


Superset and Aws Athena Tutorial - Data Lake




Cloud data lakes are a common feature of modern data platforms. Today we will set up a data-lake architecture in AWS using Athena, Glue, and Superset. But first, what is a data lake, and why should your organization consider this data architecture for its needs?
The evolution of the modern data lake
The data lake is the product of a shift from monolithic, tightly-managed data warehouses built on relational databases to looser, more democratized systems where many personas have direct access to data. Notebooks, Python packages, and machine learning models often often rely on performant access to raw unstructured or semi-structured data to deliver meaningful insights.
Traditional data warehouses couple storage and compute inside relational databases, and much of the discipline of data engineering evolved around reliably getting high quality data into these systems.
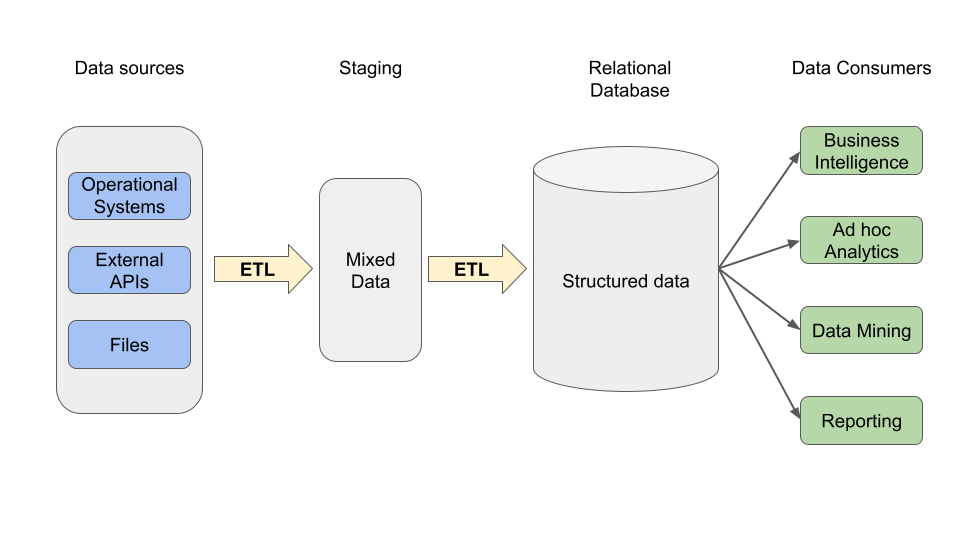
In contrast, a data lake represents a looser coupling in which storage and compute are separated. Storage is handled by low cost file-storage solutions, and compute comes in a variety of forms.
The data lake offers a number of advantages over a traditional data warehouse:
- Cloud-based object storage is cheap and highly available.
- Reduced data duplication, since all the organization's data lives in the same place.
- Separating storage from compute simplifies scaling an architecture up as analytic needs grow.
- Many SQL-speaking query engines (Presto, Trino, Athena, Drill, etc) now provide performant relational access to a mix of structured and unstructured data stored in a data lake.
- Democratized data access empowers individual stakeholders to engage with the data directly.
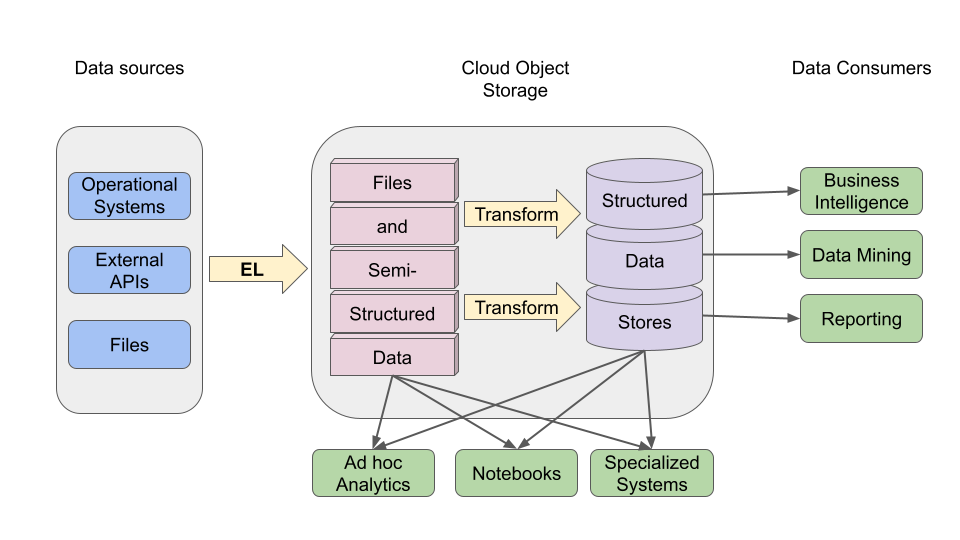
All this comes with its own challenges in the form of generally reduced performance, more complex data governance, challenges around concurrent data access, transaction handling, and the need to build and maintain structured data stores within the data lake to provide enough performance for specific analytic use-cases. Some organizations deal with these challenges by having a parallel data warehouse, or structuring one or more data warehouses inside the data lake.
In this step-by-step tutorial, we will use services provided by the AWS ecosystem to set up a data lake architecture and connect it to Apache Superset.
Step 1: Configure cloud storage and AWS Athena
Unlike a traditional data warehouse, a data lake architecture can handle semi-structured data with ease. Amazon's S3 (simple storage service) is an inexpensive option for storing large amounts of data in the cloud. The ability to query semi-structured data, JSON and Parquet formatted files for example, is particularly powerful for a number of use cases.
We will need an S3 bucket for this project, so create a new one if needed. A couple notes about using S3 with Athena:
- Note the region chosen for the S3 bucket. It can't be changed, and we will need it later.
- Athena when used with Glue as we will here, likes to have one directory per schema. This means that files with different schemas should each be deposited in their own subdirectories in the S3 bucket.
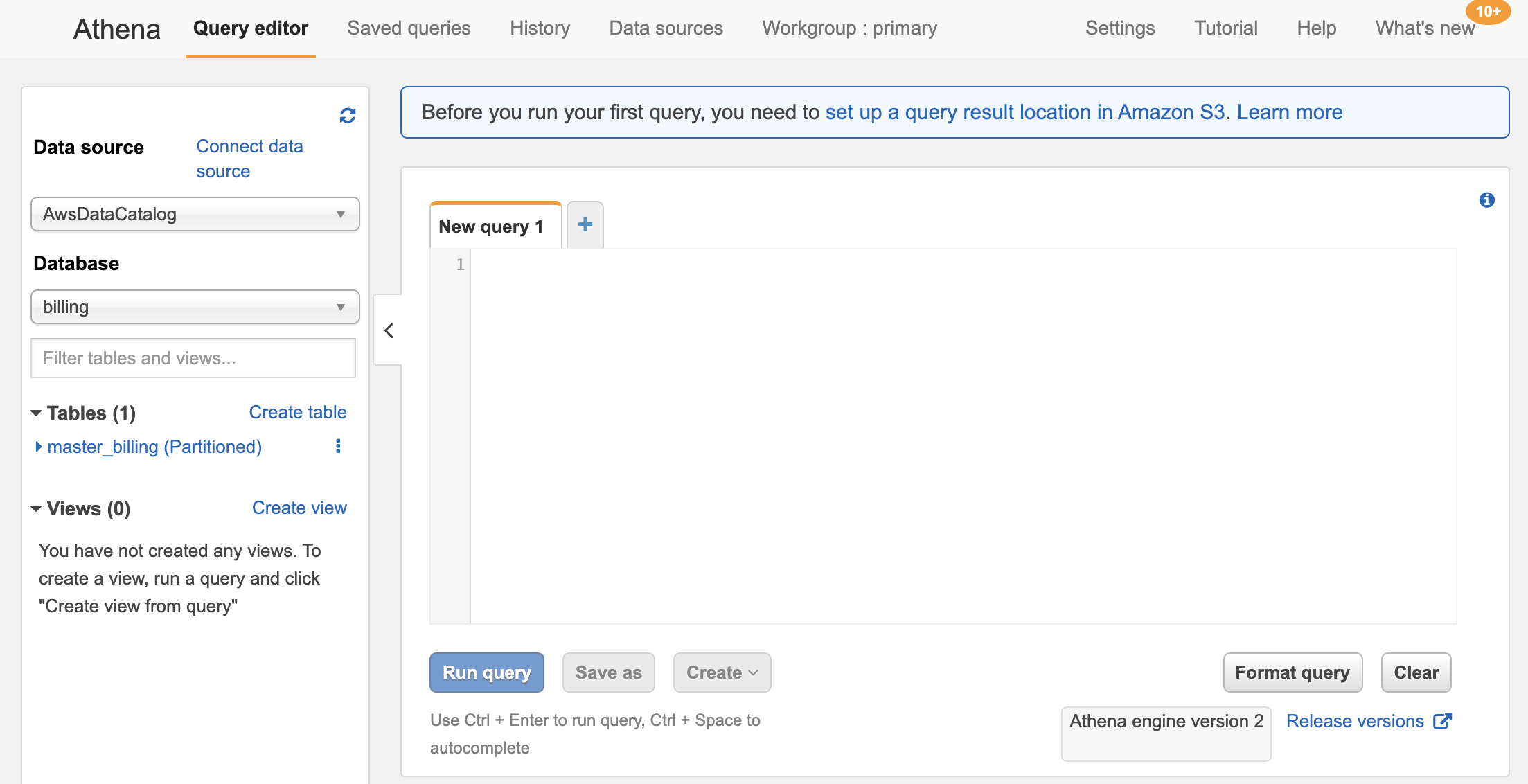
From the Athena home screen we can execute SQL queries and browse saved queries, but first we need to associate the data in our data lake to Athena. Select the Data sources tab at the top, then click the Connect new datasource button.
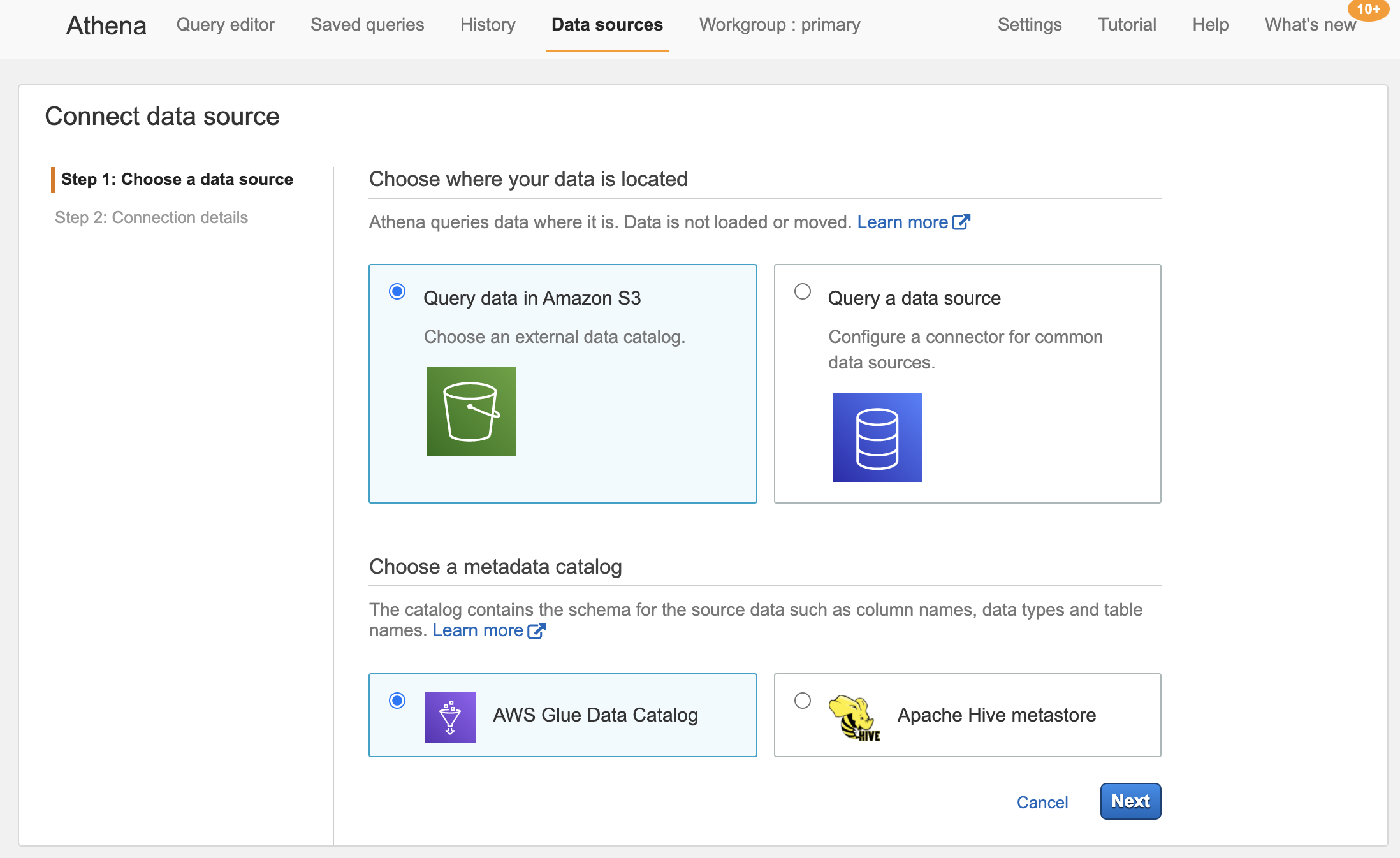
When setting up a new crawler, we first need to select the data-source. In our case we are configuring Glue to crawl directories in an S3 bucket. Athena can connect to many SQL speaking datasources and query files in S3. It relies on a metadata catalog, which can be the AWS Glue metadata store or an existing Hive metadata store. Select query data in Amazon S3 and AWS Glue data catalog.
Step 2: Configure AWS Glue
Tables in Athena can be created manually using CREATE EXTERNAL TABLE queries, but this option has some serious drawbacks. Manually defining and updating the schema for each desired table is a hassle and requires manual updates when the directory structure or data evolves. The better option is to use AWS Glue to automatically define and update the file to table relationships.
Select Create a crawler in AWS Glue.
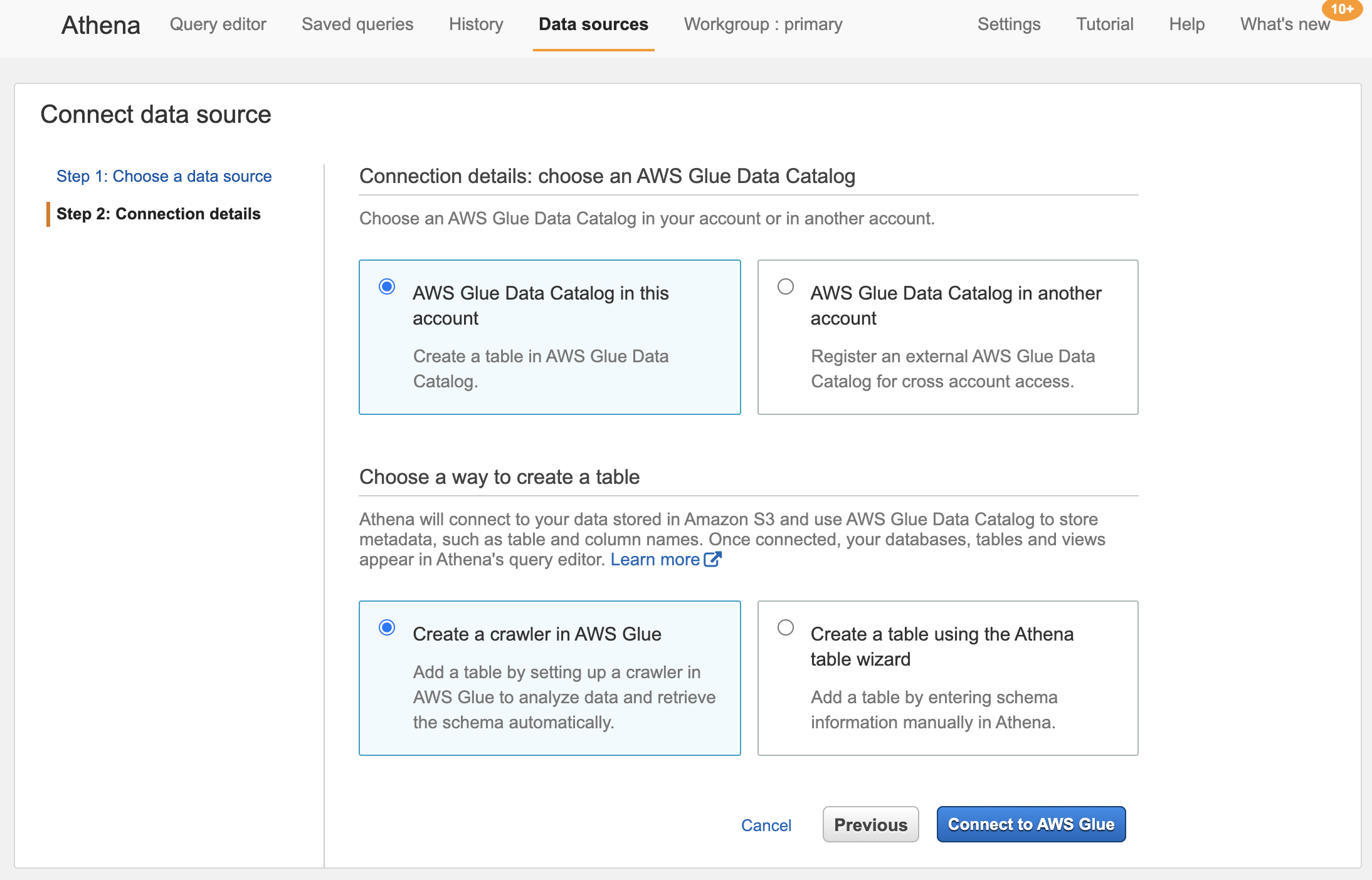
A Glue crawler populates the Glue metadata catalog with tables derived from files in one or more datastores (in our case, an S3 bucket). The crawler can run on a schedule, or run in response to changes in the source datastores, a very powerful feature.
If connecting to an external S3 bucket, a connection must first be configured with the credentials and other details for that connection. For our purposes in this tutorial, we just need to provide the URI to the S3 directory where the data is located.
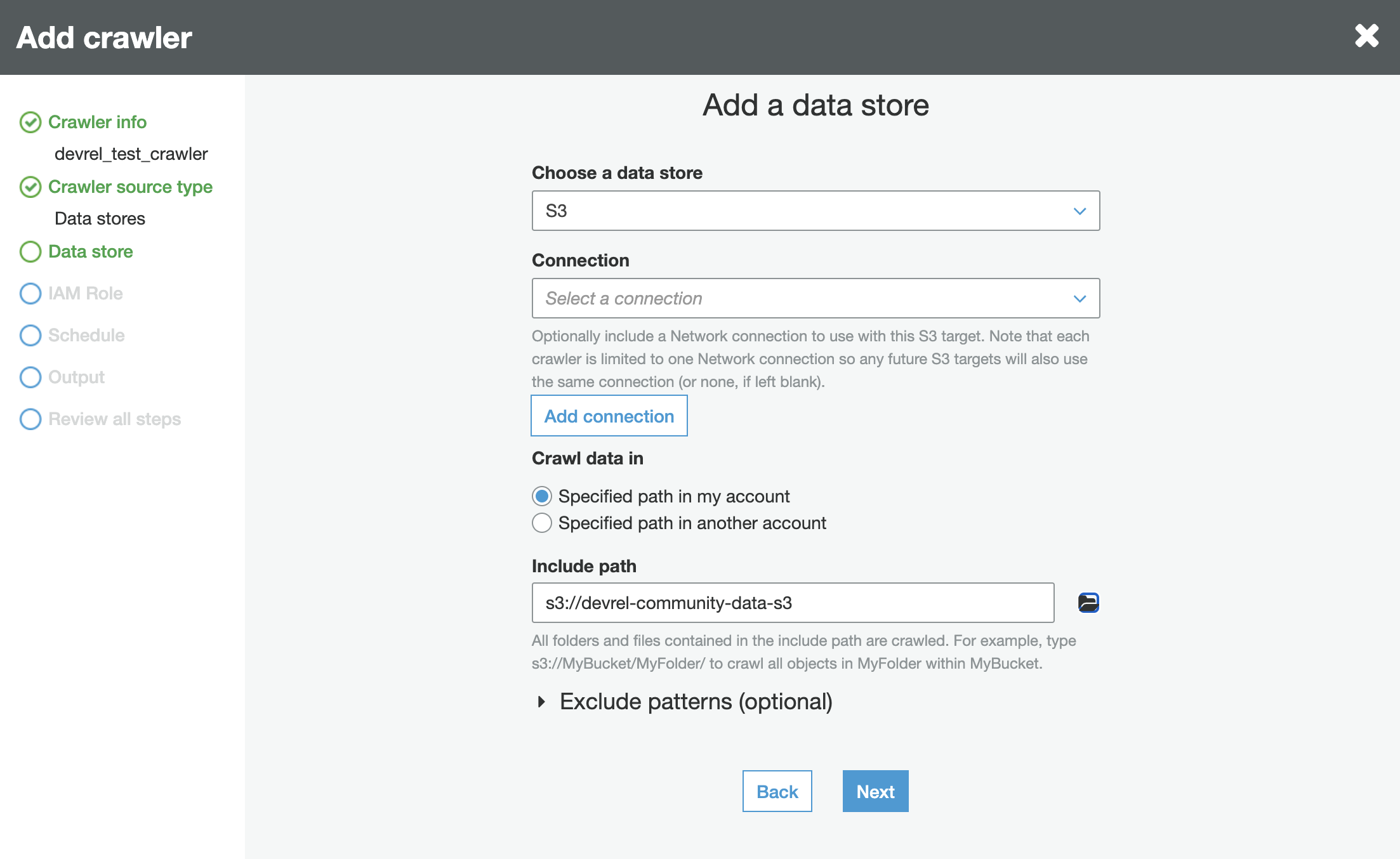
An IAM role with access to Athena and the S3 data must be associated with the crawler.
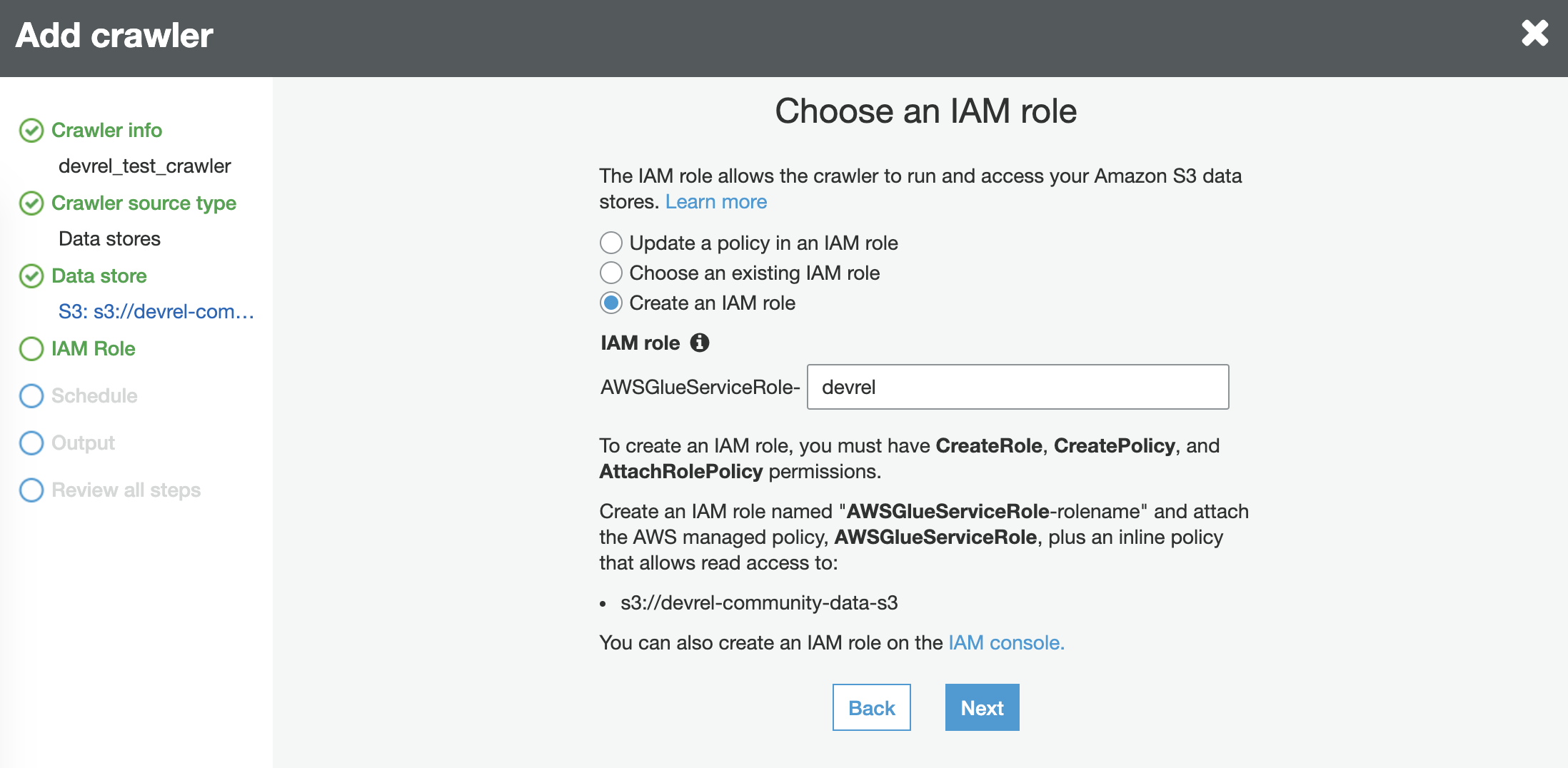
We can run the crawler on a schedule or on demand. The later option allows the crawler to be used with Glue Triggers, enabling the crawler to respond to changes in watched directories.
Lastly, we need to select what database to add the tables to. Select the name given to the Athena database created in step 1.
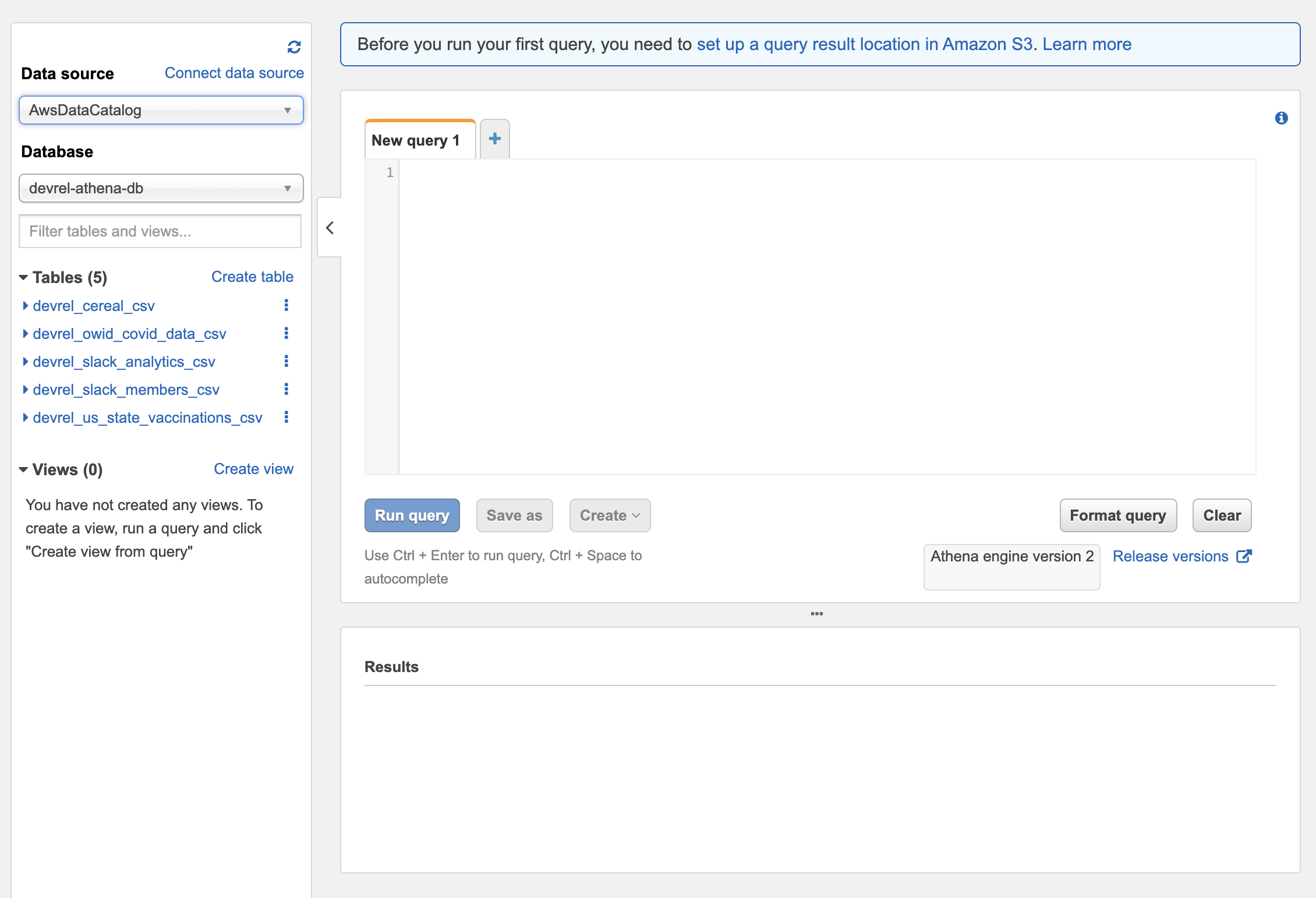
Now run the crawler. Any files crawled by Glue will have a table created in Athena. SQL queries can now be run against those tables.
Step 3: Connect Athena to Apache Superset
Now that Athena is set up and Glue has crawled the data, all that remains is to connect Athena to Superset.
The only challenge here is getting the connection string for Athena right. I have provided a color coded example string below. The sections are:
- Red: SQL Alchemy driver identifier. There are actually two SQL Alchemy drivers for Athena, and
awsathena+restis the recommended one. - Orange: An IAM access key Id generated from an IAM user with the role we created in step 2. An STS token can also be used in place of an IAM access key if desired.
- Yellow: The secret access key associated with the access key id in yellow. Yours won't be XXXXX...
- Green: The URI of the Athena DB created in step 1. The region, given here as
us-west-2, will need to match with the region of the S3 bucket created in step 1. - Cyan: The URI of the S3 directory where the Athena db is located. Notably, this is not the directory where the data itself is located. Rather, it is the directory chosen in Step 2
- Blue: The name of the workgroup associated with the Athena DB. Workgroups can be created and modified using the Workgroup:... navigation bar on the top of the Athena console.
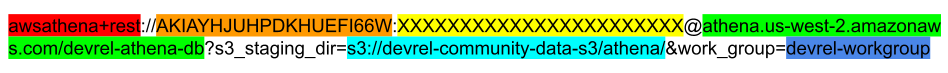
Once the connection test passes indicating Athena has been added as a database, we simply add a new dataset in Superset corresponding to each table.
The data is now queryable in Superset. Since Athena is pay by the query, and the underlying storage is slow, Superset's default query caching behavior is a major boon that will save both time and money when used with a data lake architecture. For teams wanting a managed solution, Preset Cloud supports Athena out of the box with enterprise-grade caching and security.
Step 4: Visualize the data lake!
Something great about Superset is that it treats all SQL-speaking datasources in a consistent way. Now that our architecture is set up and the data is in place, adding tables from Athena is identical to adding tables from any other source.
In Superset, mouse over the data drop down on the top bar and click Datasets. Click the + DATASET button in the top right corner. For the data-source, choose the name of the Athena connection created in Step 3. For schema, choose the name of the Athena database created in Step 2. Then select the table of interest.
Once the table has been added as a datasource, it available in explore mode for chart and dashboard creation. Click the dataset name to enter explore mode with the table we just added. Now it's a matter of picking a chart type that displays what we want to see!
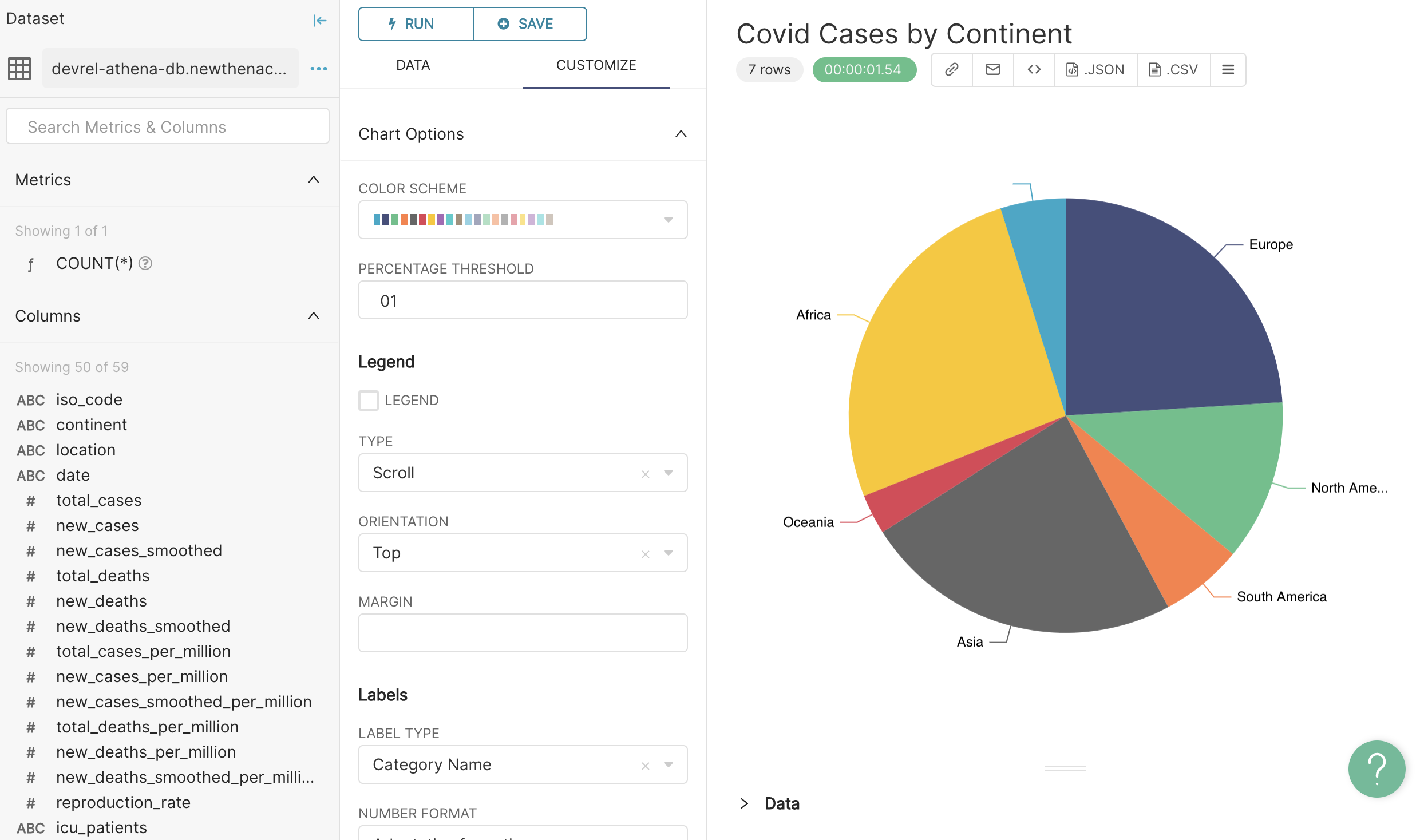
If Glue Triggers have been set up, making newly added data from our data lake available in Superset is as simple as adding the files to a directory in S3 being watched by Glue, then adding the tables in Superset as we did above. Since we did not configure Glue Triggers in this tutorial, remember to re-run the crawler once new data has been added to S3, or configure the crawler to run on a schedule. Once set up, this architecture takes us from data to dashboard with no additional data engineering required!
Conclusion
With the analytic needs of organizations changing, cloud service offerings have continued to mature, and big data has only gotten bigger. The low costs and scaleability of cloud file storage have driven a new model in which data is extracted and loaded into inexpensive cloud storage in open formats like JSON and Parquet. From there, a variety of data stakeholders can access the data directly with transformations and pipelines optimized for their purposes.
As for the future of the data lake, I have seen the term "data lakehouse" thrown around in data engineering circles over the last year. Definitions seem to vary, but I choose to view the data lakehouse as more of a conceptual goalpost where the defining features of traditional data warehouses are made available on top of a data lake without compounding the drawbacks. It will be interesting to see how these architectures evolve to meet the changing demands of future data work.
Join us on the community slack, visit Superset on Github, and get involved!
Related Reading
- Real-Time vs Time-Series Databases — Understanding different database types for analytics
- Querying Federated Data with Trino — Another way to query across data sources
- Connecting Superset to BigQuery — Cloud data warehouse tutorial
- Building a Database Connector for Superset — How database connectors work under the hood
