


dbt Transformation: Transforming GitHub Data




Transforming GitHub Data Using dbt
At Preset, we've been working on building an internal community tracker based on open source data tools to better understand the Superset community (as well as other open source communities). Upon completion, we hope to open source this work for anyone to use.
This post is part 3 in our ongoing series of posts:
- In part 1, we discussed why we deiced to start with Airbyte for data ingestion from Github, Slack, etc.
- In part 2, we provided a guided tutorial on configuring data sources for extraction in Airbyte
In this blog, our overarching goal is to get data out of GitHub API into organized, entity focused tables in a data warehouse. For this, we will use dbt a popular open-source tool for documenting, transforming, and validating data loaded into a SQL-speaking data warehouse.
dbt is a data transformation and quality framework focused on in-warehouse, SQL based data transformations. The tool has gained a significant following in recent years and provides a set of conceptual best-practices to guide in-warehouse data development. Operations applied to the data are defined as dbt models, and dbt creates an execution plan for the project as a directed acyclic graph (DAG) of models.
I recently blogged about putting together a simple open-source ingestion layer using the Airbyte framework. Once the raw data from our open-source communities of interest are in the landing (or "base") schema in our data warehouse, there are some tasks that must be carried out before it will be ready for consumption by analytic end-users:
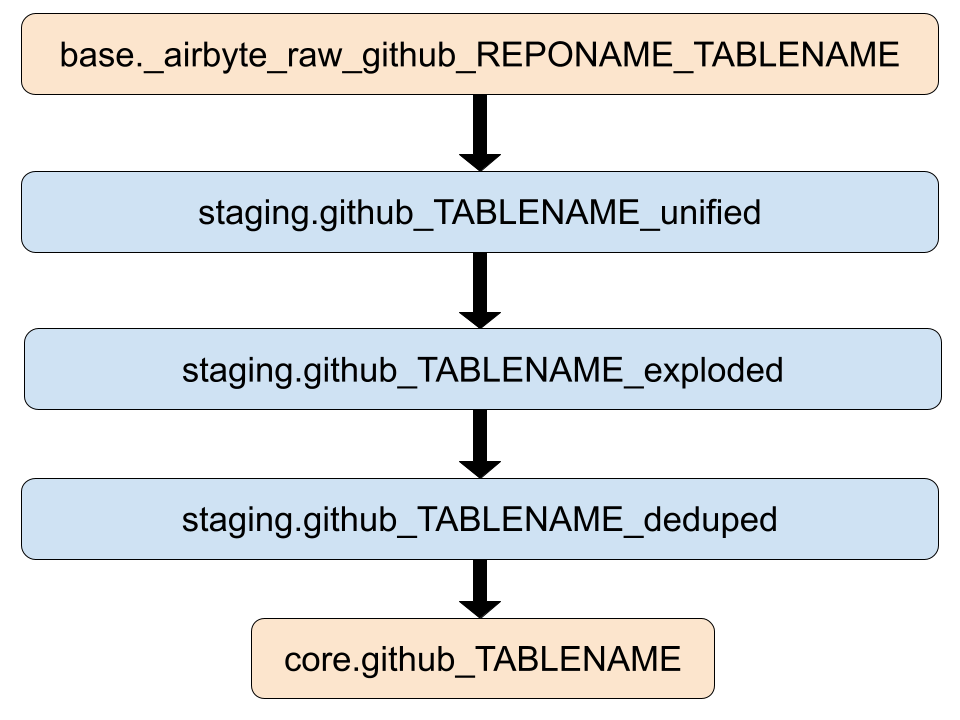
- Unify the data from all the repositories of interest into tables to simplify the DAG and streamline downstream transformations
- Explode the raw json payload in each record into a useful set of columns
- Build composite keys and de-duplicate the data
- Finally, build a set of mostly normalized entity-focused tables (pull requests, commits, comments, etc) for analytic users to consume
We have 3 schemas ('datasets' in BiqQuery lingo), with data flowing as follows:
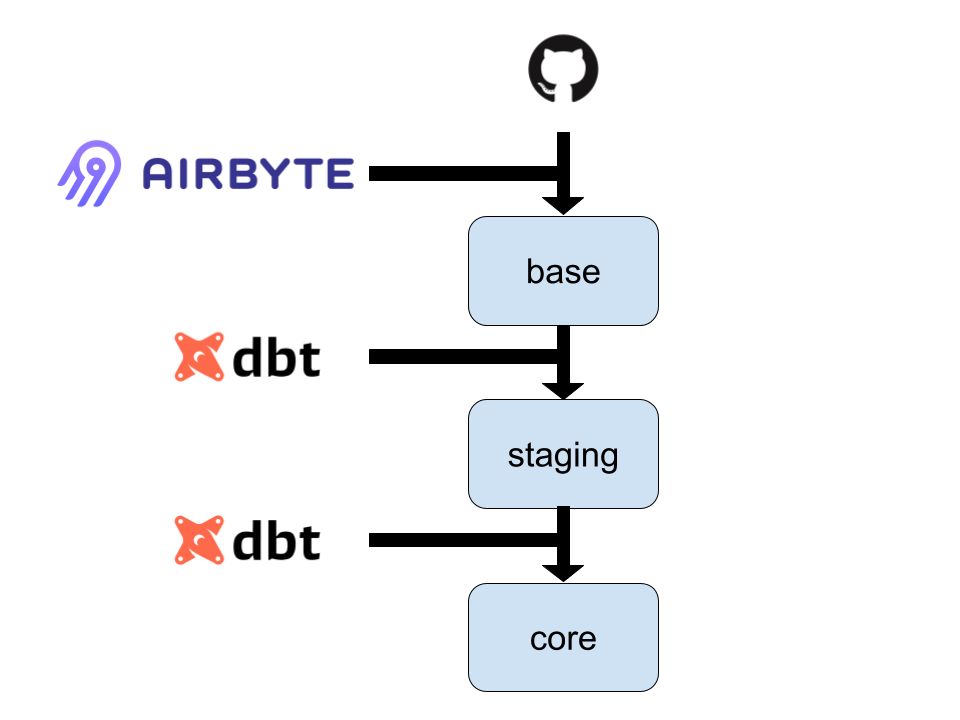
When DBT applies the transformations to the data, the DAG it builds will look something like this for each datasource:
Let's begin.
Unifying Data
Here we take advantage of dbt's powerful macro and Jinja templating functionality to define a macro that will unify the set of tables for an arbitrary list of GitHub repositories. First, we define a set of variables in the top level dbt_project.yml file.
vars:
day_counts: [7, 14, 28, 90]
github_repos:
- repo: apache/superset
table_str: superset
- repo: fishtown-analytics/dbt
table_str: dbt
- repo: airbytehq/airbyte
table_str: airbyteOther variables of interest, such as a set of integers to represent different number of days to window the data over, can also be defined here for easy modification (and to keep the actual dbt models as DRY) as possible.
We now can define a macro in the macros folder of our dbt project that puts this list of repos into a procedurally generated SQL query. That could look something like this:
{% macro airbyte_github_union_all_raw(table_suffix) %}
{%- for repo in var('github_repos') %}
SELECT
'{{ repo.repo}}' AS repo_name, *
FROM base._airbyte_raw_github_{{ repo.table_str }}_{{ table_suffix }}
{%- if not loop.last %}
UNION ALL
{%- endif -%}
{%- endfor -%}
{% endmacro %}Here, we are looping through all the elements of the github_repos list defined in dbt_project.yml, and applying UNION ALL to the data found in tables following the Jinja template.
As discussed in the previous blogs, we are applying transformations to the raw JSON blobs created by Airbyte to avoid potential issues with evolution in Airbyte's "basic normalized" schema. We therefore are targeting the _airbyte_raw_ tables created in the base schema.
Explode the JSON blobs
Now that the GitHub tables are unified from all the repos we are tracking, the next step is to explode the JSON blobs into a number of properly typed columns. While what data you will be interested in extracting might vary, your transformation might look something like this (in BigQuery's SQL syntax):
SELECT
json_extract_scalar(A._airbyte_data, '$.repository') AS repository,
json_extract_scalar(A._airbyte_data, '$.url') AS url,
json_extract_scalar(A._airbyte_data, '$.id') AS id,
json_extract_scalar(A._airbyte_data, '$.html_url') AS html_url,
json_extract_scalar(A._airbyte_data, '$.diff_url') AS diff_url,
json_extract_scalar(A._airbyte_data, '$.patch_url') AS patch_url,
json_extract_scalar(A._airbyte_data, '$.number') AS pr_number,
json_extract_scalar(A._airbyte_data, '$.state') AS state,
json_extract_scalar(A._airbyte_data, '$.draft') AS draft,
json_extract_scalar(A._airbyte_data, '$.locked') AS locked,
json_extract_scalar(A._airbyte_data, '$.title') AS title,
json_extract_scalar(A._airbyte_data, '$.body') AS body,
CAST(json_extract_scalar(A._airbyte_data, '$.created_at') AS TIMESTAMP) AS created_dt,
CAST(json_extract_scalar(A._airbyte_data, '$.updated_at') AS TIMESTAMP) AS updated_dt,
CAST(json_extract_scalar(A._airbyte_data, '$.closed_at') AS TIMESTAMP) AS closed_dt,
CAST(json_extract_scalar(A._airbyte_data, '$.merged_at') AS TIMESTAMP) AS merged_dt,
json_extract_scalar(A._airbyte_data, '$.merge_commit_sha') AS merge_commit_sha,
json_extract_scalar(A._airbyte_data, '$.head.sha') AS head_sha,
json_extract_scalar(A._airbyte_data, '$.head.ref') AS head_ref,
json_extract_scalar(A._airbyte_data, '$.head.label') AS head_label,
json_extract_scalar(A._airbyte_data, '$.head.user_id') AS head_user_id,
json_extract_scalar(A._airbyte_data, '$.head.repo_id') AS head_repo_id,
json_extract_scalar(A._airbyte_data, '$.base.sha') AS base_sha,
json_extract_scalar(A._airbyte_data, '$.base.ref') AS base_ref,
json_extract_scalar(A._airbyte_data, '$.base.label') AS base_label,
json_extract_scalar(A._airbyte_data, '$.base.user_id') AS base_user_id,
json_extract_scalar(A._airbyte_data, '$.base.repo_id') AS base_repo_id,
json_extract_scalar(A._airbyte_data, '$.author_association') AS author_association,
json_extract_scalar(A._airbyte_data, '$.auto_merge') AS auto_merge,
json_extract_scalar(A._airbyte_data, '$.active_lock_reason') AS active_lock_reason,
json_extract_scalar(A._airbyte_data, '$.milestone') AS milestone,
json_extract_scalar(A._airbyte_data, '$.assignee') AS assignee_id,
json_extract(A._airbyte_data, '$.labels') AS labels,
json_extract(A._airbyte_data, '$.assignees') AS assignees,
json_extract(A._airbyte_data, '$.requested_reviewers') AS requested_reviewers,
json_extract(A._airbyte_data, '$.requested_teams') AS requested_teams,
-- user data
json_extract_scalar(A._airbyte_data, '$.user.id') AS user_id,
json_extract_scalar(A._airbyte_data, '$.user.login') AS user_login,
json_extract_scalar(A._airbyte_data, '$.user.html_url') AS user_html_url,
json_extract_scalar(A._airbyte_data, '$.user.type') AS user_type,
json_extract_scalar(A._airbyte_data, '$.user.site_admin') AS user_is_admin,
json_extract_scalar(A._airbyte_data, '$.user.avatar_url') AS user_avatar_url,
...This is also an opportunity to enrich our tables with useful metadata, such as a composite key, the emission time, and the repository name drawn from our macros (as a sanity check against the repository name provided in the JSON).
...
-- meta
A.repo_name AS _repo_name_from_automation,
CAST(A._airbyte_emitted_at AS TIMESTAMP) AS _airbyte_emitted_at_dt,
CONCAT(A.repo_name, '-', json_extract_scalar(A._airbyte_data, '$.id')) AS _primary_key
FROM {{ ref('github_pull_requests_unified') }} AS ADe-duplicate and enrich
There are many ways to de-duplicate records in a set of tables, each with associated tradeoffs. De-duplicating as the first step make sense to avoid manipulating duplicate records, but to reliably de-duplicate each record, we would need to extract a unique composite key from the raw JSON, de-duplicate on that key, then repeat when we explode the rest of the JSON in the next step.
The volume of data is not particularly large here, and storing duplicate records is cheap, so I chose to de-duplicate as the last step rather than the first. This simplifies the DAG and keeps the dbt models atomic and flexible (no assumptions in any other model about working with de-duplicated data).
As with the unification step, we can use dbt macros to keep the models simple and DRY:
{#
De-duplicates rows in source_table using a composite key created by
choosing the latest airbyte_emitted_at_dt and attaching the record id
#}
{% macro latest_airbyte_emission(source_table) %}
SELECT * EXCEPT (__row_number) FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY _primary_key ORDER BY _airbyte_emitted_at_dt DESC) AS __row_number
FROM {{ ref(source_table) }} )
WHERE __row_number = 1
{% endmacro %}Finally, we have the option to further enrich the data by joining with other tables. For example, an org chart in s3 to allow us to separate Preset employees from other contributors.
Conclusion
When all is said and done, we have a set of nice tables suitable for building further transformations and analytic frameworks on top of. We can connect the data to Apache Superset (or Preset Cloud) and easily visualize quantities of interest.
We hope to release our Github repo of dbt models for others to use, so stay tuned! In the next post, we will go deeper into building useful views of the data in Superset.
