a dbt measure) only metrics that depend on single dbt model can be synced to Superset. This also precludes metrics that have dimensional joins.
Technically these metrics could be implemented on top of virtual datasets that perform the required joins, but Superset’s dataset-centric workflow would make metric discovery too complicated and provide a subpar user experience. Instead, we believe that syncing only the metrics that are simple aggregations allows for a better visualization workflow, where the user needs a highly interactive system that empowers them to reveal unknowns. In that workflow pre-defined dimensional joins and time grains slow and hinder the user.
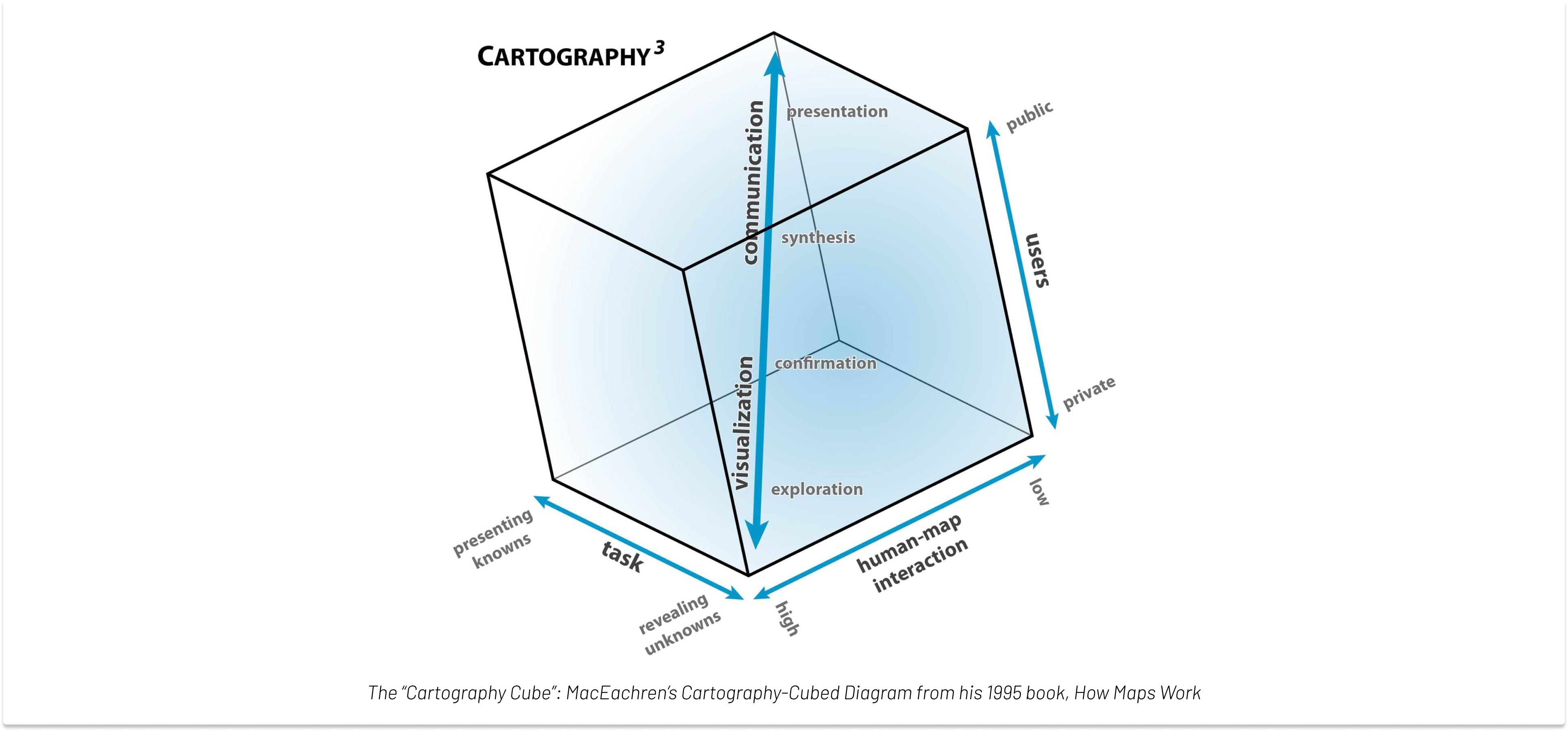
In the image above we see the “Cartography Cube”, a concept that has been used for decades to explain the different aspects of working with data. In the bottom vertex we have the visualization workflow, where data is limited to a few users, and has the purpose of revealing unknowns, requiring a highly interactive interface, an area where the Superset chart builder excels.
After the exploration and confirmation phases there’s a synthesis phase, where metrics can be narrowed down to certain time grains and fixed dimensional joins, to be presented in dashboards and reports. This is a concept closer to the dbt metric workflow, where only pre-defined joins are allowed. It’s important to mention that both workflows have their value, and our goal is to support all stages of data, from visualization to presentation.
Metric examples
Let’s look at a couple of example metrics from the Jaffle Shop project. The first one is large_order. Here’s its definition in dbt:
metrics:
- name: large_order
description: "Count of orders with order total over 20."
type: simple
label: "Large Orders"
type_params:
measure: order_count
filter: |
{{ Dimension('order_id__order_total_dim') }} >= 20The large_order metric can be easily represented in Superset’s semantic model, since it’s simply a measure with an additional filter. To represent it in Superset we just need to create a dataset that corresponds to the orders model, and add the following metric definition:
SUM(CASE WHEN order_total >= 20 THEN 1 END)Because in Superset metrics are aggregations, we need to move the filter predicate into the projection using a CASE statement. This is a common pattern that not only allows us to represent the metrics in Superset, but also helps with optimizing queries when multiple metrics from the same model are being computed at once, since they can be computed in a single scan of the dataset.
On the other hand, a metric like new_customers is defined under the customers model, but is built upon a measure from the orders model. The SQL that Metricflow generates (for a BigQuery database) looks like this:
SELECT
COUNT(DISTINCT customers_with_orders) AS new_customer
FROM (
SELECT
customers_src_10000.customer_type AS customer__customer_type
, orders_src_10000.customer_id AS customers_with_orders
FROM `project`.`dataset`.`orders` orders_src_10000
LEFT OUTER JOIN
`project`.`dataset`.`customers` customers_src_10000
ON
orders_src_10000.customer_id = customers_src_10000.customer_id
) subq_7
WHERE customer__customer_type = 'new'Since the metric defintion has a join (more especifically, a LEFT OUTER JOIN), the metric cannot be represented as an aggregation in a dataset when the dbt project is synced to Superset. Another metric from the Jaffle Shop project that cannot be synced for the same reason is order_gross_profit.
Two additional metrics, median_revenue and revenue_growth_mom cannot be expressed in Superset because their SQL definitions are too complex to be translated into a single aggregation.
In the future we will offer an integration that delegates to dbt Cloud the task of computing the metrics across different dimensions, allowing these more complex metrics to be visualized in Superset. We believe these two integrations complement each other well: the current one allows for quick exploration and discovery, while the other one will allow for the presentation of well defined business metrics.
Configuring the sync
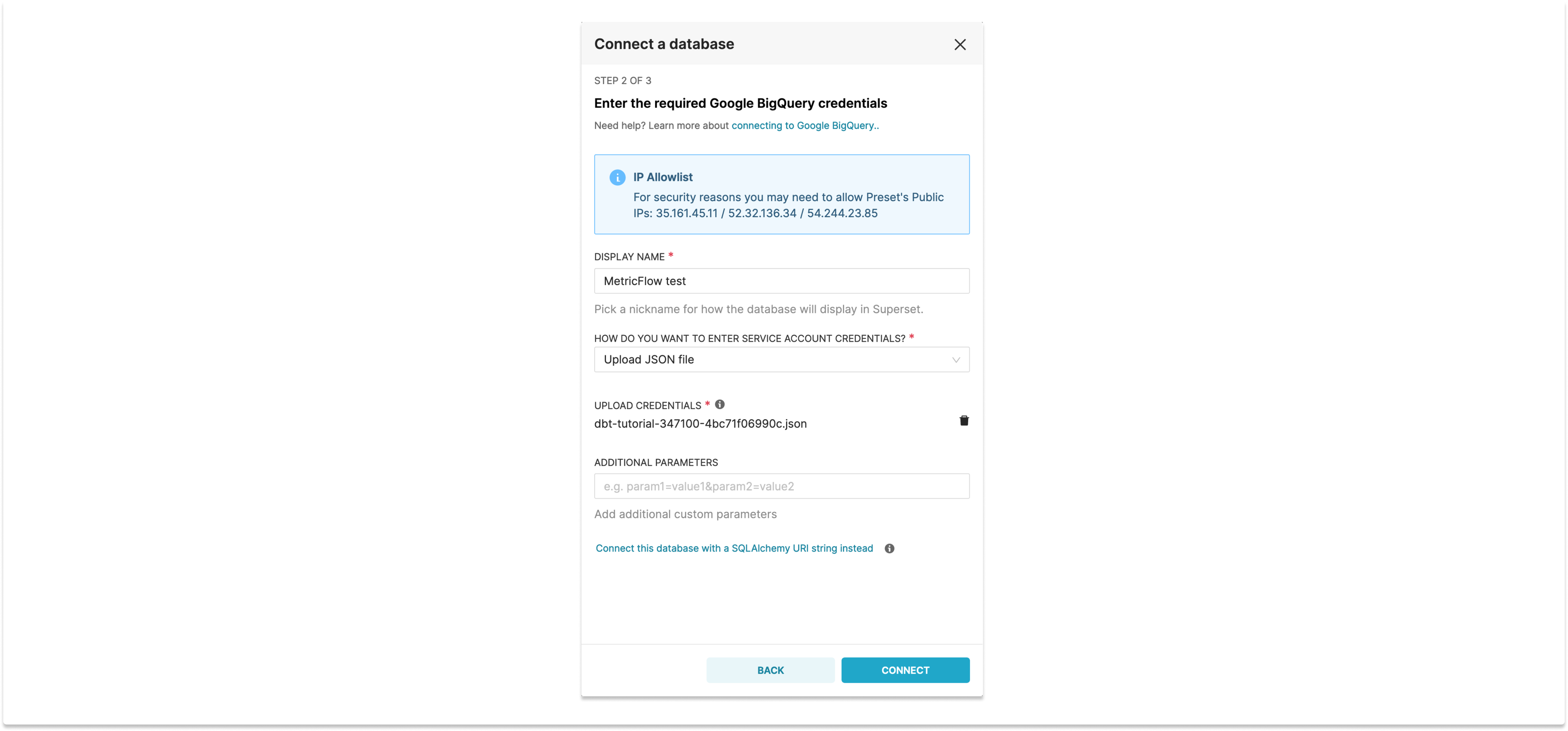
Once we have our project running, configuring the sync is easy. The first step is to add the database to Superset. In our example we’re using BigQuery, so we just need to upload the JSON file with the credentials (the exact same one used to create the project in dbt):
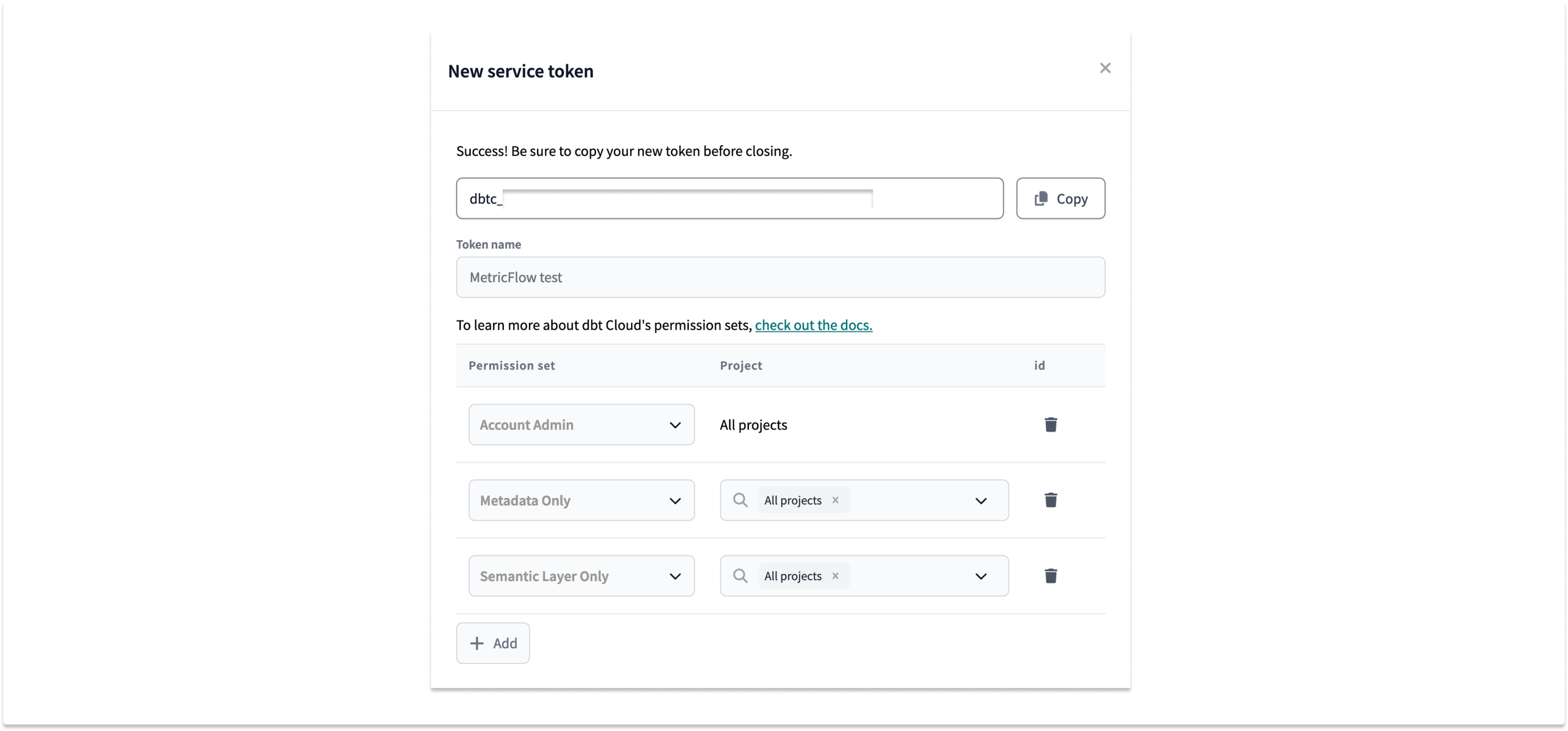
To allow the Preset workspace to connect to dbt Cloud in order to get the metadata we are going to need an access token. The token should have permission to access the account (in order to list projects and jobs), as well as for metadata and the semantic layer itself:
Once we have the token, we can go to the “Advanced” section of the database configuration in Superset, open the “dbt Cloud” pane, and choose an account, a project, a job, and the models that we want to synchronize:

And that’s it! The models and metrics should sync when we click “Finish”, and they will be kept in sync by a process that runs periodically. Now, if we want to look at large orders over time we can simply open the dataset and drag and drop the larger_order metric:

Using the CLI
Alternatively, it’s also possible to use the Preset CLI to sync metrics from dbt/Metricflow into one or more Superset workspaces. Like with the UI sync, the only requirement is that the database associated with the dbt project is already configured in the workspaces, and its name matches the database name from dbt Cloud.
To install the CLI:
$ pip install preset-cliOnce the CLI is installed, you just need to run preset-cli superset sync dbt-cloud ${DBT_TOKEN}. You will be prompted to choose a workspace and a dbt job:
$ preset-cli superset sync dbt-cloud ${DBT_TOKEN}
Choose one or more workspaces (eg: 1-3,5,8-):
# Preset Internal #
✅ (1) The Data Lab
> 1
https://example.app.preset.io/
Using account My Account [id=123] since it's the only one
Choose a project:
(1) Analytics [id=45]
(2) MetricFlow test [id=67]
> 2
Choose a job:
(1) Parse [id=12345]
(2) Build [id=67890]
> 2
[08:28:56] INFO: preset_cli.cli.superset.sync.dbt.datasets: Updating dataset model.jaffle_shop.customers datasets.py:119
[08:29:01] INFO: preset_cli.cli.superset.sync.dbt.datasets: Updating dataset model.jaffle_shop.metricflow_time_spine datasets.py:121
[08:29:11] INFO: preset_cli.cli.superset.sync.dbt.datasets: Updating dataset model.jaffle_shop.order_items datasets.py:121
[08:29:15] INFO: preset_cli.cli.superset.sync.dbt.datasets: Updating dataset model.jaffle_shop.orders datasets.py:121Alternatively, you can pass the workspace(s) and the account/project/job IDs directly to the comand, if you want to run the sync without being prompted:
$ preset-cli \
> --workspaces=https://example.app.preset.io/ \
> superset sync dbt-cloud \
> ${DBT_TOKEN} ${ACCOUNT_ID} ${PROJECT_ID} ${JOB_ID}This can be run periodically using a cron job, or configured to run with CI/CD so that any changes to the dbt data models are automatically pushed to your Preset workspaces. This is an approach that works really well with managing your Superset assets (datasets, charts, dashboards) under source control.
Ready to explore?
Preset's integration with dbt Cloud is available for teams on the Preset Enterprise plan. For organizations that need dedicated infrastructure, check out our managed private cloud offering. If you're interested in seeing a product demo or learning more about how Preset synchronizes with dbt, reach out to our team!
Related Reading
- Announcing Preset Cloud's Integration with dbt Core: Sync datasets and metrics from dbt to Preset
- Announcing Preset's UI Integration with dbt Cloud: Connect dbt Cloud directly from the Preset UI
- Understanding the Superset Semantic Layer: Superset's built-in semantic layer capabilities
- Version Control Superset Charts and Dashboards: Managing Superset assets as code
