


Building an Open-source Ingestion Layer with Airbyte




You may have heard the term "open-core" used to refer to companies that build their product and service offerings on top of open-source software. But not all organizations hoping to profit from open-source have the same motivations, or the same approach.
Some companies build on federated projects like Apache Superset, for which the ASF offers a governance model (the Apache Way) and a license (the ASF license) that allows organizations to invest in open-source with assurances that their investment will be protected.
Preset is one such company, and for us, community is the life-blood of both Superset and our growing business. With the original creator and the plurality of both Apache Superset's committers and PMC members working here at Preset, this company has a special part to play in shaping the development of Apache Superset as an open-source project.
To handle this responsibility well would be to double-down on community efforts, make Superset easier to learn and use, have a clear public roadmap, encourage contributions from new community members, and build a clear picture of how the community wants Superset to grow in the future.
However, for a project the size of Superset (over 40k stars on GitHub at the time of writing, ~2000 folks in Slack), we first need reliable data about who the community is and what they care about (both developers and end-users). We also want to showcase the power of modern open-source data technologies and highlight what can be accomplished entirely with open-source tools.
For these reasons, one of the first things I started working on at Preset is a reference data stack built with all open-source tools that enables organizations to get a cross-sectional view of open-source communities of interest through data pulled from GitHub and Slack. This series of blogs will go into the nitty-gritty of how this can be achieved, the considerations and tradeoffs involved, and how this portable data architecture speaks to the power of the modern open-source data stack.
In this blog, we will focus on the first stop on the journey from data to insights: ingestion.
Ingestion
The first step of getting data from open-source communities into our stack is building an ingestion layer. Data engineers break ingestion tasks into three conceptual tasks:
- Extract: Retrieve data from some external system or data store (SaaS API, cloud object storage, etc)
- Load: Put data into the data store / data warehouse
- Transform: Clean and transform the data to model meaningful business processes
- (+Validate): Collect evidence that the ingestion process is reliable to ultimately enable confident decision-making. (we'll talk more about this one in the next blog)
In the not-so-distant past, ingestion was often handled by ad-hoc scripts and one-off applications written specifically for each pipeline. However, this approach does not scale well and introduces headaches around maintenance and clunky integration with the rest of the modern cloud data platform.
Modern open-source batch ingestion frameworks, also sometimes grouped into the broader category of 'data integration tools', such as Airbyte and Meltano, are being developed to address precisely this problem (for batch architectures). The idea is to standardize ELT by bringing all ELT related tasks into a single maintainable architecture for easier management and more straightforward scaling.
Open-source communities are a key component of these projects, as the ability to build and maintain a long list of data connectors is dependent on fostering a healthy base of enthusiastic outside contributors.
I wrote a blog earlier this year comparing the Airbyte to Meltano and providing my own rationale for choosing Airbyte in this project, but note that both tools are rapidly evolving and each brings its own advantages. Either one could have served as the ingestion layer for this project.
Using Airbyte for Extract and Load
Airbyte provides value as the extract and load components of our ingestion layer through its astounding ease of setup and use, allowing engineering hours to be spent instead on downstream transformations and analytics. Data connectors are divided into 'Source' and 'Destination' types (see a full list here), with the 'Connection' abstraction representing a pipeline between a source and a destination, complete with associated schema, sync scheduling, and other configurables.
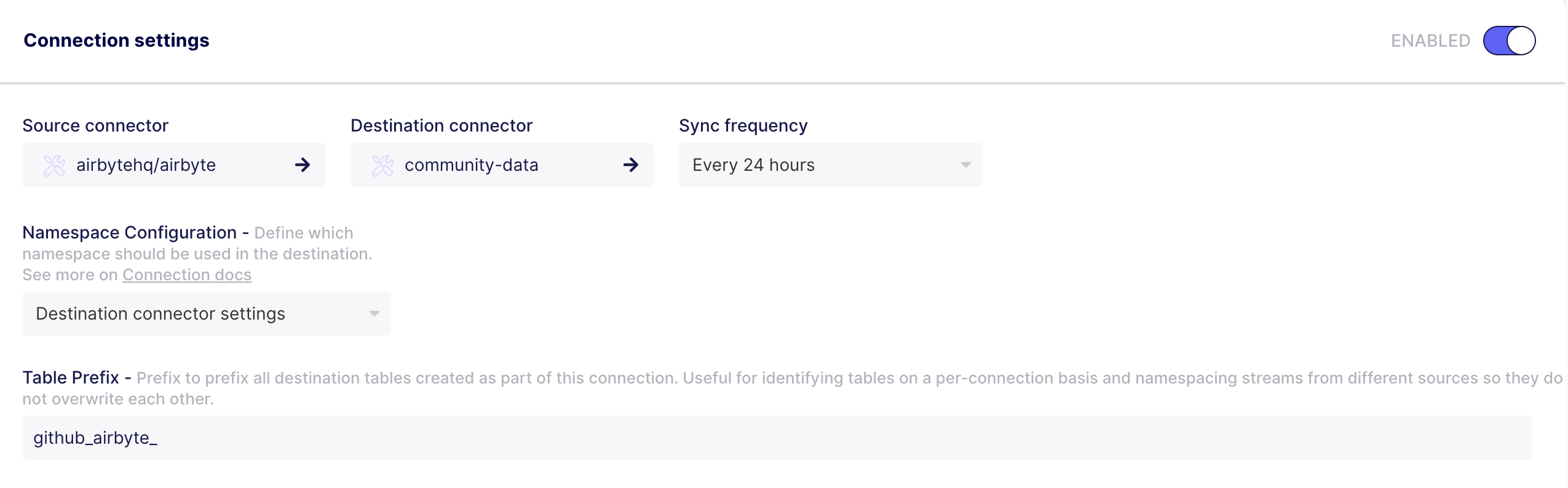
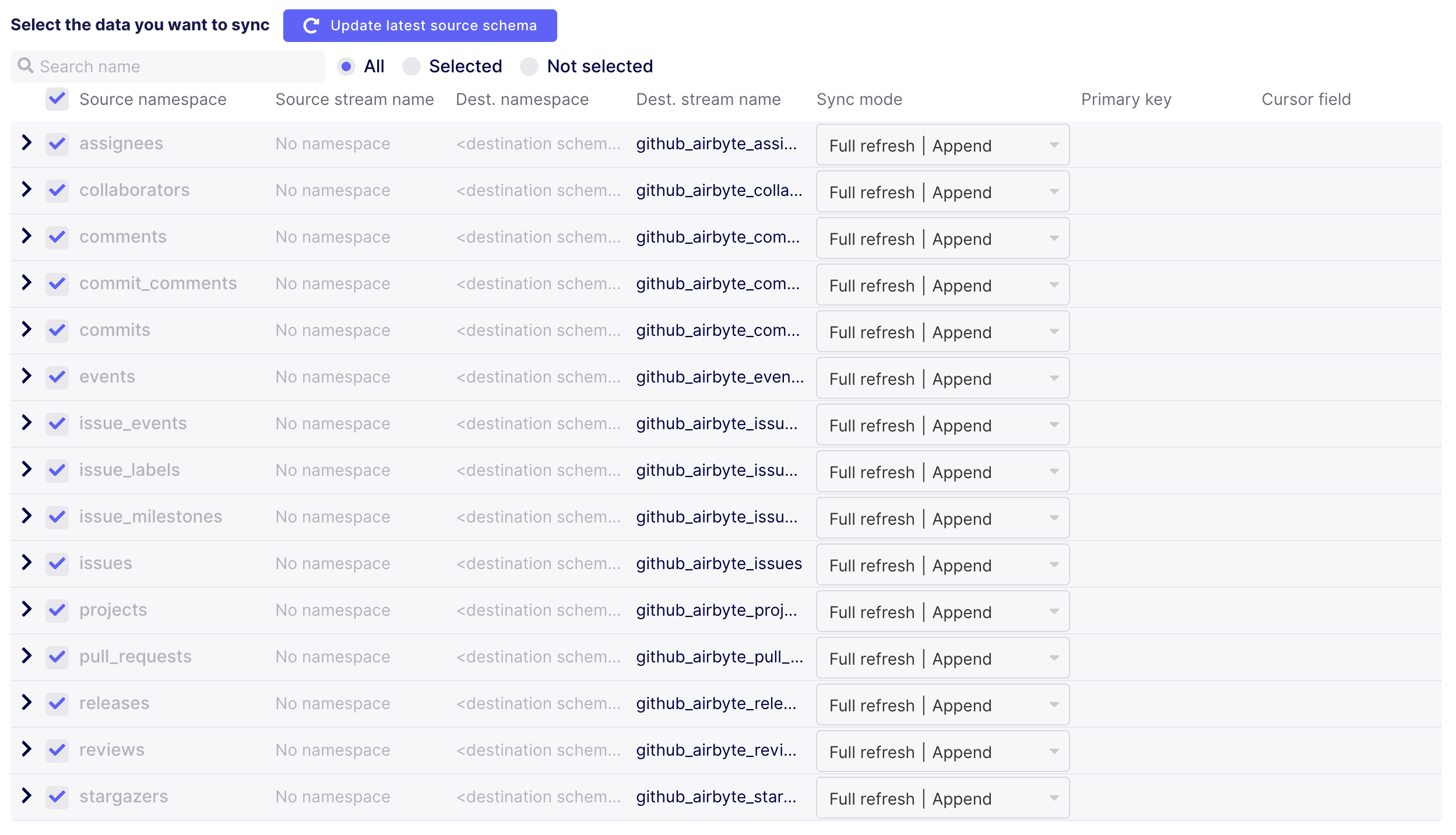
Connections allow many-to-many relationships between sources and destinations, with each connection being individually configurable. I made heavy use of the GitHub, Slack, and File connectors.
There are actually two different GitHub connectors for Airbyte: the legacy connector (containerized Singer GitHub tap), and the newer GitHub native connector created by the Airbyte team.

Although the GitHub native connector has gone through a number of rapid-fire revisions in the last few months with regressions here and there, it's in a reasonably solid place now, and I recommend it over the legacy connector.
As for Slack, we have a blog that takes the reader step-by-step through the process of setting up Airbyte to extract and load data from Slack.
Airbyte for Transformations
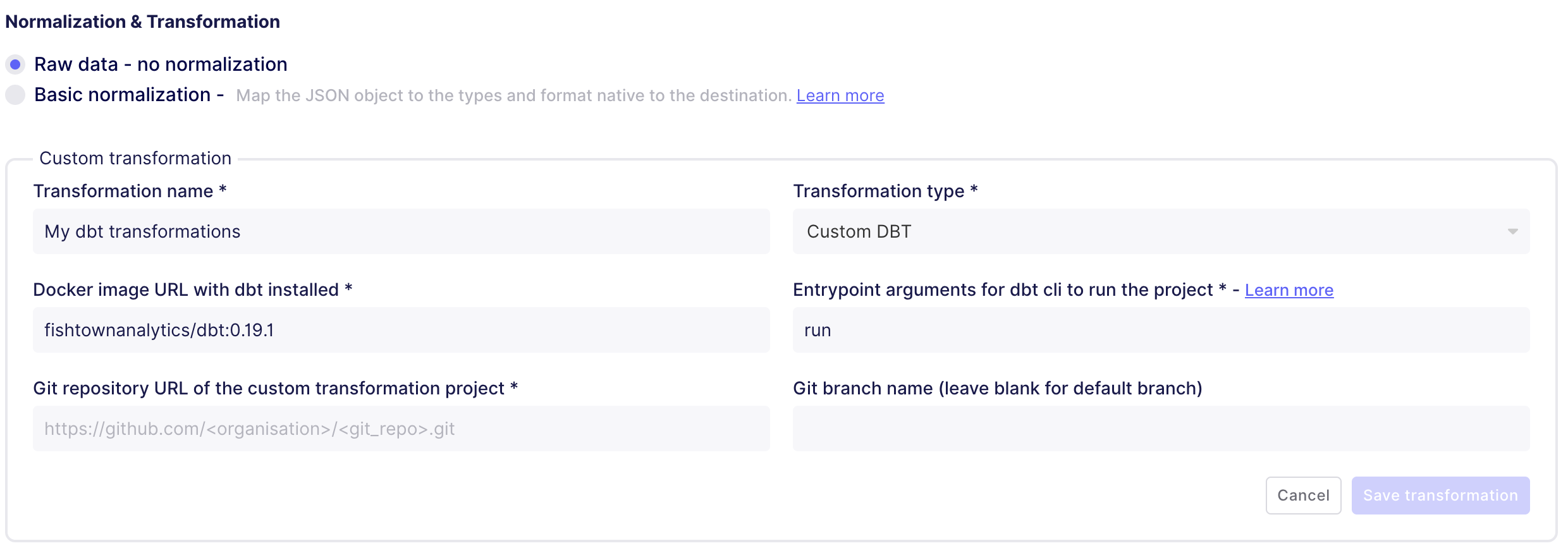
Beyond extracting and loading data, Airbyte can apply transformations to the data at ingestion-time. Each data source has its own default "basic normalization", but I found that building my own transformations on the raw data was more maintainable due to frequent changes in the normalized data when updating the connector version. That being said, Airbyte can now accept a custom dbt model associated with each connection.
Deployment Considerations
A few quick notes about managing an Airbyte deployment:
- For a production environment, there is now a k8s deployment available.
- There is also an Apache Airflow operator for Airbyte that can be used to externally trigger the sync job for each connection. I plan to use this feature down the road to make data transformation jobs wait on the freshest data, and generally better integrate Airbyte with the orchestration layer for the rest of our cloud data platform.
- There is a decision-point about where to carry out transformations on the base data. Airbyte can handle the transformations through custom dbt models (see above), or transformations can be applied outside Airbyte using something like the dbt CLI. I chose to handle all transformations outside Airbyte because I found changes to connectors too often would change the schema of the data, breaking downstream transformations and dashboards.
- Updating the deployment to the latest version of Airbyte is as simple as:
docker-compose down git pull origin master docker-compose up
Conclusion
Keep an eye out for a step-by-step guide on setting up an Airbyte deployment for ingesting community data in the coming weeks (now available here. I'm also going to be talking about the finished project at ApacheCon and Coalesce later this year (both are free to register).
In the near future we will go into detail about using dbt to transform data after it has been loaded into our data warehouse.
Say hi on the community slack, visit Superset on Github, and get involved!
