


Announcing Preset Cloud's Integration with dbt™




Preset is excited to announce our integration with dbt Core!
dbt is a framework for managing data transformation SQL queries in source control and running them inside your database. dbt makes it easy to reliably produce clean datasets and metrics for visualization in Preset.
Preset offers a thin semantic layer that allow users to take a dataset-centric approach to enrich tabular data with metadata. The additional metadata helps users to explore the data, providing certification, description of columns, metrics and derived columns computed at query execution time, and much more.
While you can create and register databases, datasets, and metrics in Preset using the UI, increasingly organizations want these assets managed in source control as part of the software development lifecycle. With this integration, you can now define databases, datasets, and metrics as version controlled assets using dbt and sync them to Preset Cloud.
Getting Started
We're running a demo of the workflow outlined in this post on July 19th. You can signup for that event or watch the recording afterwards at this link.
In this blog post we’ll demonstrate how easy it is to connect dbt with Preset, in a bidirectional way:
- sources, models, and metrics from dbt can be quickly exported to be explored inside Preset
- charts and dashboards in Preset linked to dbt objects can be pushed back as exposures
We'll start with the jaffle_shop project from the dbt tutorial with some modifications and show how to use a CLI tool to keep it in sync with a Preset workspace.
Here’s what our lineage graph looks like for jaffle_shop to start:
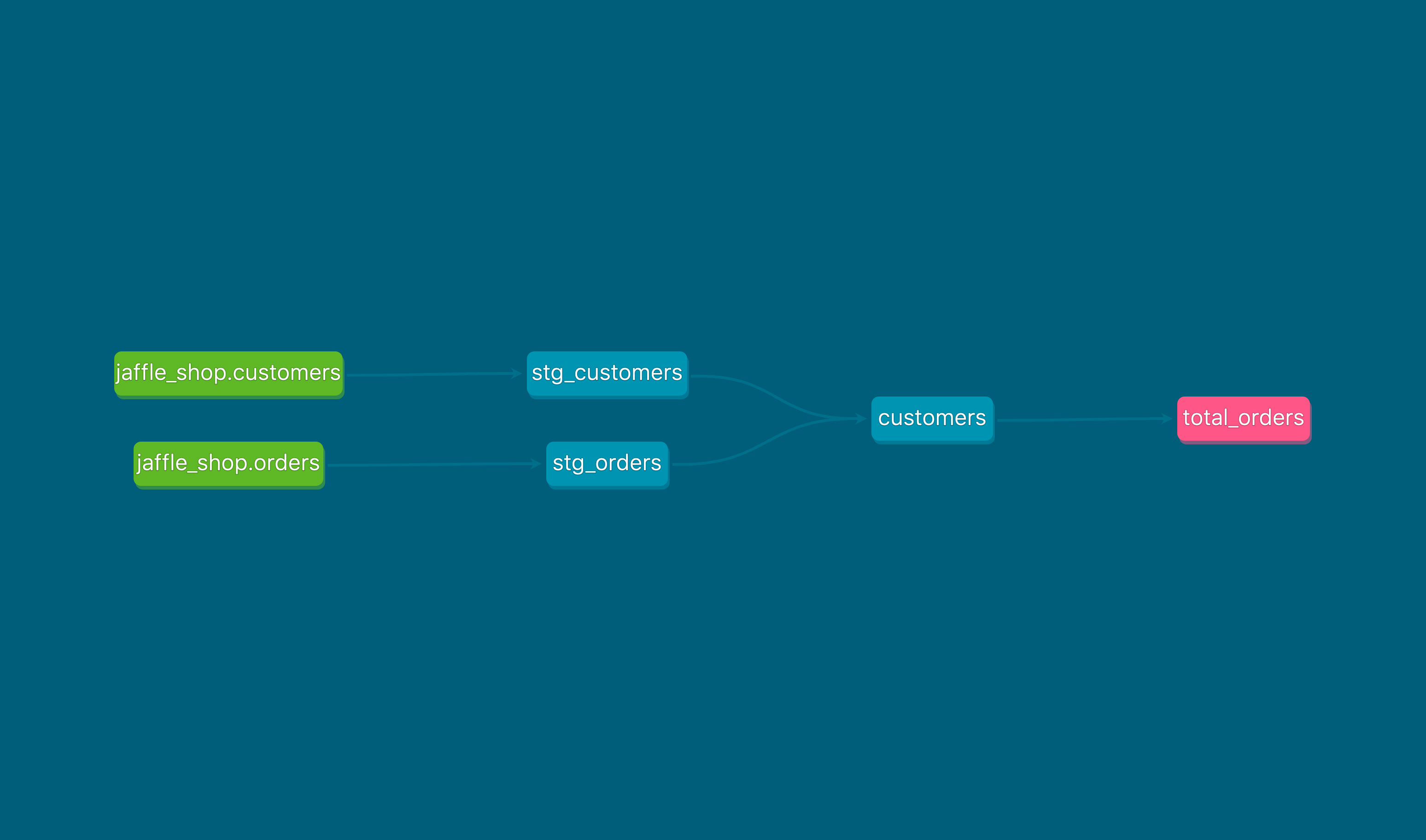
The only modifications made to the project were adding jaffle_shop.customers and jaffle_shop.orders as sources, and adding a new metric called total_orders. You can see the modified files in this GitHub repository.
Synchronizing sources, models, & metrics from dbt
Once we have our dbt project ready we can use the Preset CLI to synchronize sources, models, and metrics into datasets in Preset. To install the CLI we need a modern Python interpreter (Python v3.8+) and to run:
% pip install "git+https://github.com/preset-io/backend-sdk.git"You can read more about the CLI in the blog post Managing Apache Superset assets as code, which goes into details about how to use the tool on Preset workspaces (including how to generate authentication credentials).
Note that the CLI interacts with the Preset API, which is a feature of our Enterprise plan.
With the CLI installed, we can push assets from dbt into a Preset workspace with a single command:
% preset-cli --workspaces=https://abcdef12.us1a.app.preset.io/ \
> superset sync dbt \
> ~/Projects/dbt-integration-blog-post/jaffle_shop/target/manifest.json \
> --project=jaffle_shop --target=dev --import-dbHere’s a breakdown of the command:
--workspaces=https://abcdef12.us1a.app.preset.io/: is used to specify the workspace to where the assets should be synchronized. This can be a comma-separated list if you want to synchronize with multiple workspaces, and is optional. If omitted you will be prompted to choose from a list, unless you have a single workspace.superset sync dbt: thepreset-clihas a series of subcommands for interacting with Superset instances (each Preset workspace is a Superset instance). This one is used to push assets from dbt.~/Projects/dbt-integration-blog-post/jaffle_shop/target/manifest.json: the path to the compiled dbt manifest (withdbt compile).--project=jaffle_shop: the name of the project. In theory this could be read from the manifest path (though it can’t be found inside the manifest!), but that could be error prone, so you need to pass it explicitly.--target=dev: the dbt target to use, from your dbt profile.--import-db: a flag indicating if the associated database should be created in Preset.
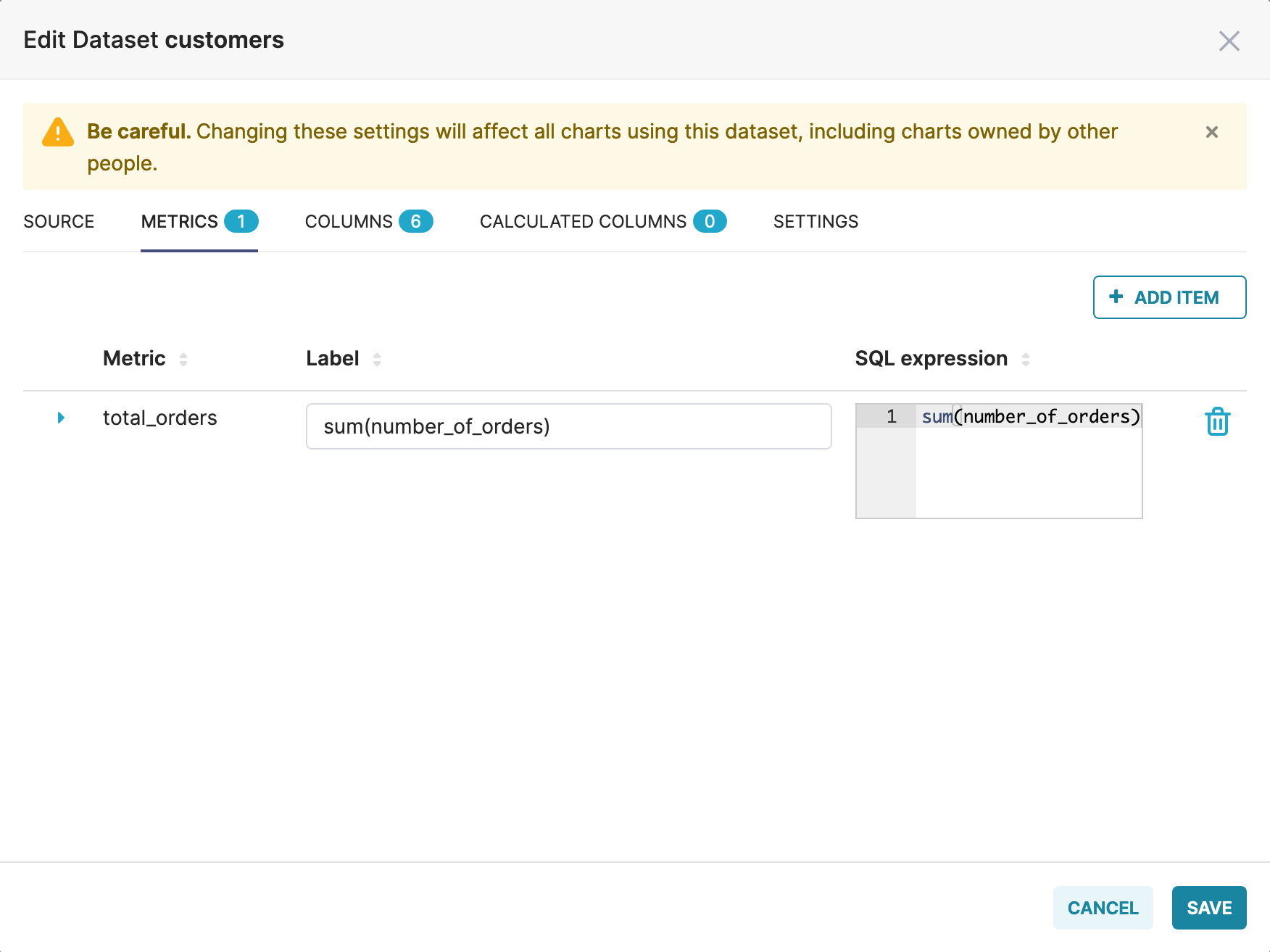
After running this command, we should see 3 new datasets in Preset:

What happened to jaffle_shop.customers and jaffle_shop.orders?
These two tables live in separate BigQuery projects and need to be synced separately.
We can also see that the total_orders metric was created correctly:
We can run the command again, after regenerating manifest.json, in order to update Preset with any changes that were made to the dbt project.
Synchronizing Exposures from Preset back to dbt
Now let’s create a simple dashboard using the datasets we just imported from dbt. We can create a chart with the total number of purchases per customer and visualize it as a pie chart in a dashboard:
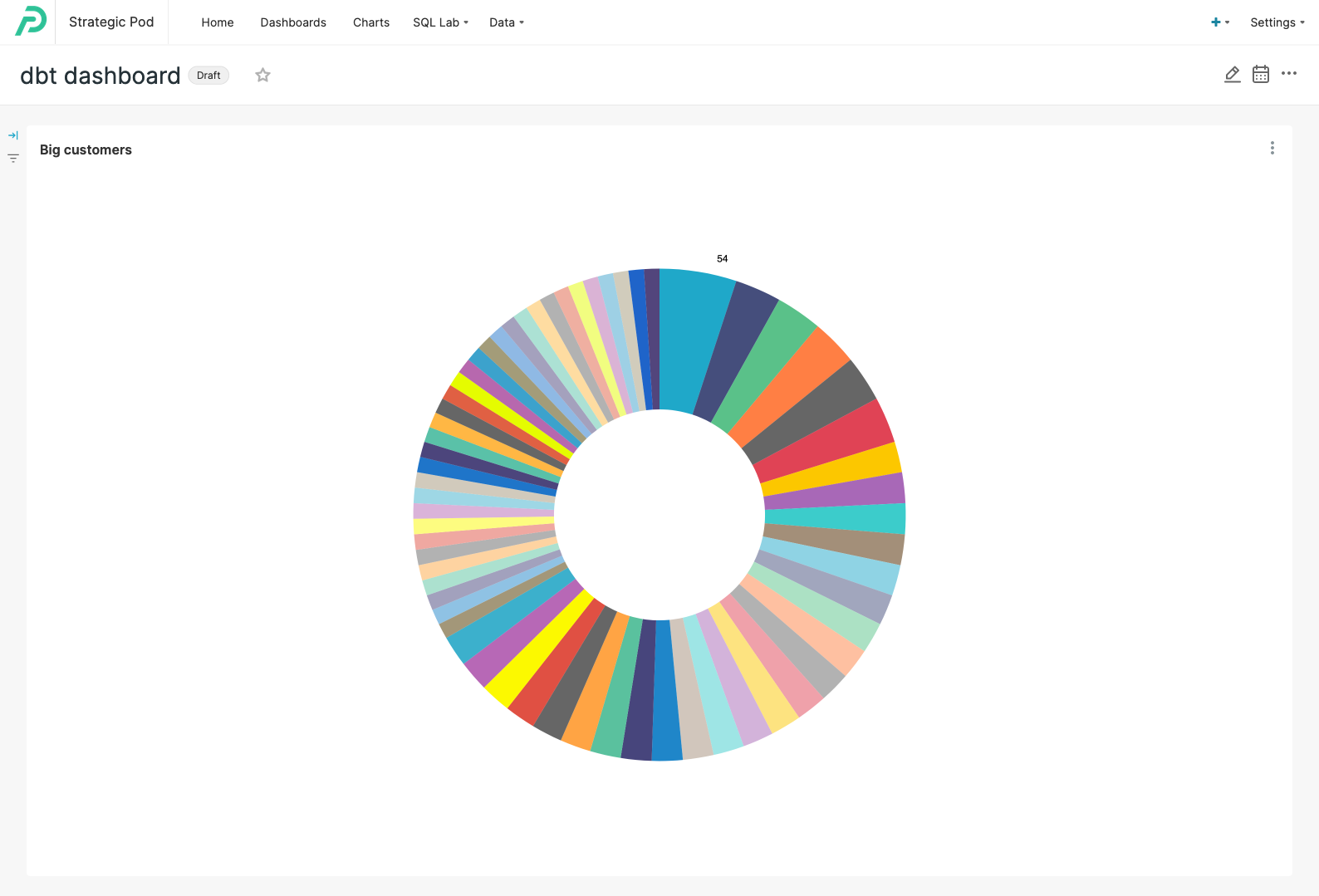
If we want to synchronize this dashboard back to dbt as an exposure all we have to do is:
% preset-cli --workspaces=https://abcdef12.us1a.app.preset.io/ \
> superset sync dbt \
> ~/Projects/dbt-integration-blog-post/jaffle_shop/target/manifest.json \
> --project=jaffle_shop --target=dev --import-db \
> --exposures=~/Projects/dbt-integration-blog-post/jaffle_shop/models/exposures.ymlThis should create a file like this one:
version: 2
exposures:
- name: Big customers [chart]
type: analysis
maturity: low
url: https://abcdef12.us1a.app.preset.io/superset/explore/?form_data=%7B%22slice_id%22:+1%7D
description: ''
depends_on:
- ref('customers')
owner:
name: admin admin
email: admin@preset.io
- name: dbt dashboard [dashboard]
type: dashboard
maturity: low
url: https://abcdef12.us1a.app.preset.io/superset/dashboard/1/
description: ''
depends_on:
- ref('customers')
owner:
name: admin admin
email: admin@preset.ioRunning dbt compile again we should see the following lineage graph:
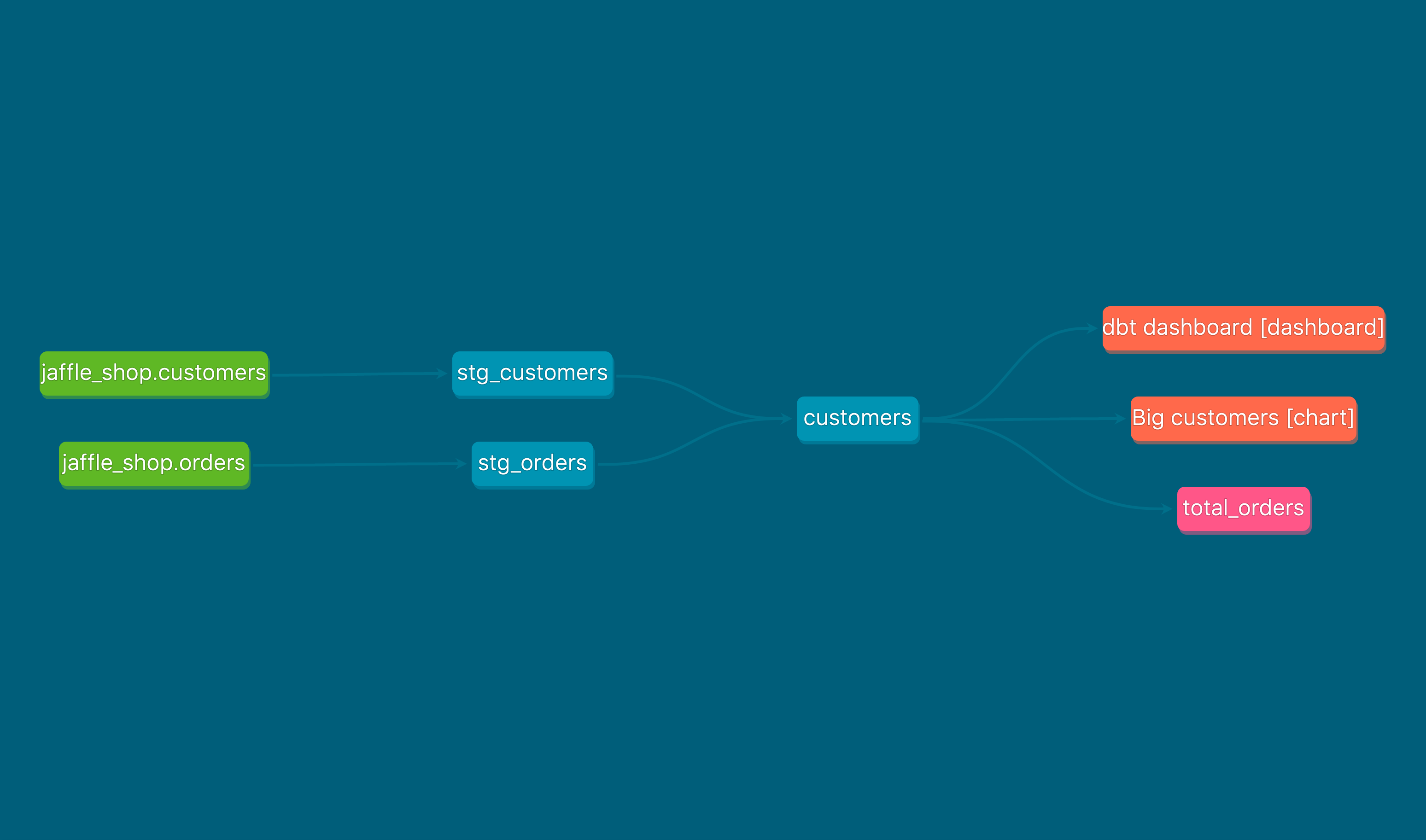
Synchronizing Preset charts and dashboards back as exposures is incredibly valuable as a way of keeping track of which models are being consumed downstream of dbt. In the future we hope to be able to add not only charts and dashboards as exposures, but also SQL Lab saved queries.
Continuous Deployment
Once we know the synchronization commands are working as expected we can automate them in our deployment pipeline, so that every time the dbt project is updated the assets are automatically published to Preset. This can be easily done using a GitHub action, with the only complicated part being managing all the credentials (for the database and for Preset).
We can see the GitHub action here:
name: 'Publish resources to Preset workspace'
env:
WORKSPACE: ${{ secrets.WORKSPACE }}
DBT_PROFILES_DIR: /home/runner/work/dbt-integration-blog-post/dbt-integration-blog-post
DBT_GOOGLE_BIGQUERY_KEYFILE_DEV: /home/runner/dbt-service-account.json
DBT_GOOGLE_PROJECT_DEV: ${{ secrets.DBT_GOOGLE_PROJECT_DEV }}
DBT_GOOGLE_BIGQUERY_DATASET_DEV: ${{ secrets.DBT_GOOGLE_BIGQUERY_DATASET_DEV }}
on:
push:
branches:
- main
pull_request:
jobs:
publish:
name: 'Publish resources'
runs-on: ubuntu-latest
defaults:
run:
shell: bash
steps:
- name: 'Checkout CLI'
uses: actions/checkout@v3
with:
repository: preset-io/backend-sdk
path: preset-cli
- name: 'Install CLI'
run: |
cd preset-cli
pip install .
cd ..
- name: 'Install dbt'
run: |
pip install dbt-core dbt-bigquery
- name: 'Checkout'
uses: actions/checkout@v3
- name: 'Authenticate using service account'
run: 'echo "$KEYFILE" > $DBT_GOOGLE_BIGQUERY_KEYFILE_DEV'
env:
KEYFILE: ${{ secrets.DBT_GOOGLE_BIGQUERY_KEYFILE_DEV }}
- name: 'Compile manifest'
run: |
cd jaffle_shop
dbt compile
cd ..
- name: 'Publish resources'
env:
PRESET_API_TOKEN: ${{ secrets.PRESET_API_TOKEN }}
PRESET_API_SECRET: ${{ secrets.PRESET_API_SECRET }}
run: |
preset-cli --workspaces=${WORKSPACE} superset sync dbt \
./jaffle_shop/target/manifest.json \
--profiles=profiles.yml \
--project=jaffle_shop --target=dev --import-dbThe action does the following steps:
- Download the Preset CLI from its repository.
- Install the CLI using
pip. - Install dbt, also with
pip. Note that we also install the BigQuery connector, needed for this project. - Checkout the dbt project repository.
- Copy the contents of the credentials file from a GitHub secret to a file.
- Compile the project to generate
manifest.json. - Finally, publish all the sources, models, and metrics to Preset running in a Preset workspace.
In order for this to work, we need to copy our profiles.yml into the repository, replacing all sensitive information with GitHub secrets:
jaffle_shop:
outputs:
dev:
dataset: "{{ env_var('DBT_GOOGLE_BIGQUERY_DATASET_DEV') }}"
fixed_retries: 1
keyfile: "{{ env_var('DBT_GOOGLE_BIGQUERY_KEYFILE_DEV') }}"
location: US
method: service-account
priority: interactive
project: "{{ env_var('DBT_GOOGLE_PROJECT_DEV') }}"
threads: 1
timeout_seconds: 300
type: bigquery
target: devFinally, create the following secrets for the repository in GitHub:
DBT_GOOGLE_BIGQUERY_DATASET_DEV: the name of the BigQuery dataset.DBT_GOOGLE_BIGQUERY_KEYFILE_DEV: the contents ofcredentials.jsonfrom the BigQuery project.DBT_GOOGLE_PROJECT_DEV: the name of the BigQuery project.PRESET_API_SECRET: a Preset token secret, created at https://manage.app.preset.io/app/user.PRESET_API_TOKEN: a Preset token, created at https://manage.app.preset.io/app/user.WORKSPACE: the URL of the Preset workspace.
Conclusion
Want a live demo of the workflow outlined in this post? We're running a demo of the workflow outlined in this post on July 19th. You can signup for that event or watch the recording afterwards at this link.
In this blog post we've shown how to use the Preset CLI to synchronize the dbt semantic layer — sources, models, and metrics — to one or more Preset instances running on Preset. This allows users to explore and quickly iterate on a solid foundation, bringing out the best of both tools. We hope that this example will inspire you to explore new ways of building a modern data stack!
What about integration with dbt Cloud? Stay tuned! We're working on the integration and we're excited to share more very soon.
Some other resources:
- The implementation of the CLI benefitted immensely from the dbt-superset-lineage project by Slido.
- How to Deploy dbt to Production using GitHub Actions
- How HomeToGo connected dbt and Superset
Related Reading
- Exploring the dbt Cloud Semantic Layer in Preset — Using dbt Cloud's MetricFlow integration
- Announcing Preset's UI Integration with dbt Cloud — Connect dbt Cloud directly from the Preset UI
- Understanding the Superset Semantic Layer — Superset's built-in semantic layer capabilities
- Dataset-Centric Visualization with dbt and Snowflake — End-to-end data workflow tutorial
