


Unlocking the Power of Virtual Datasets in Apache Superset







Virtual Datasets are a powerful feature in Apache Superset, enabling flexibility and accelerating time-to-dashboard. However, they can impact performance, database load, and costs. Here's how to get the most out of them.
What’s a Virtual Dataset?
Virtual Datasets in Superset are defined as SQL queries within the platform, allowing users to create datasets without modifying the underlying database schema.
- Definition: Created within Superset using SQL queries.
SELECT
-- exposing only relevant / useful columns out of the 3 tables
A.amount,
A.quantity,
C.store_name,
C.store_region,
C.store_country,
B.customer_name,
-- Simple renaming for clarity / consistancy
B.cust_id AS customer_id,
FROM sales AS A
-- a simple hash join
LEFT JOIN customers AS B ON A.customer_key = B.customer_key
-- another simple hash join
LEFT JOIN store AS C ON A.store_key = C.store_key
-- no GROUP BY here!
-- no ORDER BY here!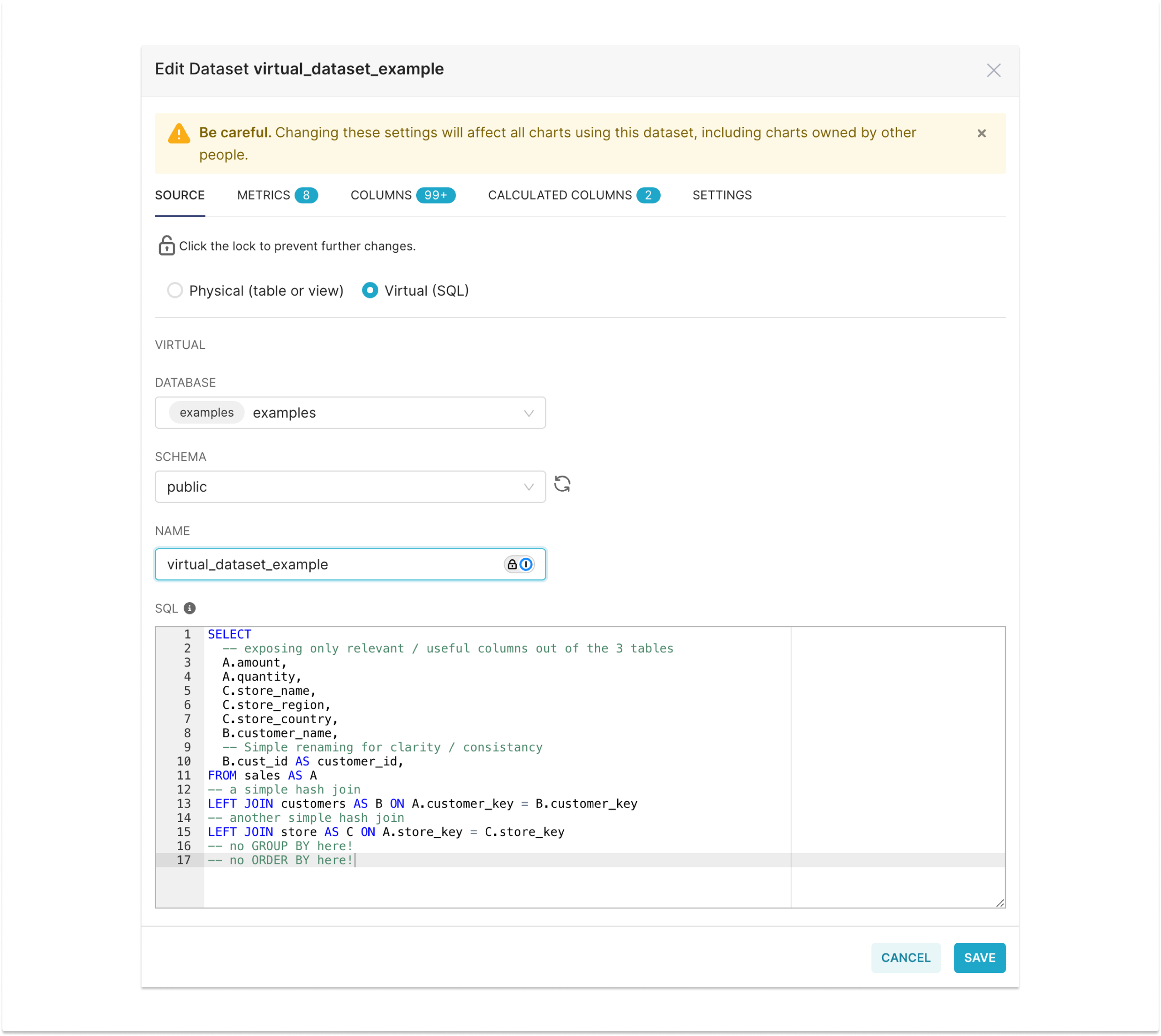
- Usage: Queried like any other dataset, with your Virtual Dataset’s SQL expanded as a subquery
SELECT
store_name,
COUNT(*) AS transations,
FROM (
------------------------------------------------------------
-- THIS IS THE SQL FROM YOUR VIRTUAL DATASET
------------------------------------------------------------
SELECT
A.amount,
A.quantity,
C.store_name,
C.store_region,
C.store_country,
B.customer_name,
B.cust_id AS customer_id,
FROM sales AS A
LEFT JOIN customers AS B ON A.customer_key = B.customer_key
LEFT JOIN store AS C ON A.store_key = C.store_key
------------------------------------------------------------
) AS virtual_dataset
GROUP BY 1- SQL Lab use case: Ideal for exploring queries and iterating quickly. When querying in SQL Lab, you can pivot into visualizing and exploring your query results in Superset’s Chart Builder. Whether your result set is simple and targeted to generate a quick visualization, or a larger dataset that you want to use to assemble a collection of charts into a cohesive dashboard, this feature allows you to pivot from the SQL IDE and into Explore quickly.
Alternatives to Virtual Dataset
To better understand Virtual Datasets, it helps to compare it to its alternatives
- Physical database tables — Obvious, perhaps, but these are fully denormalized, physical tables. To serve Superset and its one-dataset-per-chart approach, this means pushing denormalization to its extreme point. Note here the need for some sort of ETL system to handle computation in order to keep physical tables up-to-date.
- Database views are a construct offered by your database, giving a representation (essentially the representation of a query) against other "physical" tables or views. These are very similar to Virtual Datasets and differ in that their definitions are managed by the database as opposed to by Superset itself.
- Materialized views - Some databases support materialized views. Effectively they are physical tables defined as views, where the database engine provides some guarantees around materializing the view definition based on user-provided settings.
Dataset-Centric Visualization
As a quick reminder from The Case for Dataset-Centric Visualization, a well-constructed Virtual Dataset should offer a rich set of dimensions and metrics, forming a comprehensive playground for exploration. This enables users to filter on various dimensions and perform "slice and dice" operations, pivoting from one dimension to the next, drilling into details, and comparing metrics. This approach allows for dynamic and flexible data analysis, empowering users to explore and visualize data in a multi-dimensional space, uncovering deeper insights and driving better decision-making.
Generally, a useful, reusable Virtual Dataset should not be overly fitted to create a single chart, and not too complex/sparse, where metrics and dimensions are unrelated and loosely coupled.
Differences and Tradeoffs Compared to Traditional Database Views
Views and Virtual Datasets are more similar than they are different. The key distinction is that views are managed in your database, while Virtual Datasets are handled by Superset. Here are some of the key differences:
- Source Control: Typically defined close to where data transformations are managed (e.g., Airflow, dbt), allowing for version control and validation but limiting fast iteration.
- Power of Jinja Templates: Superset allows the use of Jinja macros, bringing Python's power to SQL authoring on-the-fly. This facilitates more dynamic and responsive query building compared to traditional views.
- Superset-managed: Not all users are familiar with source control like
gitor file-system-based tools like dbt, and some just prefer working on a fast-paced UI like Superset - allowing for faster and more familiar iteration. Superset allows you to simply edit your SQL in the Dataset editor modal. - Certification: Superset offers a feature around “stamping” assets as “certified” along with a tooltip that can be used to share more metadata. Superset users can filter on certified datasets, and get information about who/when/why this is certified.
The Case for Superset-managed Virtual Datasets:
- Fast Iteration and Visualization: Enables rapid development and testing of queries and visualizations.
- UI over CLI: While data engineers and technically-inclined users may prefer a source control workflow, many SQL-savvy analysts are more comfortable with a UI, which offers a more intuitive and accessible alternative.
- Portability to Source Control: As the logic and transformations mature and require more structured governance or performance stability, they can be transitioned into a source control-oriented workflow for better management and rigor.
The Case for Source Control
Complex data transformations, as they settle - including summarization or denormalization - are best managed in source control (e.g. git). Benefits include:
- Validation Workflows: Code review processes ensure accuracy and reliability. Code reviews help catch errors, improve code quality, and promote knowledge sharing within the team.
- Powerful Search and Navigation: Tools like
gitand GitHub offer robust search and code navigation features, allowing users to easily find specific code, track changes, and explore version history. - Versioning: Maintain history and accountability, enabling point-in-time recovery and audit trails.
- Continuous Integration, Testing and Automation: Integrate continuous testing for robust data pipelines, including:
- Data Quality Assertions: Using tools like
dbt testto enforce data quality rules. - SQL Code Linting: Tools like
sqlfluffensure SQL code adheres to best practices. - Deployment Logic: Automate deployment steps to ensure consistent and reliable releases.
- Data Quality Assertions: Using tools like
What to Avoid in Virtual Datasets
Certain database operations can be costly and should be avoided in Virtual Datasets:
- GROUP BY: As demonstrated earlier, Superset runs a query against your Virtual Dataset as a subquery and typically uses a GROUP BY in the outer (Superset-generated) layer. This means that not only is your GROUP BY redundant, it can also create confusion around double-aggregating some metrics, especially around non-additive metrics like
COUNT(DISTINCT)and averages. Also, GROUP BY is a blocking operation, meaning it must process its entire input, and the operation completed before the first row can be output to the next operator. For these reasons, we do not recommend using GROUP BY in Virtual Datasets. - ORDER BY: Costly and often redundant; ordering will be performed by Superset if needed, either in the outer-query or even, at times, by the Superset frontend itself. Like GROUP BY, ORDER BY is also a costly breakpoint operation for your database to perform.
- Window Functions: Expensive, complex, and often require careful consideration due to the complexity around the fact that Superset runs a query on top of your Virtual Dataset definition.
GROUP BY, is probably the most important takeaway from this blog post. Avoid the performance penalty AND the confusion that comes from having multiple phases of aggregation.
Reasonable Operations in Virtual Datasets
Virtual Datasets are best used for:
-
Hash joins are efficient for joining smaller dimension tables to fact tables. These joins typically "stream" nicely and are efficient.
-
Ephemeral/Ad Hoc Business Logic: In the data lifecycle, not all assets require a high amount of rigor. Often, data engineers and data analysts are doing some discovery on datasets that are actively maturing. During that phase, it can be reasonable to keep things where they can be iterated on quickly and eventually make their way to source control. For example some useful
CASE WHENexpression that lives in your Virtual Dataset may graduate and find its way as part of your ETL. Some examples of simple/common business logic:- Simple Renaming/Labeling: Convenient for minor adjustments.
- Simple Business Logic: E.g.,
CASE WHENfor grouping values. - Quick
REGEXP_EXTRACT: Categorize data on the fly. - Bracketing: Create an
age_bracketcolumn out of a numericalagecolumn. - Simple formatting, such as links or basic HTML within a data table.
While we prefer these operations to live in source control, iterating in a fast-paced tool like Superset, and into a Virtual Dataset, can be a great way to experiment around the requirements of the simple transformations that actually need to be applied. Some of these categorization operations require visualization to be defined. Once a Virtual Dataset settles, it’s possible to raise the level of rigor and bring it into source control. As this happens, it can be straightforward to point your Virtual Dataset onto a physical table or database view that’s been built based on the evolved Virtual Dataset.
Considerations Around Materializing Your Virtual Datasets
- Cost: Identify and optimize expensive queries to reduce costs.
- Performance: Exploring data or rendering a dashboard is slow, and users want a more responsive/interactive dataset.
- Partitioning: Large data scans are expensive, and partition-pruning is the easiest way to significantly limit scans. Applying a good partition scheme (typically daily on the main time dimension used to filter queries) and enforcing partition predicates can greatly improve query performance. Note that while Superset will apply predicates to the "outer query", the predicate should result in proper partition-pruning (where only the target partitions are scanned by the database engine) if your database optimizer is decent in most or all cases.
- Large Joins: If you have a billion-row
invoicetable joining to a 5 billion-rowinvoice_linetable, resulting in large joins, you may want to denormalize these tables into one. Alternatively, use an efficient layout that allows for efficient joins, such as bucketed-sorted-merge-joins. This approach can help manage and optimize large-scale joins. - Materialize Business Logic: Move validated, consensus-approved logic into physical tables or views.
- Data Warehousing Best Practices: Employ star schemas and other efficient designs, more on this in the next section.
Virtual Datasets on Dimensional Models
If you use dimensional modeling techniques in your data warehouse, Virtual Datasets serve as a flexible and dynamic abstraction layer on top, providing an extra virtual layer that appears more denormalized. This setup offers numerous benefits, making data exploration, visualization and dashboarding more intuitive.
Building on Dimensional Models
Dimensional modeling structures data to be intuitive for business users and efficient for querying. A star schema, a common dimensional model, consists of a central fact table connected to multiple dimension tables. Here are some of the benefits of using dimensional modeling as a foundation to exposing virtually denormalized datasets.
- Efficiency and Performance: Star schemas simplify complex queries and enhance performance, allowing for efficient filtering, grouping, and aggregation of data. Indexing and partitioning strategies applied to fact tables further optimize query performance.
- Intuitive design: the straightforward structure of star schemas makes it accessible for business users to create and interpret queries, facilitating better data exploration and reporting.
- Slowly Changing Dimensions (SCDs): Manage changes to dimension data over time, providing historical context and allowing accurate trend analysis. SCDs enable querying of dimensional attributes at the time of the transaction or the latest attributes. For example, virtual datasets or views on top star schemas enable efficient SCD type-1 without having to fully reprocess large amounts of data.
Adding a Layer of Abstraction with Virtual Datasets
Virtual Datasets in Superset can effectively build on and enhance the principles of dimensional modeling by adding an extra layer of abstraction:
- Seamless Integration: Virtual Datasets sit nicely on top of star schemas, using the optimized structure for efficient data retrieval and providing an intuitive layer for users.
- Enhanced flexibility: by creating Virtual Datasets, you add a flexible, more denormalized layer on top of the dimensional model. This allows for dynamic exploration and analysis without altering the underlying database schema.
- Combining Business Logic: Include simple business logic and transformations directly in the SQL queries of Virtual Datasets. This allows for rapid prototyping and validation of logic before transitioning it to the upstream transformation layer or source control.
- Efficient Querying: Use efficient joins, such as hash joins, to connect fact and dimension tables within Virtual Datasets. Avoid costly operations like
GROUP BYandORDER BYto ensure better performance.
Prepping for Source Control
When working with Virtual Datasets, it’s crucial to clearly document your intentions and logic. This practice not only helps you but also aids other team members in understanding and eventually integrating your work into source control for daily job execution.
To achieve this, it is encouraged to weave detailed comments and annotations into your SQL queries. These comments should explain the purpose and context of your logic, making it easier for others to understand and build upon your work. For example:
- Clarify Intentions: Use comments to explain why certain transformations or calculations are done.
- Upstream Logic: Indicate parts of the SQL that should eventually be moved to the upstream transformation layer for better management and performance.
These annotations and comments make your SQL queries self-explanatory, ensuring that anyone who takes over or collaborates on the project can easily grasp the logic and rationale behind your Virtual Datasets. This practice fosters a smoother transition of your work into source control, improving the overall efficiency and clarity of your data processes.
In Summary
Virtual Datasets in Superset (or Preset) offer flexibility and rapid iteration but must be used judiciously to avoid performance and cost issues. By understanding their capabilities and limitations, you can put Virtual Datasets to work for faster, more efficient data exploration and visualization.
