


Choosing the Best Open Source Integration Framework




At Preset, I'm focused on better understanding how healthy communities grow around popular open-source projects as they evolve. To reach a better quantitative understanding of these communities, I first need to regularly ingest data from many different sources into a platform I'm building. Writing custom scripts that extract data out of SaaS tools through API integration from scratch is often a huge pitfall. While it may seem easy to write a small python script to simply get the information you need, things get challenging as your needs and APIs evolve, and doing efficient incremental loads can be tricky.
Rather than write extract, load, and transform (ELT) scripts for each data source, I wanted to see if any open-source projects out there could make this digital transformation task easier. Coincidentally, a number of folks have reached out to me from the Superset community looking for help understanding the differences between two up-and-coming open-source integration tools we have written about in the past (here and here), both of which I'm very excited about: Airbyte and Meltano. I configured, tested, and compared both of these tools for use in my data ingestion project, and I have some thoughts.
I was looking for an open-source software that could help tackle these things:
- Extract and load: Get data from a combination of APIs and data files into a staging environment, incrementally where possible.
- Normalize and transform: Automatically build a normalized schema, or reliably map the data to a user-defined schema. Deal with messy input data. Run tests against the data and apply transformations.
- Orchestrate: Schedule and execute ELT jobs in a scalable fashion with control over the details.
- Pipeline management and 'Data-ops': Easily save and restore pipelines, track changes in version control, integrate with other tools in my data stack.
While no single open-source project yet meets all these needs, Airbyte and Meltano both cover enough to be a potentially huge time saver. Data-integration tools like these are a still-emerging part of the modern data stack designed to make data ingestion easier by consolidating the core functionality of an ingestion layer into a single tool and providing low to no-code ways of manipulating it. There are closed-source SaaS offerings like Fivetran that fit most of my wishlist, but they all require a budget and reduce the portability of your data pipelines by locking them into a closed ecosystem. There are certainly valid reasons to make that trade-off, not the least of which is top notch support for a long list of high-quality connectors. In the spirit of Preset's values, my intention is instead to build a reusable solution on freely available open-source platforms that can be used as reference for organizations looking to collect and analyze big data within their own communities.
A quick disclaimer before I continue. Both Airbyte and Meltano are new open source frameworks and are poised to improve dramatically in the coming years. Both have a lot of potential, but they vary significantly in philosophy and implementation. In this post, I'll explore the broad-stroke differences as they stand now and what I like about each!
Meltano
Meltano was born from the needs of the GitLab data team around 2018, with an ambitious vision to bring all parts of the data lifecycle together under one tool. The concept is to use a plugin oriented architecture with many plugin types that can be easily connected to enable modular end-to-end data pipelines under source control. After completing a functional v1 proof of concept in 2019, the team recognized the vision was too broad without a healthy open-source plugin ecosystem and decided to refocus their efforts short-term on a subset of the vision: data engineers looking for an open-source data integration platform. Beyond simply extracting and loading data, the flexible plugin architecture allows Meltano to work with popular data tools like Apache Airflow and DBT, bringing orchestration, data transformation, and validation under the umbrella as well.
To talk about data ingestion using Meltano, I should first mention the open-source Singer ecosystem. For those who have not worked with Singer taps and targets, these individually maintained open-source connectors enable data to be extracted and loaded according to the Singer spec. The Singer ecosystem is notable for the sheer number of supported datasources and destinations (over one-hundred at the time of writing), and whole companies have been built partially on that ecosystem.
Meltano has doubled down on the Singer ecosystem by defining 'extractor' and 'loader' type plugins as a python virtual environment wrapped around a Singer tap or target. The upside to this approach is immediate availability of the many data connectors already available as part of the Singer ecosystem. Meltano's extractor plugins are as configurable as the underlying tap, and will allow you to choose what datastreams to sync for each datasource.
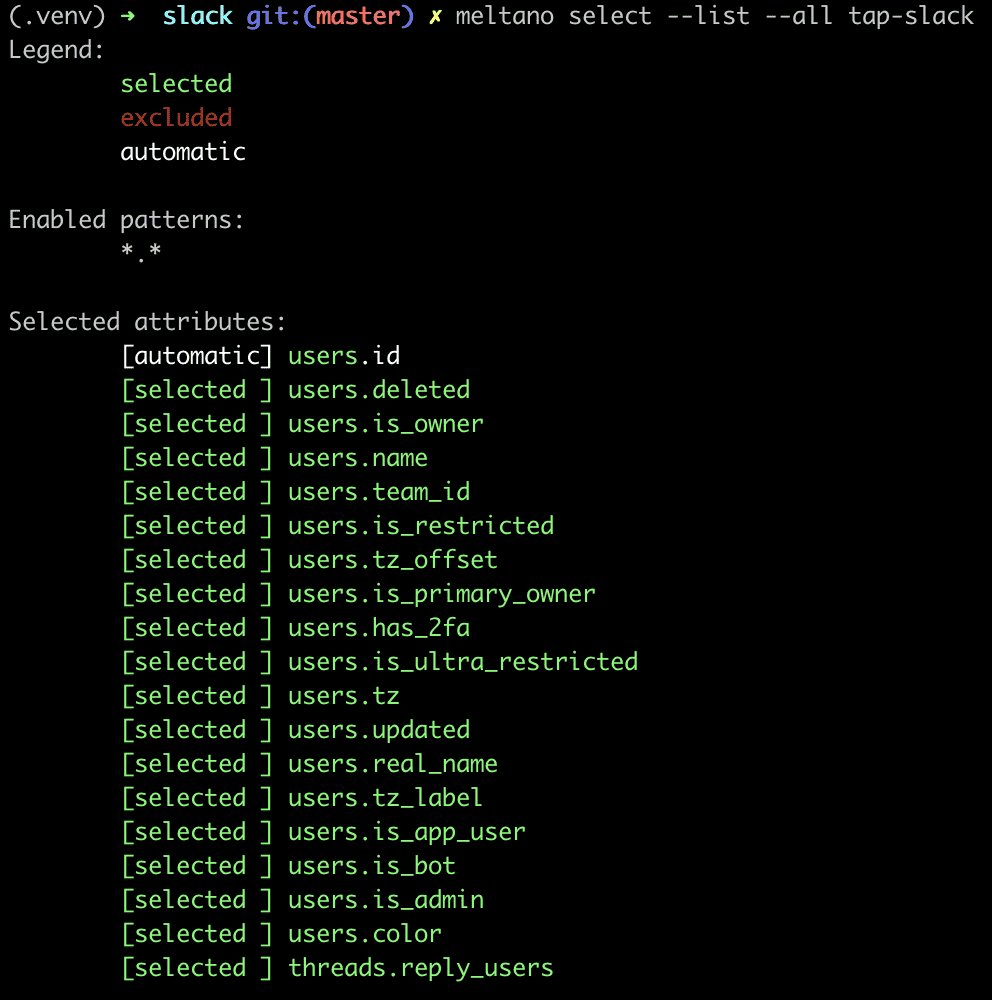
The downside of reliance on Singer is that Meltano inherits the problems of the Singer ecosystem as well. Each Singer tap or target is its own open-source project, which means some are better maintained than others. I had to invest time into troubleshooting dependency and environment related issues to get all my taps and targets working.
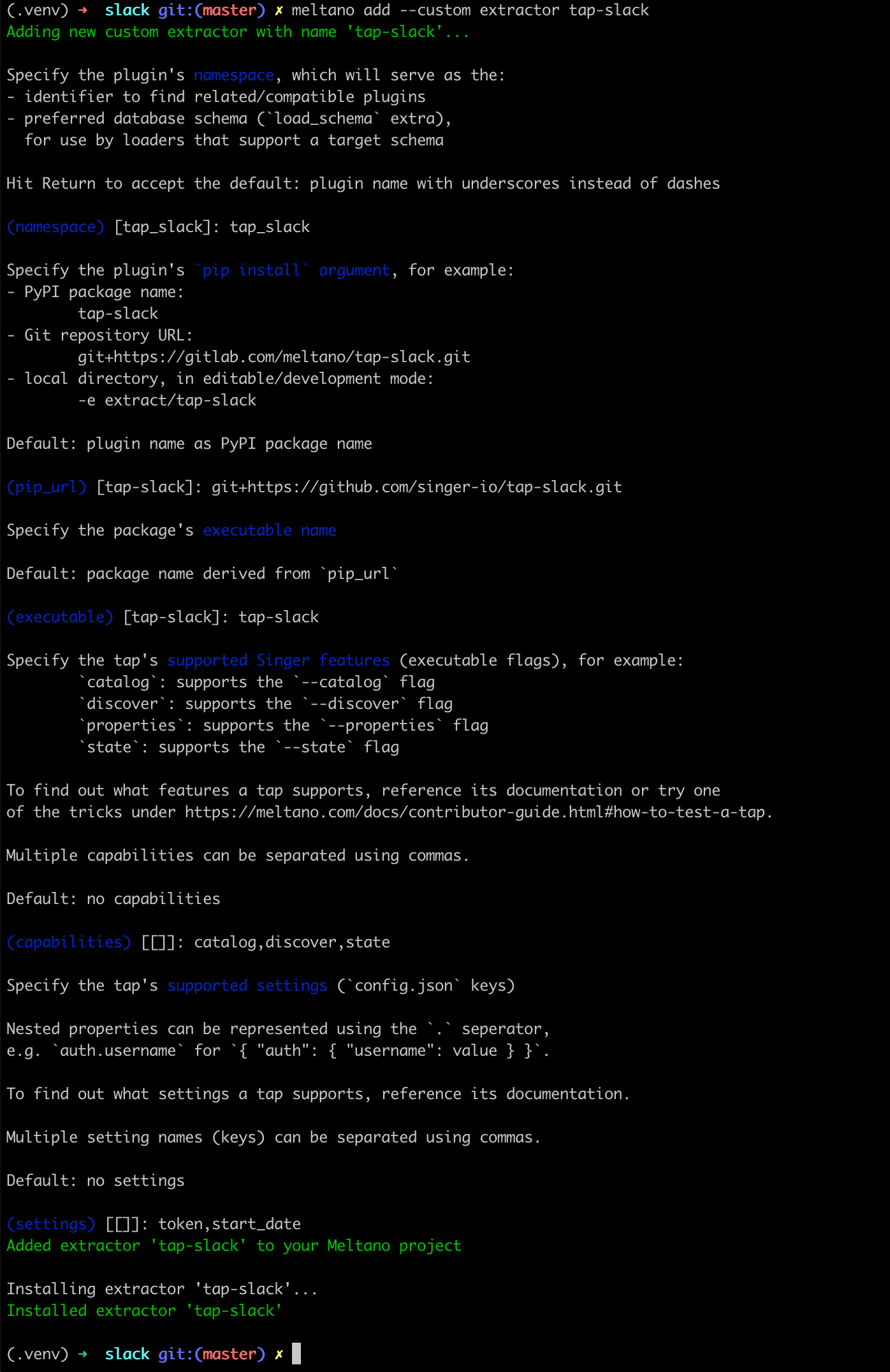
Meltano is a CLI-first tool, and is designed to enable pipelines to be quickly configured through that interface (see this recent blog). For example, setting up a new Slack API datasource is as easy as:
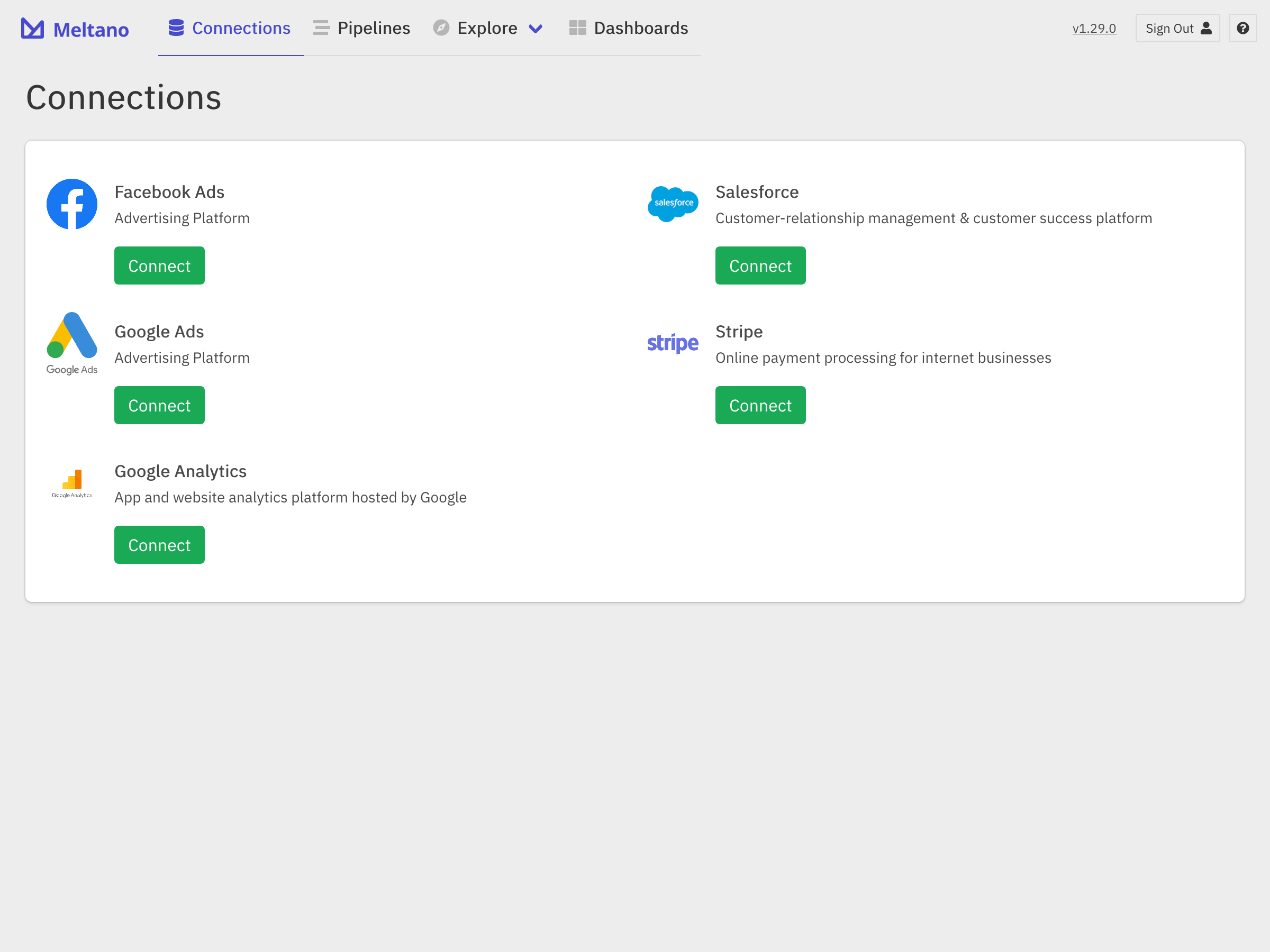
The web GUI has also been making strides and surfaces some of the functionality available in the CLI.
For scheduling ELT jobs and managing pipelines, Meltano supports Apache Airflow as an 'orchestrator' plugin type, which is great given how commonly Airflow appears in existing data stacks. The Meltano web GUI also surfaces some of the functionality of a connected Airflow deployment, which could enable non-engineers to do some basic management of their own ELT pipelines. Meltano even stretches to cover integrated analytics as well, and provides some reporting functionality through the web GUI.
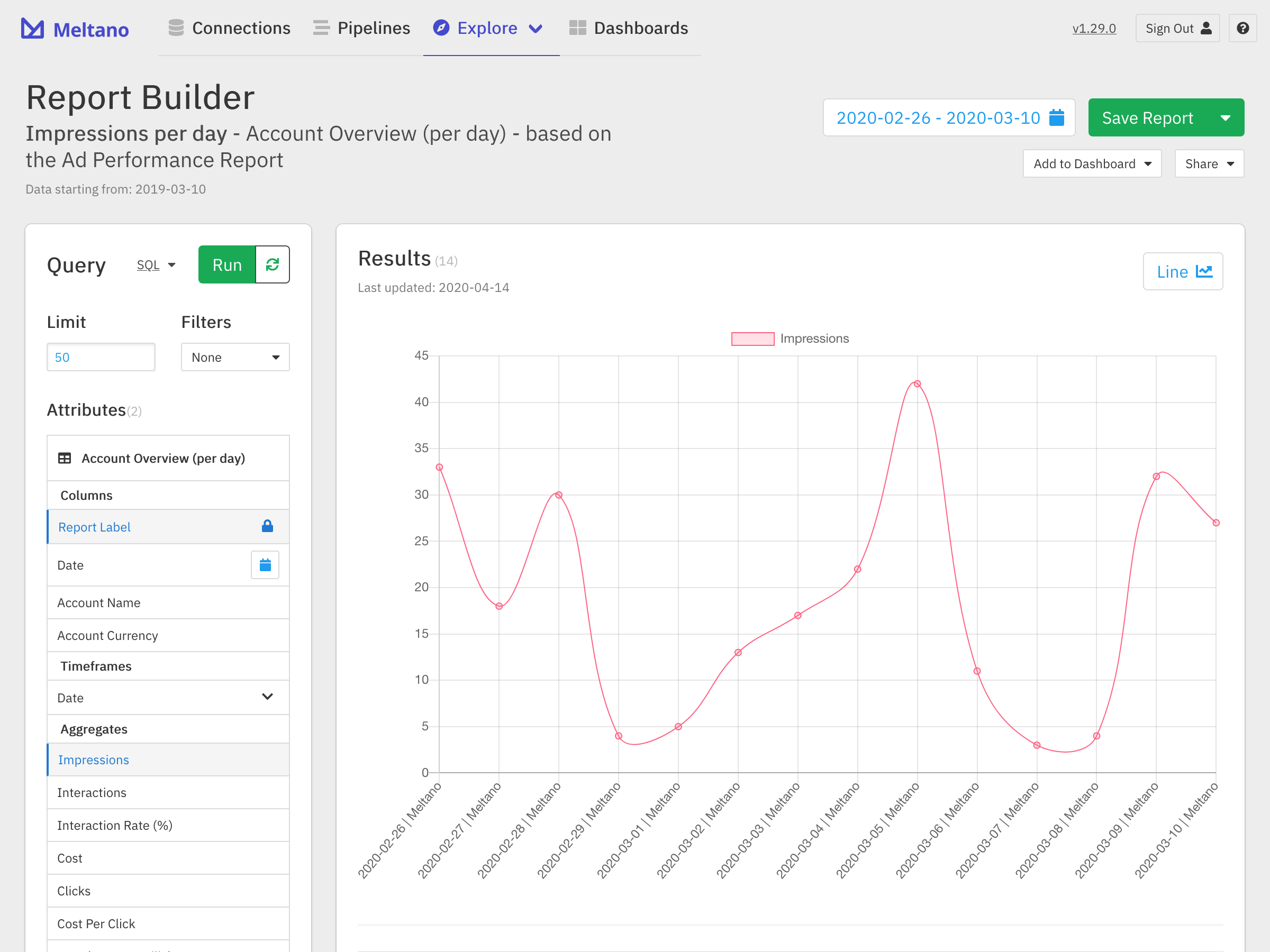
In theory Meltano could even have Apache Superset as a 'analyzer' plugin type, perhaps an enterprising member of the Superset community would want to have a look.
What makes Meltano great?
Meltano may be the preferred tool for data engineers looking for an ELT overlay to bring many parts of their data platform under management together. In particular, it will appeal to folks with existing deployments of other popular data-ops tools like Airflow and DBT. Overall, Meltano brings a lot together and offers key features like:
- CLI-first interface ideal for data engineers
- Access to the many taps and targets in the Singer ecosystem out of the box
- Broader integration with existing data tools, including Airflow and DBT
- Handles transformation of data at ingestion with DBT models
- A competent and improving web GUI for pipeline creation and monitoring
- Tight integration with source-control
Airbyte
Airbyte begin as an effort to build a marketing data tool by engineers formerly from data connectivity platform LiveRamp. In June 2020, the team responded to changes in the market brought by the COVID-19 pandemic by shifting focus from marketing data management to general data integration. The first public version of Airbyte was made available as an open-source tool that fall.
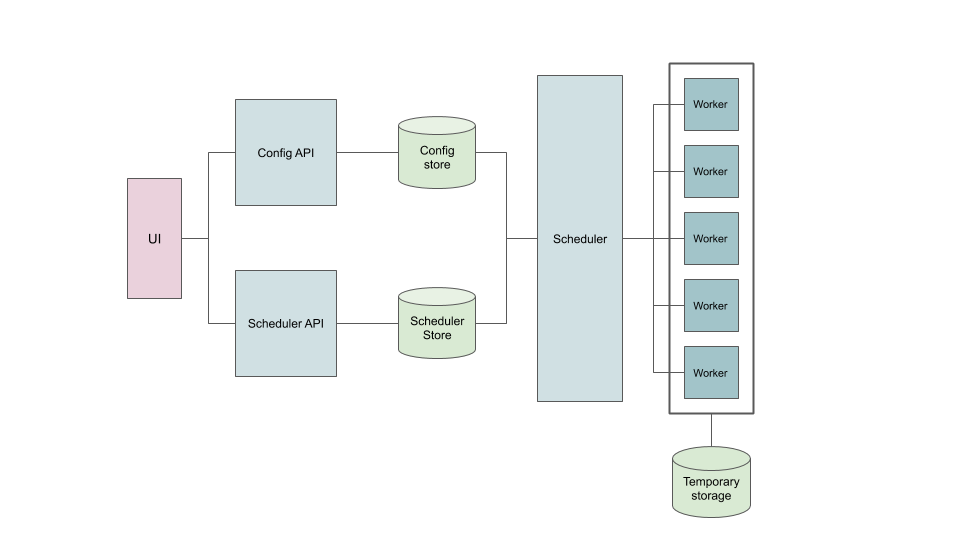
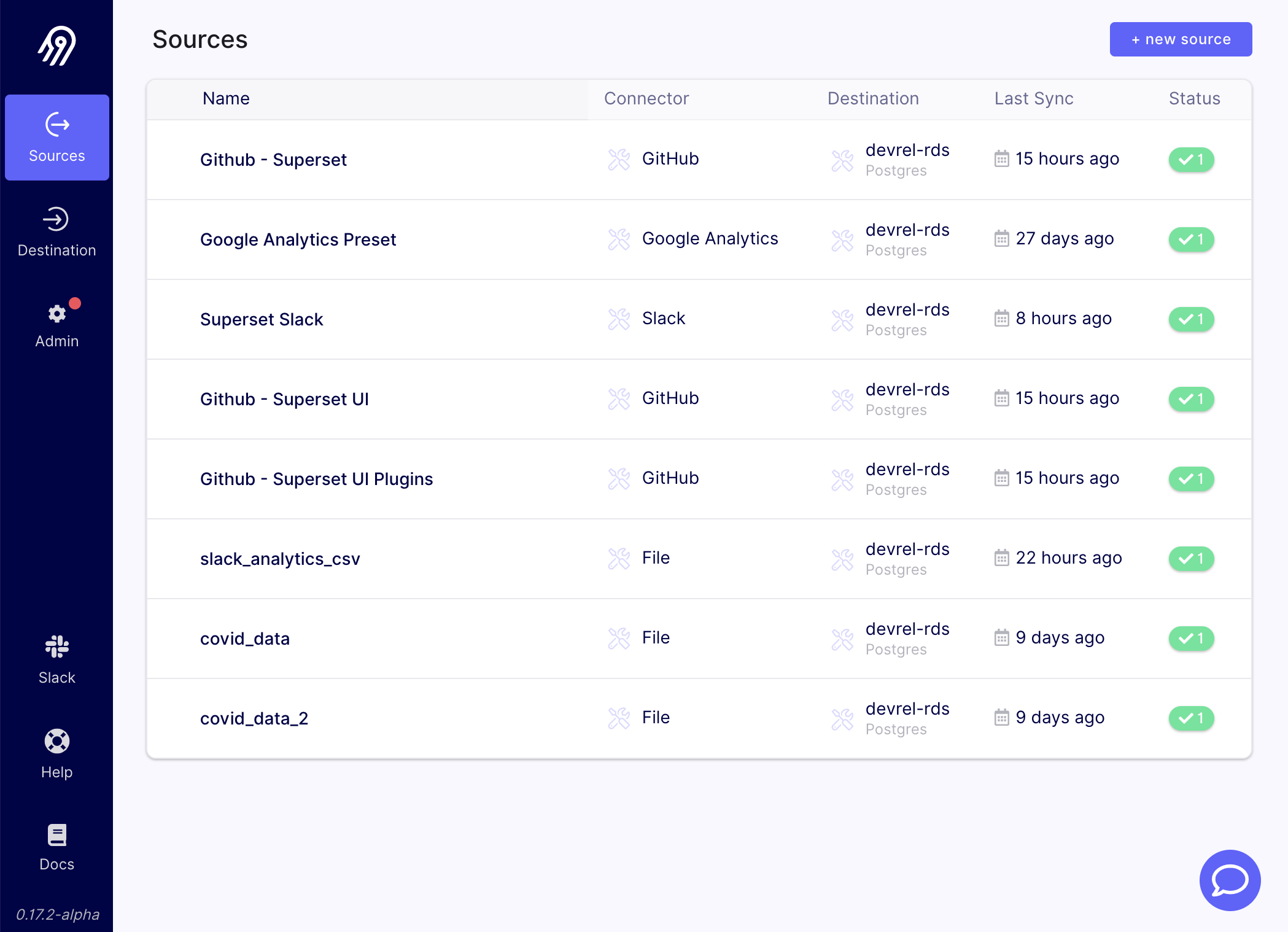
This approach has many advantages for getting ELT data pipelines up and running fast, as dependency and configuration issues can be avoided through the containerized architecture. As a result, Airbyte is great for creating extract and load pipelines with minimal time investment out of the box.
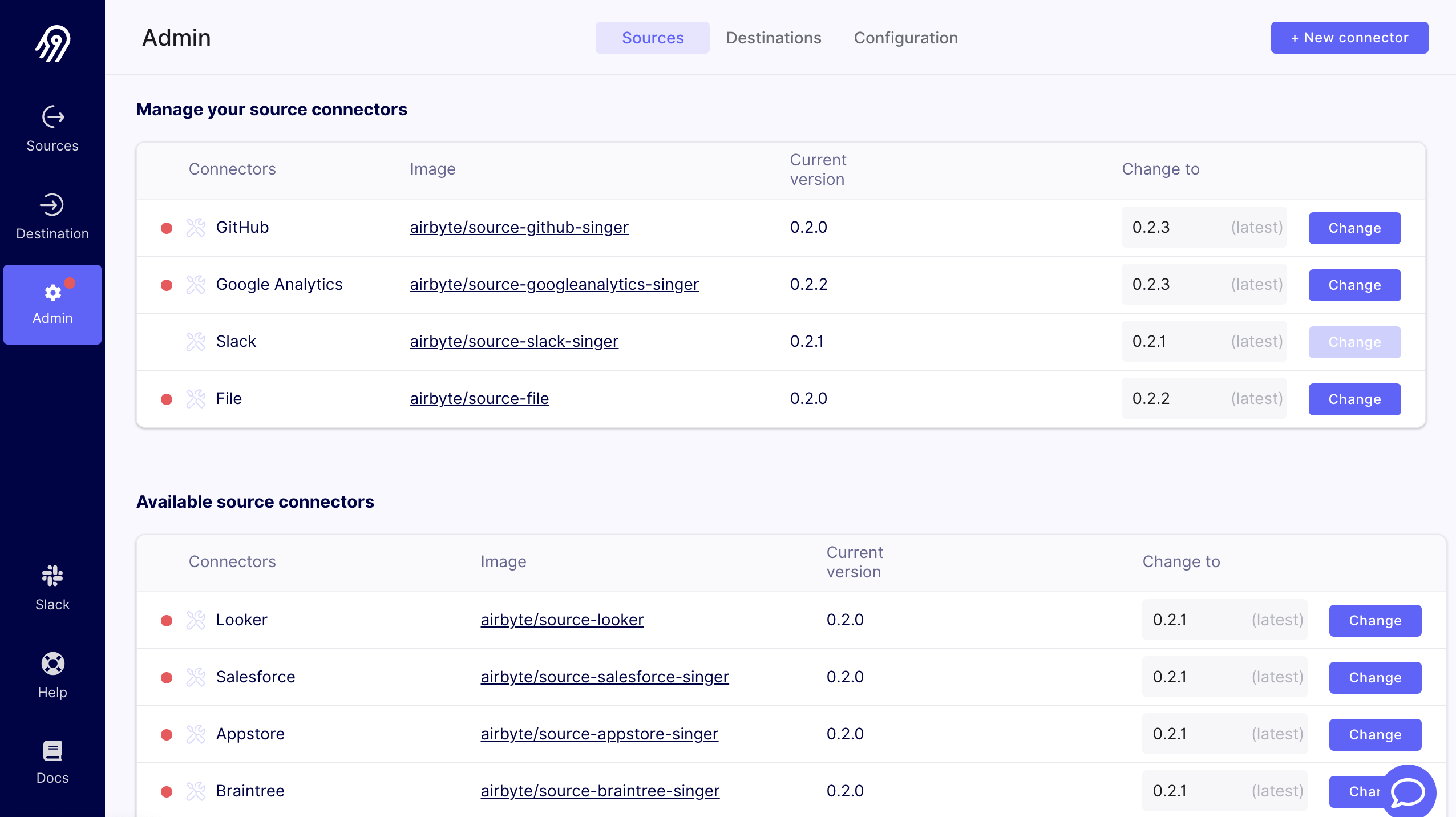
Updating existing data-connectors is similarly easy, and can be done through the web GUI.
The downsides of full containerization are the inherent performance costs and the added steps when modifying or building new connectors. The Airbyte team seems to be focused on building and maintaining their own containerized connectors rather than relying solely on the Singer ecosystem, which is a welcome move. That being said, maintaining a long list of data connectors as a small team is a real challenge, and a number of Airbyte connectors are only partially healthy at the time of writing.
Airbyte provides its own orchestration through the web GUI and API, with ELT jobs being executed by Airbyte's own integrated workers. The job scheduling and monitoring options in the web GUI are unfortunately a bit limited. As with extraction and loading, for orchestration the emphasis is on quick set up and ease of use. I am going to try hooking the Airbyte API up to Airflow to achieve more granular control in future.
What makes Airbyte great
In general, I found Airbyte provides a tight, integrated experience for building fast extract and load pipelines. Its containerized connectors work well out of the box with almost no configuration. It has a shallow learning curve and enables full configuration of data sources and targets through a capable web GUI, with more features offered to power users through the API. I view Airbyte as the ideal tool for data scientists, analysts, software developers, and others doing ad-hoc data engineering or pipeline prototyping for these reasons:
- Web GUI provides easy access to core pipelining functionality with a shallow learning curve
- Fully containerized connectors provide huge flexibility in implementation
- API offers programmatic control not otherwise available through the GUI
- Automatically generates a mostly normalized data model for source APIs
- Integrated workers support concurrency and will provide scaling performance as connectors become more sophisticated in the future
- Set-up really couldn't be smoother
Wrap up
Both projects have laid a strong foundation, and I anticipate each will evolve in interesting ways over the coming years. Because of the complexity involved in maintaining a large list of high quality data connectors, both projects will certainly rely on cultivating a healthy open-source community. I believe how easy each team makes it to build and deploy data connectors in their spec will be a defining feature of their success.
I chose Airbyte for the ingestion layer in my own project because the extract and load functionality worked out of the box with minimal time invested. Airbyte's decision to focus on its data connectors combined with its containerized architecture give it an edge in ease of use, even if it supports fewer data sources at the time of writing and makes me go elsewhere for data transformation and other ingestion related needs.
I have not yet been able to compare both of these tools at scale, and that is one area I would like to explore more in the near future. It will also be interesting to see how well each fits into other projects going on at Preset. I hope this was a helpful review for those interested in open-source data integration tools. Join us on the community slack, visit Superset on Github, and get involved!
