


Maximize Your Data Lakehouse Using Dremio Architecture




Dremio and the data lakehouse
The data lake is a modern architectural approach where data lives in low cost object storage and is accessed directly for analytic purposes. Initial ingestion of data into the data lake is often simpler, with more advanced transformations carried out in place or left to ad-hoc analytics further up the stack (ELT). While there are advantages and disadvantages to this approach compared to a traditional SQL-speaking data warehouse on top of an ETL layer, the low cost and agility the data lake provides to data practicioners has made it a modern staple of the cloud data platform.
The so-called data lakehouse is in some sense an evolution of the data lake. In a data lakehouse, data is distributed across various data lakes and silos, but SQL queries and direct access are managed and accelerated through a lakehouse platform.
When thinking about making the shift to a data lakehouse platform, some critical details to consider:
- To what extent does the data lakehouse duplicate data?
- How does cost and performance scale as the organization's data and access needs become more complex?
- What level of performance is required by analytics and BI software higher up the stack?
- How is data governed, metadata collected, and lineage traced?
- Is it a first-party offering directly from a cloud services vendor or a third-party? How well will the lakehouse integrate with the rest of the data stack?
Based originally on open-source Apache Arrow, Dremio is a lakehouse platform designed to sit on top of cloud object storage and other SQL speaking datasources. We have blogged the basics of using Dremio with Superset before. However, a lot has changed with both technologies since then, and it's time to take a deeper look.
Apache Superset, like other business intelligence (BI) and analytics applications, has stiff performance preferences because user experience is acutely impacted by slow query times. How fast a data lakehouse can respond to SQL queries for large amounts of data is therefore essential.
While conceptually similar to Presto, Trino, Athena, and other data lake query engines, Dremio distinguishes itself with an emphasis on outperforming the competition in query speed and resource consumption. It delivers this through a number of architectural features, including:
- Automatic and intelligent resource scaling
- Columnar data caching
- Data transport optimizations via Apache Arrow's Flight RPC framework
- Direct, transparent query acceleration via reflections
- Vendor-specific deployments for tighter integration with each cloud ecosystem
On that last note, Dremio has a number of deployments available that include architectures specialized for each cloud ecosystem.
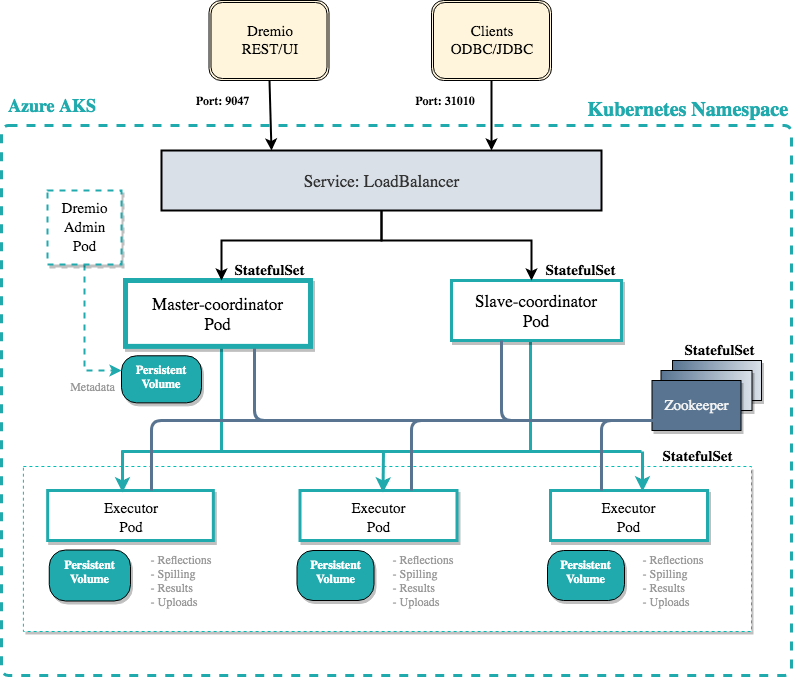
Dremio's generalized architecture includes coordinators and executors spawned to carry out jobs. Each vendor-specific deployment is a different realization of the same general architecture.
I spent a few weeks using Superset to analyze large datasets in Dremio and have a few tips to help you get the most out of these two technologies when used together in a data lake architecture.
Tip 1: Use reflections
Dremio's reflections feature creates reduced, reordered physical representations of the base data to accelerate query performance. There are three types of reflections in Dremio:
- Raw reflections – A raw reflection includes one or more fields from the anchor dataset, sorted, partitioned and distributed by specific fields.
- Aggregation reflections – An aggregation reflection includes one or more dimension and measure fields from the anchor dataset, sorted, partitioned and distributed by specified fields.
- External reflections – An external reflection is an unmanaged reflection, which allows users to reuse existing datasets and summary tables built in external systems as reflections in Dremio.
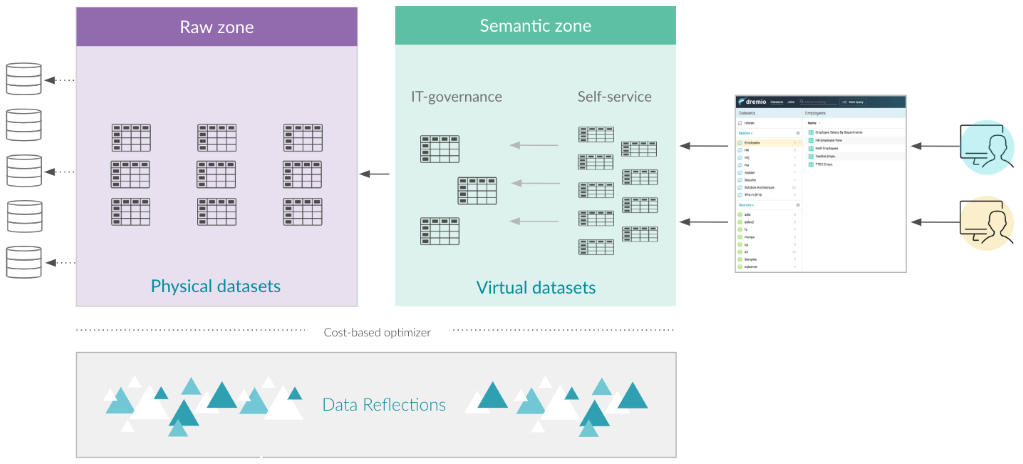
Having the right reflection for common data access patterns is important, but Dremio's query optimizer is smart enough to choose the right one for the job if multiple reflection types exist for a single datasource while still being transparent to the user.
In my testing, reflections reduced the time to query a billion row table from ~4 minutes to seconds. Superset brought a further 10x reduction in query time on cached data to provide a maximally responsive dashboard experience.
Check out a guide on how to configure reflections here.
Tip 2: Tweak Superset's caching behavior
Apache Superset has customizable (and extensible) query caching behavior that can be tuned to best match the rate at which data is refreshed in a given data-lake. For example, if a batch process updates a datasource once a day, extending the cache timeout for the dataset to match will yield the fastest possible responses while minimizing unnecessary queries against the data lake.
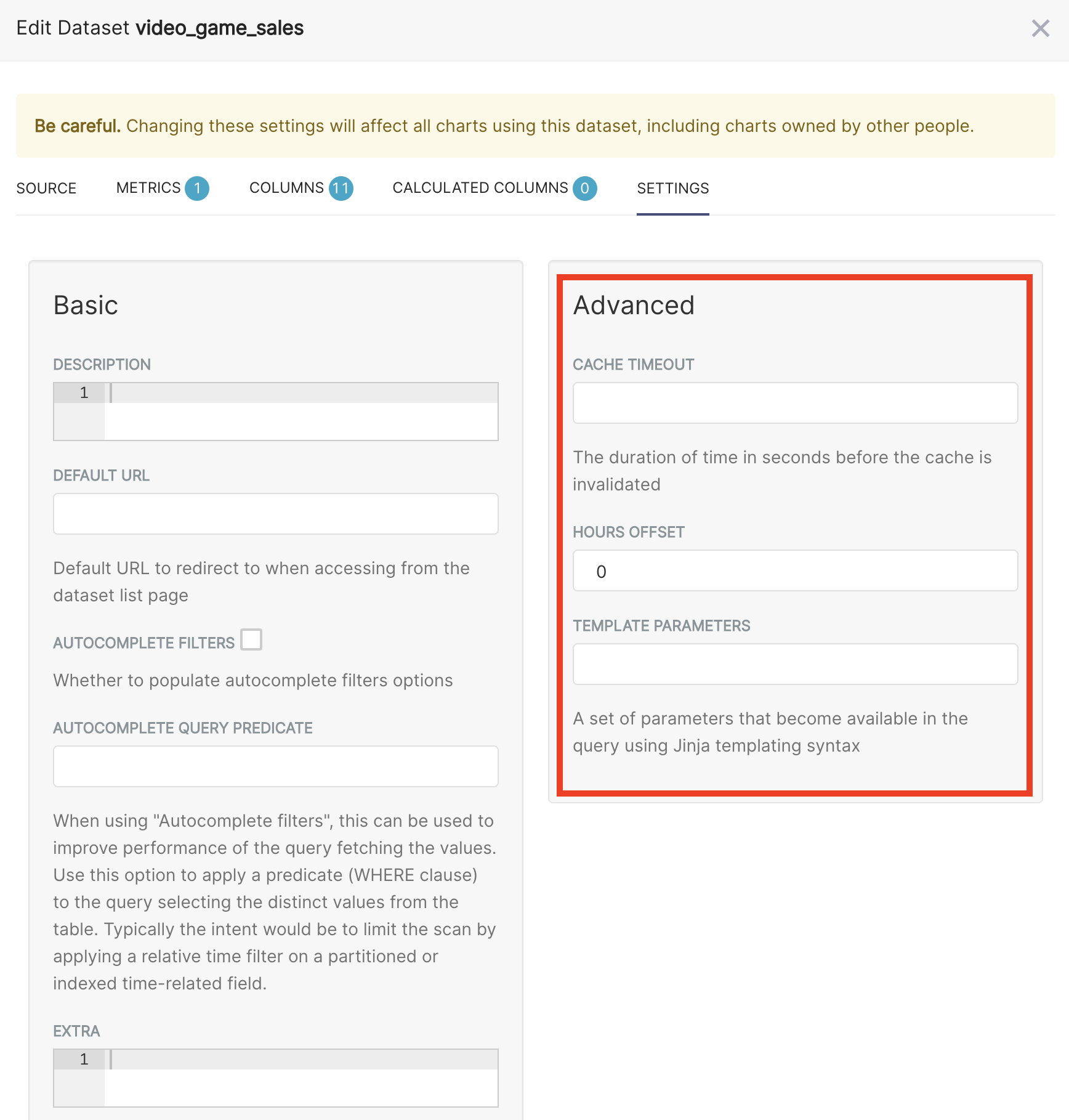
Though changing the dataset cache timeout would make the most sense for this case, the dataset cache timeout can be overridden by setting the timeout for any chart individually.
Tip 3: Use Superset's dashboard-native filters
Dashboard-native filters are a relatively new feature in Superset. Conceptually, dashboard-native filters are like chart filters, but they live at the dashboard level and can influence many charts in a single dashboard at the same time.
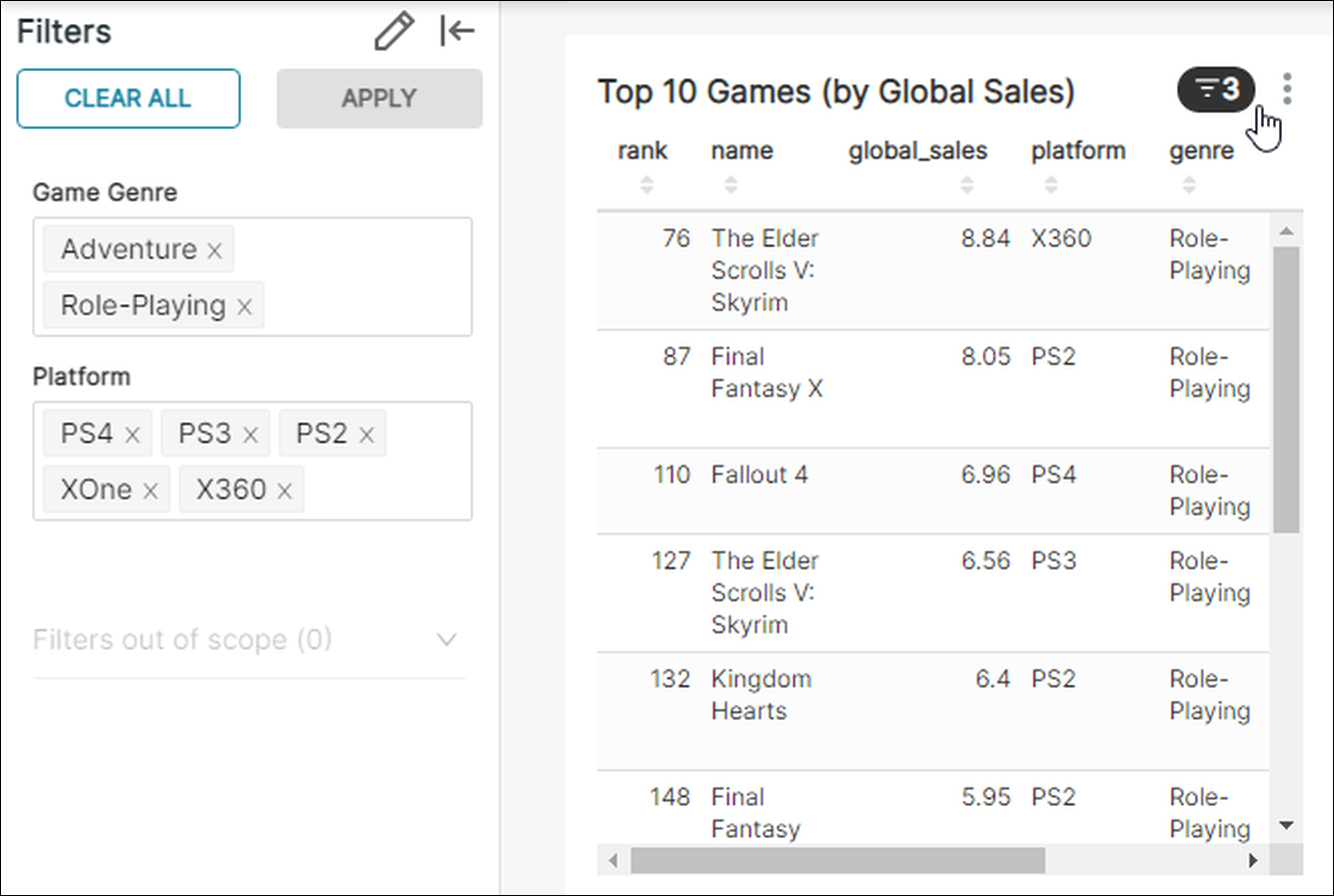
This feature is particularly useful when working with data lake engines, as data lakes often provide direct access to large quantities of lower quality data. Dashboard native filters, in turn, provide a no-code solution for cleaning and filtering data before it reaches the dashboard.
Conclusion
I have written about other data-lake engines in the past, but Dremio really brings the technical heat to back up the marketing. Facing competition from cloud vendors' own first party data lake access and management services, it is heartening to see third-party query engines built on open-source software thriving through distinguished performance.
Join us on the community Slack, visit Superset on Github and get involved!
