


Intro To Jinja Templating in Apache Superset™




Intro to Jinja Templating
In the world of Preset and Superset, a dashboard is a collection of charts. Dashboards have the unique capability to tell a story by combining different types of charts to form a narrative.
When used correctly, a dashboard can empower teams to present powerful data-based presentations as well as enable organizations to monitor information based on dynamic data.
But what if we wanted to make our dashboards more interactive? What if we had a dashboard that measured the population of countries and we wanted to have the ability to filter the dashboard based on country or region? What if we had a dashboard that tracked support tickets with columns for associated actions, labels, etc. and we wanted the ability to filter by the different possible ticket label values? How would we achieve these things without the need to modify the underlying queries powering the dashboards?
What is Jinja?
Jinja is a templating engine for Python. The templates are traditionally used in web development to define and re-use common Python code snippets. Other popular software products that utilize Python in their backends such as Ansible, dbt, or Superset/Preset also leverage Jinja as a templating engine!
SQL is powerful — but there are a lot of features that are not supported. There's missing support for loops and variables, as SQL commands are by nature narrower than other conventional programming languages like Python. SQL statements specify what data operations should be performed rather than how to perform them. This often surfaces challenges around how to make SQL more dynamic.
All Superset/Preset queries pass through the Python backend and utilizing Jinja allows users to craft more dynamic SQL queries to increase the interactivity of their dashboards.
- Dynamic SQL helps generalize the SQL
- Increased legibility
- Code used for the generation of SQL queries in templates increase legibility compared to building string statements
- This may require different functions to generate parts of the SQL statements
- With a template these components are rendered inline based on the initial variable inputs
- Increased legibility
In general, creating complex queries with loops and other types of abstractions with Jinja can increase the legibility of queries by reducing the number of times a user may copy paste the same things in statements
At a high level, templating is the ability to add programmatic capabilities to SQL with Jinja acting as the bridge allowing us to inject context into queries. Preset’s SQL Lab supports query templating via the Jinja Framework.
With and Without Jinja (a brief history of Superset)
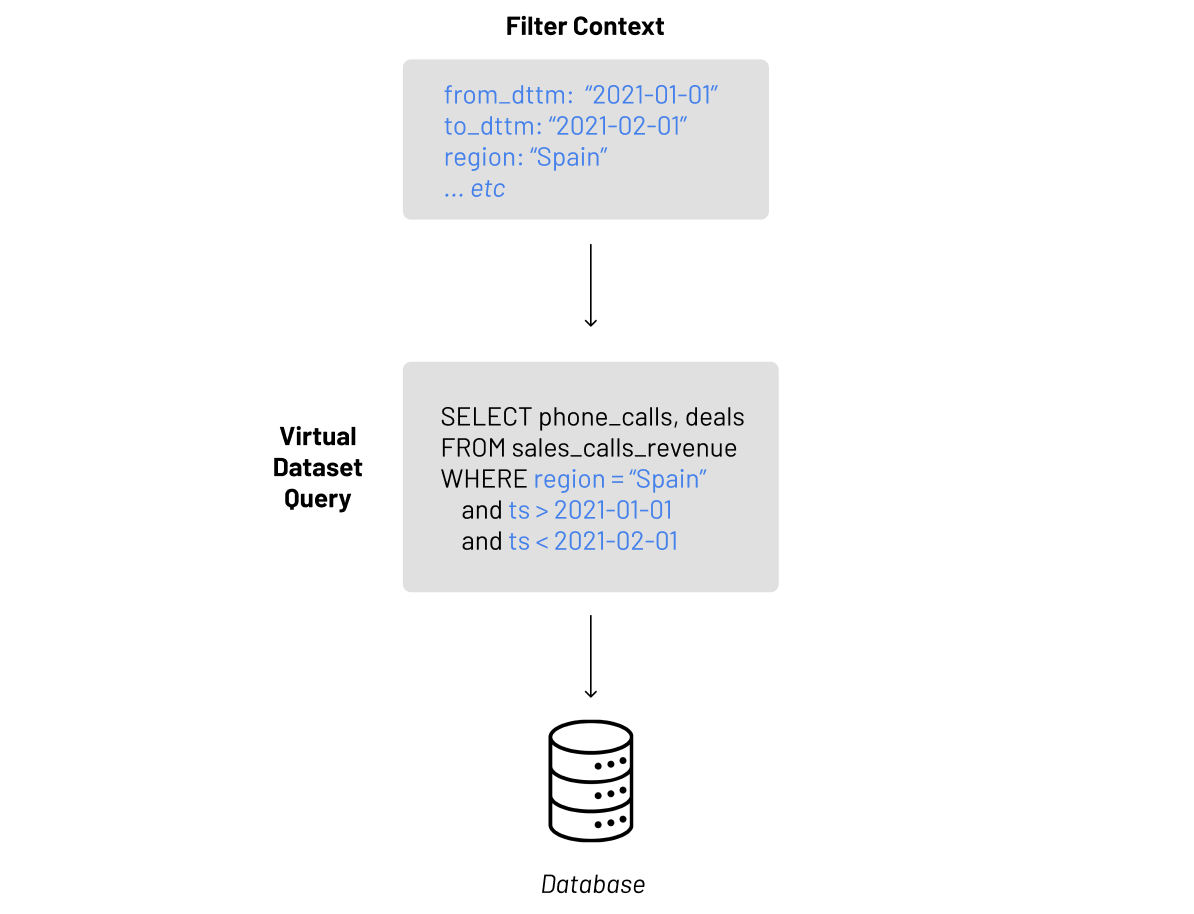
Superset didn’t always have Jinja templating. Before Jinja, only basic “dynamic-ness” could be achieved. Superset originally had filter boxes, which moved on to become dashboard native filters.
Virtual datasets, the primary way to enhance this dynamic-ness pre-Jinja, are created via any valid SQL query (as long as the operations, joins, etc. were supported by the underlying database). At the end of the day a virtual dataset in Superset is simply a query — if the query was changed the virtual dataset would change. The dashboard filters worked by injecting state that the user provides and only whatever is in the filter state can be passed into the query. These are typically only main/outer query operations.
This limited how much control the user had over where the filter values could be applied to the query. More complicated filtering in sub/inner queries couldn’t be done.
In summary, the filter context would be created, injected into the query, that query is sent to the underlying database, and the final query was what Superset would create.

With Jinja context, the filter state becomes a much more powerful tool. Now there is more available to pull from such as:
- User state
- the user_id of the person logged in
- their username
- URL state
- you can add parameters to a Superset URL that can be inserted into your query
- For example, if you have a sales dashboard, and the end user only wanted to see sales in Barcelona:
- A dashboard can be sent where they can go to the filter and click Barcelona
- Send a dashboard with a pre-filtered URL with the city in the URL parameter itself so when the dashboard loads they can immediately see what they want
Most importantly, you still have the filter state but instead of just being injected the way Superset thinks (typically in the WHERE clause) this virtual dataset can now be exposed as a variable to build queries on — so now further options become available such as JOIN only when year greater than some year value, something that wouldn’t be possible without Jinja.
It is important to remember that at the end of the day whether you add this dynamic-ness with or without Jinja everything is still a query: the same concepts apply — context is obtained, it is applied to the query, the query is sent to your database, and Superset surfaces the results of that query. This should always be the mental model to keep in mind when working with Superset!
SQL Templating with Jinja in Superset
SQL Lab and Explore supports Jinja templating in queries. To enable templating, the ENABLE_TEMPLATE_PROCESSING feature flag needs to be enabled either in:
- superset/config.py
- superset_config.py in the root directory (which you must manually create to over-ride values in
superset/config.py
This enables you to extend the SQL queries Superset generates with short Python snippets.
In Preset Cloud, our fully hosted, hassle-free cloud service for Apache Superset, Jinja templating is enabled for you already!
By default, the following variables are made available in the Jinja context:
columns: columns which to group by in the queryfilter: filters applied in the queryfrom_dttm: start datetime value from the selected time range (None if undefined)to_dttm: end datetime value from the selected time range (None if undefined)groupby: columns which to group by in the query (deprecated)metrics: aggregate expressions in the queryrow_limit: row limit of the queryrow_offset: row offset of the querytable_columns: columns available in the datasettime_column: temporal column of the query (None if undefined)time_grain: selected time grain (None if undefined)
For example, to add a time range to a virtual dataset, you can write the following:
SELECT *
FROM tbl
WHERE
dttm_col > '{{ from_dttm }}' AND dttm_col < '{{ to_dttm }}'Common Jinja Use Cases
Before diving deeper into specific use cases with some of the pre-defined macros, let’s touch on two of the most common, broader categories of what people use Jinja templating in Superset for:
Performance
- Dynamic Subqueries
- One example of Jinja templating in the Superset context would be using highly dynamic subqueries for date filtering to avoid the naive outer query approach, allowing the user to be more methodical in their filtering.
- Database Specific Functions
- Another case where Jinja templating is extremely useful in the Superset context is when utilizing exotic database specific functions that have not been implemented in the underlying database engine specs.
- For example, TimescaleDB extends PostgreSQL by adding new functionality, and packages and optimizes PostgreSQL for time-series data analytics. TimescaleDB has it’s own unique time_bucket() function that optimizes the default PostgreSQL date_trunc() function. The
time_bucket()function is much faster and performant thandate_trunc()when attempting to slice millions to billions of rows of date values. Here, Jinja templating becomes an escape valve which allows you to use the DB specifictime_bucket()while avoiding use of the much slowerdate_trunc()
- For example, TimescaleDB extends PostgreSQL by adding new functionality, and packages and optimizes PostgreSQL for time-series data analytics. TimescaleDB has it’s own unique time_bucket() function that optimizes the default PostgreSQL date_trunc() function. The
- Another case where Jinja templating is extremely useful in the Superset context is when utilizing exotic database specific functions that have not been implemented in the underlying database engine specs.
The inclusion of Jinja increases flexibility in the Superset filter functionality and some more specific examples of what Jinja can be utilized for are:
- Displaying only the currently logged in user’s data.
- Using a filter component to filter a query when the name of a filter column doesn't match one in the current query.
- Applying filter constraints via Superset dashboard URL.
- For tables containing arrays, being able to search for entries with a particular value in the array.
- Ability to apply OR statements in a filter for two different columns (e.g.
‘name’ = “Matthew” OR ‘age’ = 12) - Personalized dashboards.
- Controlling access to data using Row Level access based on User_ID.
- Investigate access to Superset metadata by User_ID.
Pre-defined Jinja Macros in Superset
Current User ID
The {{ current_user_id() }} macro returns the user_id of the currently logged in user.
- Macro:
{{ current_user_id() }} - Parameters: None
- Returns: Integer
If you have caching enabled in your Superset configuration, then by default the user_id value will be used by Superset when calculating the cache key.
A cache key is a unique identifier that determines if there's a cache hit in the future and Superset can retrieve cached data.
You can disable the inclusion of the user_id value in the calculation of the cache key by adding the following parameter to your Jinja code:
{{ current_user_id(add_to_cache_keys=False) }}
Current Username
The {{ current_username() }} macro returns the username of the currently logged in user.
- Macro:
{{ current_username() }} - Parameters: None
- Returns: String
Use Case: Retrieve Username
Entered SQL:
SELECT *
FROM jinja_username_demo
WHERE "username" = '{{ current_username() }}'Result:
SELECT * FROM
jinja_username_demo
WHERE "username" = 'test@gmail.com’Just like the {{ current_user_id() }} macro, if you have caching enabled in your Superset configuration, then by default the username value will be used by Superset when calculating the cache key.
You can disable the inclusion of the username value in the calculation of the cache key by adding the following parameter to your Jinja code:
{{ current_username(add_to_cache_keys=False) }}
Custom URL Parameters
The {{ url_param('custom_variable') }} macro lets you define arbitrary URL parameters and reference them in your SQL code.
- Macro:
{{ url_param('custom_variable') }} - Parameters: Takes in string with the name of parameter passed into URL. Pass specified parameter in query into URL such as
url/?reg=North+America. - Returns: String
Use Case: Custom URL Parameters
Entered SQL:
SELECT count(*)
FROM ORDERS
WHERE country_code = '{{ url_param('countrycode') }}'Scenario:
- You're hosting Superset at the domain
www.example.com - You send your coworker in Spain the following SQL Lab URL
www.example.com/superset/sqllab?countrycode=ESand your coworker in the USA the following SQL Lab URLwww.example.com/superset/sqllab?countrycode=US
Result:
For your coworker in Spain, the SQL Lab query will be rendered as:
SELECT count(*)
FROM ORDERS
WHERE country_code = 'ES'For your coworker in the USA, the SQL Lab query will be rendered as:
SELECT count(*)
FROM ORDERS
WHERE country_code = 'US'Explicitly Including Values in Cache Key
The {{ cache_key_wrapper() }} function explicitly instructs Superset to add a value to the accumulated list of values used in the calculation of the cache key.
This function is only needed when you want to wrap your own custom function return values in the cache key. Additional context can be found in this file within the Superset repo.
Note that this function powers the caching of the user_id and username values in current_user_id() and current_username() function calls if caching is enabled.
Filter Values
You can retrieve the value for a specific filter as a list using the {{ filter_values() }} macro
This is useful if:
- You want to use a filter component to filter a query where the name of the filter component column doesn't match the one in the select statement
- You want to have the ability for filter inside the main query for performance purposes
Use Case: Filtering Values
Method One:
SELECT action, count(*) as times
FROM logs
WHERE
action in {{ filter_values('action_type')|where_in }}
GROUP BY actionThe where_in filter converts the list of values from filter_values('action_type') into a string suitable for an IN expression.
Method Two:
SELECT action, count(*) as times
FROM logs
WHERE
action in ({{ "'" + "','".join(filter_values('action_type')) + "'" }})
GROUP BY actionFor both methods above, if NULL values need to be included with a filter, an additional OR clause may need to be added to the WHERE clause to include this case.
You can use this feature to reference the start & end datetimes from a time filter using:
- Start datetime value:
{{ from_dttm }} - End datetime value:
{{ to_dttm }}
Boolean Value Filtering
Boolean filter values can also be used for filtering. However, the extra single quotes added to the filter values Jinja needs to be removed.
Use Case: Boolean Filter Values
SELECT name, count(*)
FROM "Slack Users"
WHERE
is_bot in ({{",".join(filter_values('bot_filter'))}})
GROUP BY nameFor this Jinja templated filter to operate, the values in column bot_filter of the dataset populating the filter must be strings, not booleans.
Filters for a Specific Column
The {{ get_filters() }} macro returns the filters applied to a given column. In addition to returning the values (similar to how filter_values() does), the get_filters() macro returns the operator specified in the Explore UI.
This is useful if:
- You want to handle more than the
INoperator in your SQL clause - You want to handle generating custom SQL conditions for a filter
- You want to have the ability to filter inside the main query for speed purposes
Use Case: Filters for Specific Columns
WITH RECURSIVE
superiors(employee_id, manager_id, full_name, level, lineage) AS (
SELECT
employee_id,
manager_id,
full_name,
1 as level,
employee_id as lineage
FROM employees
WHERE 1=1
{%- for filter in get_filters('full_name', remove_filter=True) -%}
{%- if filter.get('op') == 'IN' -%}
AND full_name IN {{ filter.get('val')|where_in }}
{%- endif -%}
{%- if filter.get('op') == 'LIKE' -%}
AND full_name LIKE {{ "'" + filter.get('val') + "'" }}
{%- endif -%}
{%- endfor -%}
UNION ALL
SELECT
e.employee_id,
e.manager_id,
e.full_name,
s.level + 1 as level,
s.lineage
FROM
employees e, superiors s
WHERE s.manager_id = e.employee_id
)
SELECT
employee_id,
manager_id,
full_name,
level,
lineage
FROM superiors
ORDER BY lineage, levelUsing Jinja To Filter Data (Walkthrough)
General Overview
Here's a high-level overview of the workflow for using Jinja templating in Superset.
- Create a Virtual Dataset.
- Modify the Virtual Dataset query to include the Jinja Templating structure.
- Create a Chart from the Virtual Dataset and add it to a Dashboard.
- Configure the Dashboard filters.
Step 1: Creating a Virtual Dataset
For this example, we'll use the Vehicle Sales table from the examples database.
Consider the query below:
WITH calculation as (
SELECT count(*), country
FROM "Vehicle Sales"
WHERE product_line in ('Classic Cars', 'Motorcycles')
GROUP BY country
)
SELECT * FROM calculationIf we create a Virtual Dataset using this query, the dataset will have only two columns — count and country. We won't be able to create a dashboard filter for product_line so we can utilize Jinja to do just that!
If we execute the query including the Jinja templating in the SQL Lab directly, it won't return any results as we don't have the filters in there to pass the values, which means that the executed query end up looking like:
WITH calculation as (
SELECT count(*), country
FROM "Vehicle Sales"
WHERE product_line in ('')
GROUP BY country
)
SELECT * FROM calculationTo get around this we need to create the Virtual Dataset without Jinja first:
- In the Toolbar, hover over SQL Lab, and in the sub-menu select SQL Editor.
- In the SQL Editor, select the following database, schema, and table:

Use the following SQL with a value for product_line to create a new virtual dataset:
WITH calculation as (
SELECT count(*), country
FROM "Vehicle Sales"
WHERE product_line in ('Classic Cars')
GROUP BY country
)
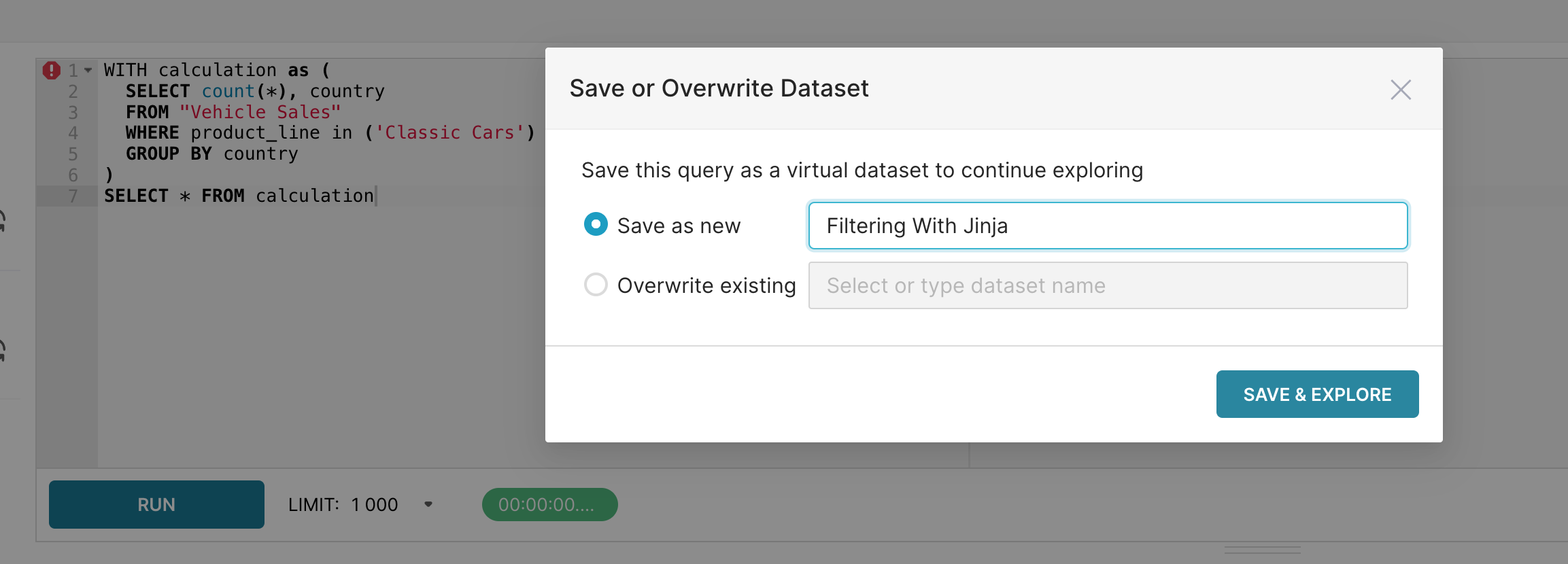
SELECT * FROM calculation- Select Run and then Explore. The Save or Overwrite Dataset window appears.
- Name new virtual dataset "Filtering with Jinja" and then click Save & Explore.
Step 2: Modify the Virtual Dataset to Include Jinja
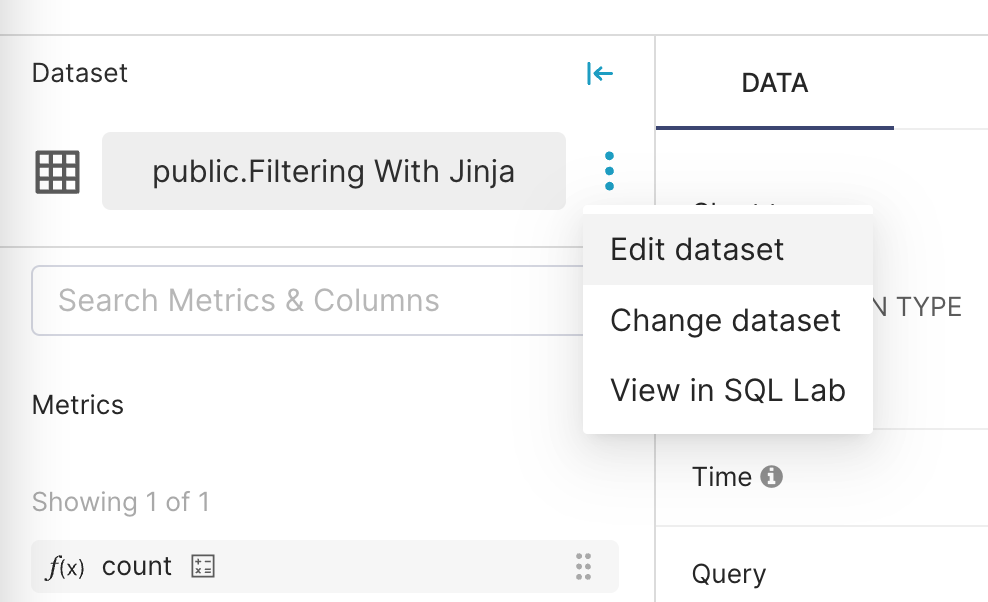
A new tab will open in your browser featuring your new virtual dataset. The first thing to do is to include the Jinja templating in the dataset.
In the Dataset panel, select the vertical ellipses and, in the sub-menu, select Edit dataset.
- The Edit Dataset window appears. In the Click the lock to make changes field, select the lock icon to enable dataset editing.
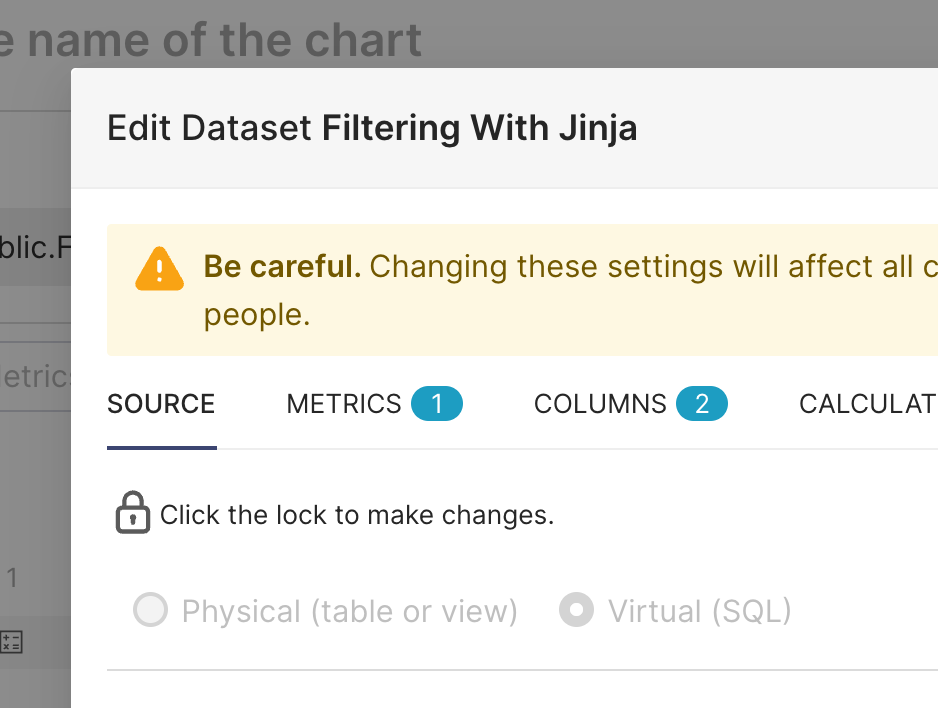
In the SQL text-entry panel, replace product_line in ('Classic Cars') with:
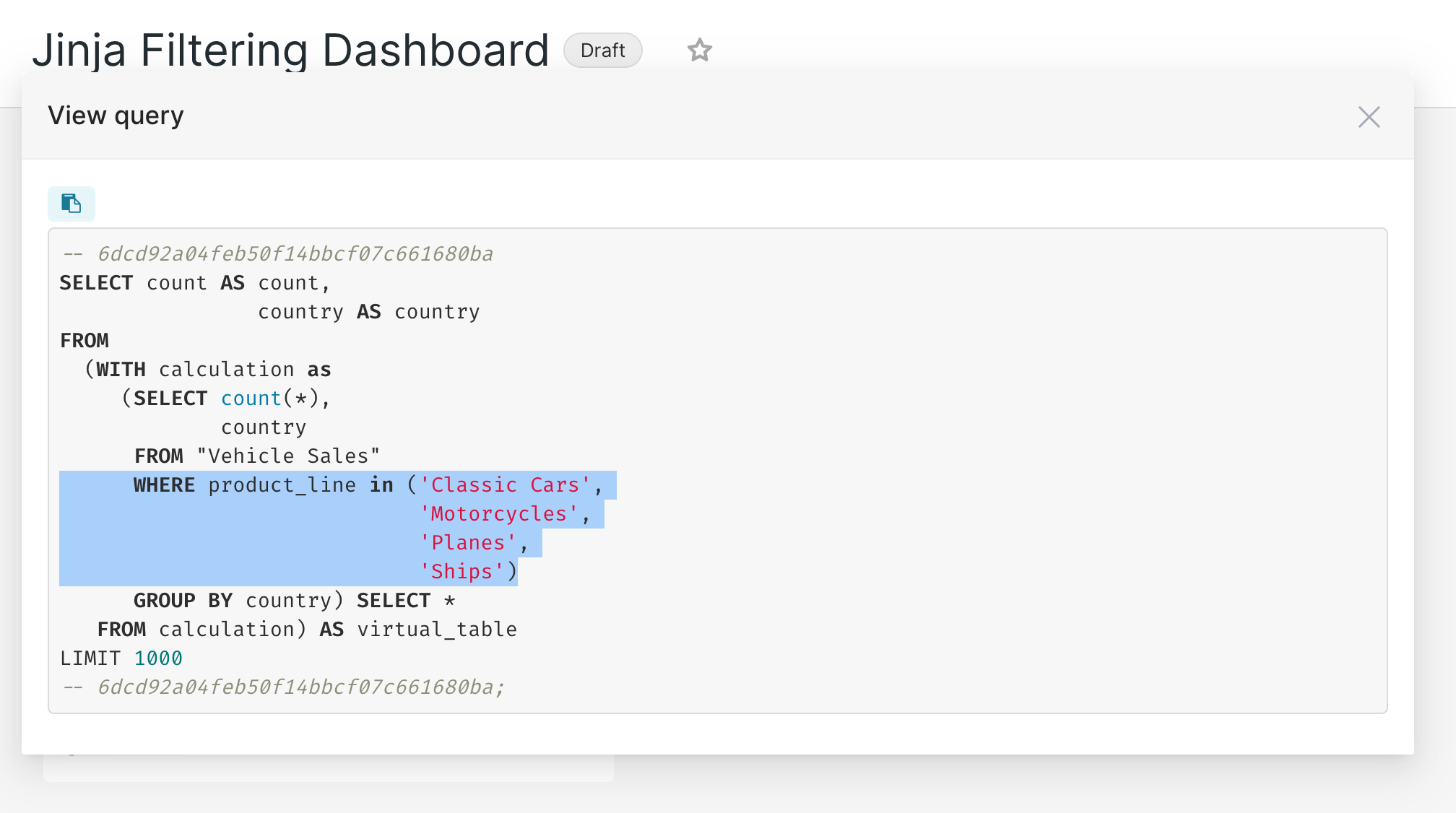
product_line in ({{ "'" + "', '".join(filter_values('product_line')) + "'" }})
and then select Save.
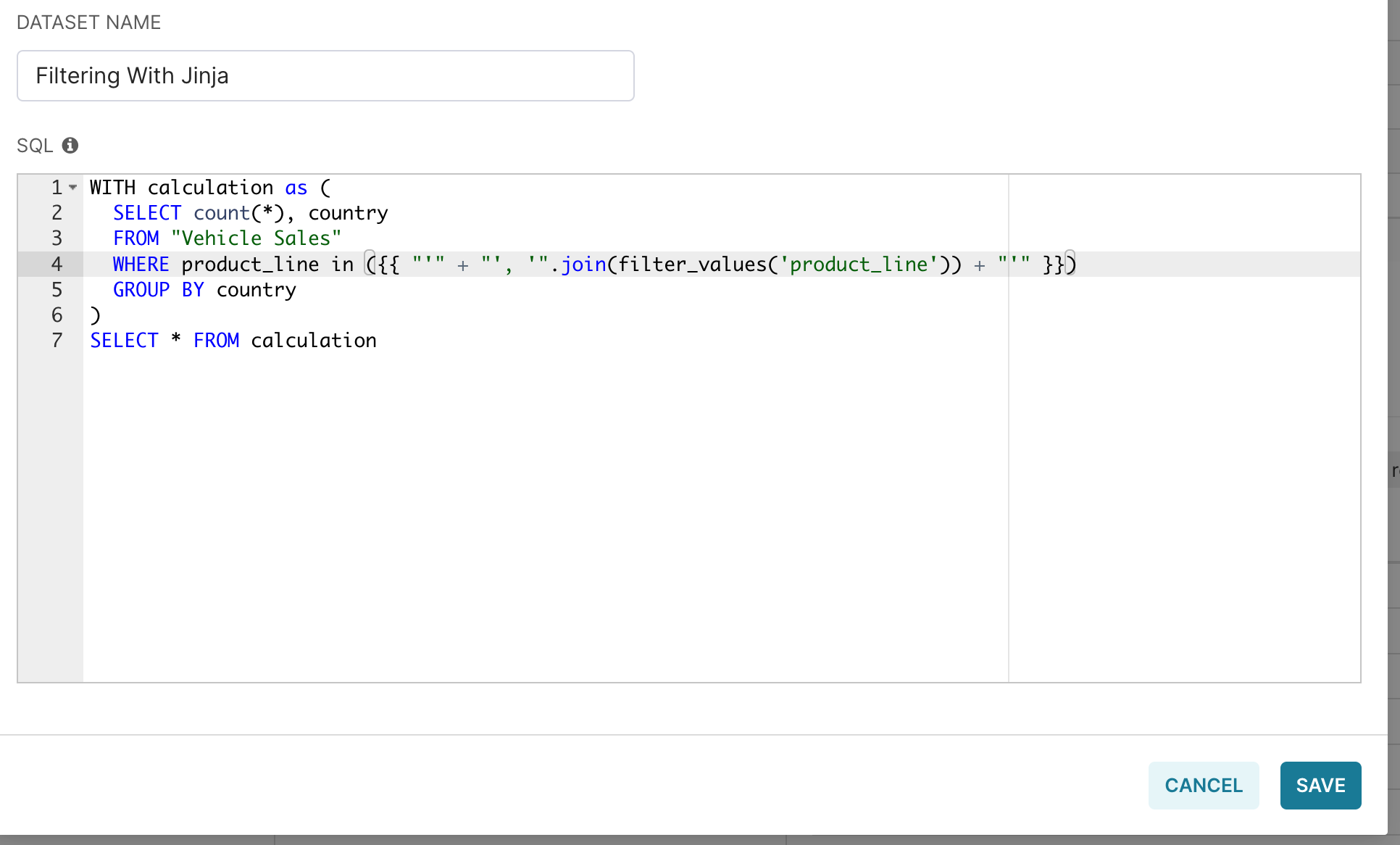
Lastly, in the Confirm Save window, select OK.
Structure of Jinja Templating
- The beginning —
{{ "'" + "', '".join(— and ending —) + "'" }}— are responsible for concatenating everything — this structure allows for filtering with multiple values. filter_values('Column-Name')is the actual function that's going to look for the filter value. In this case,Column-Nameisproduct_line— we'll talk more about this in the coming steps.
Step 3: Add Chart to Dashboard
Now that we have properly modified the Virtual Dataset, we can execute our chart by selecting Update Chart.
If you see “No results were returned for this query”
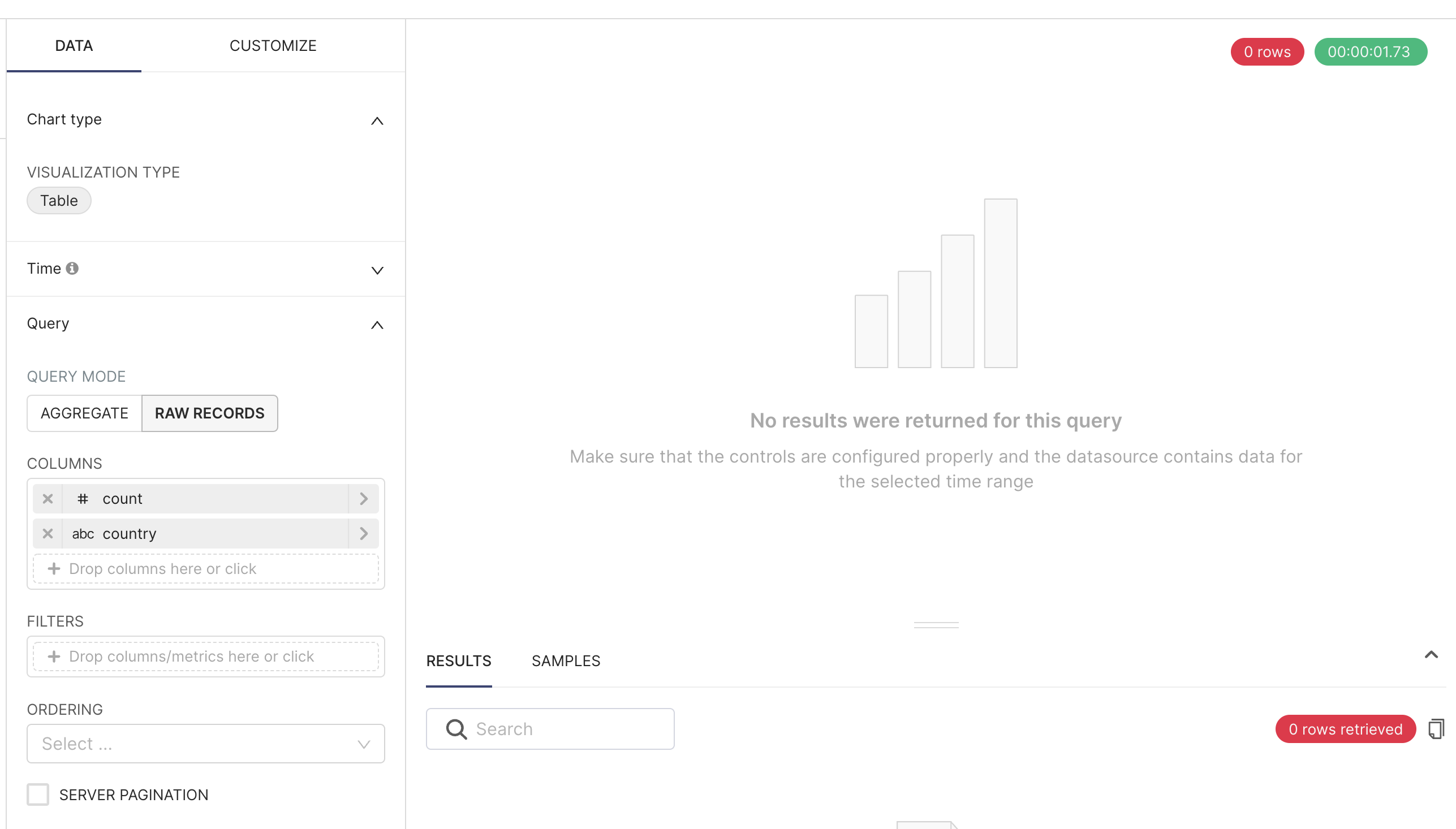
It’s expected! The chart will not return any results because it has yet to be configured.
Select Save to save the chart to a new or existing dashboard.
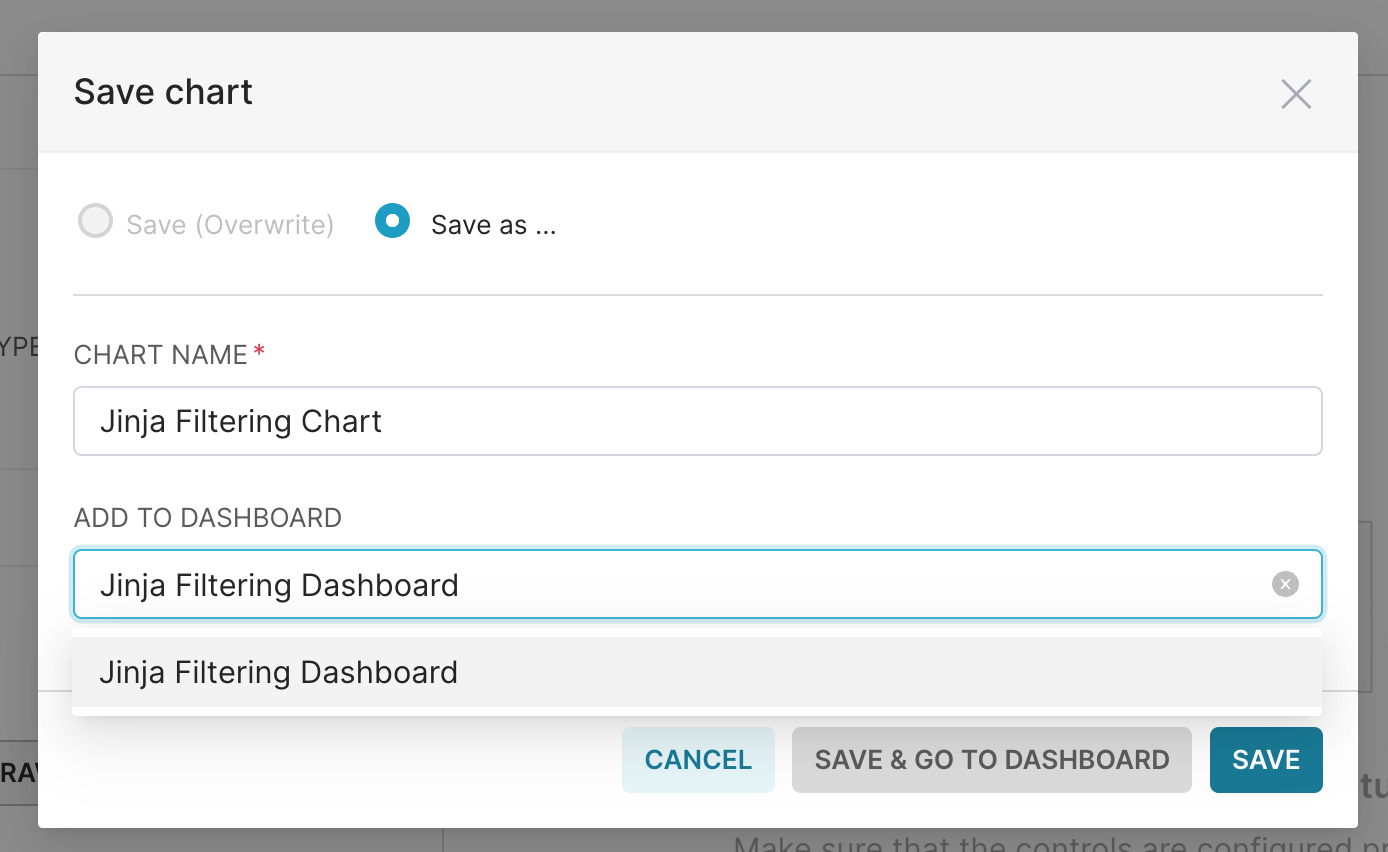
In this example, we titled the chart "Jinja Filtering Chart" and saved it to a new dashboard. When completed, select Save & Go to Dashboard.
Step 4: Configure the Dashboard Filters
The dashboard will launch in your browser. After it appears, let's start the final step of configuring the dashboard's filters.
Start by selecting the right arrow to expand the Filter area, and then select + Add/Edit Filters.
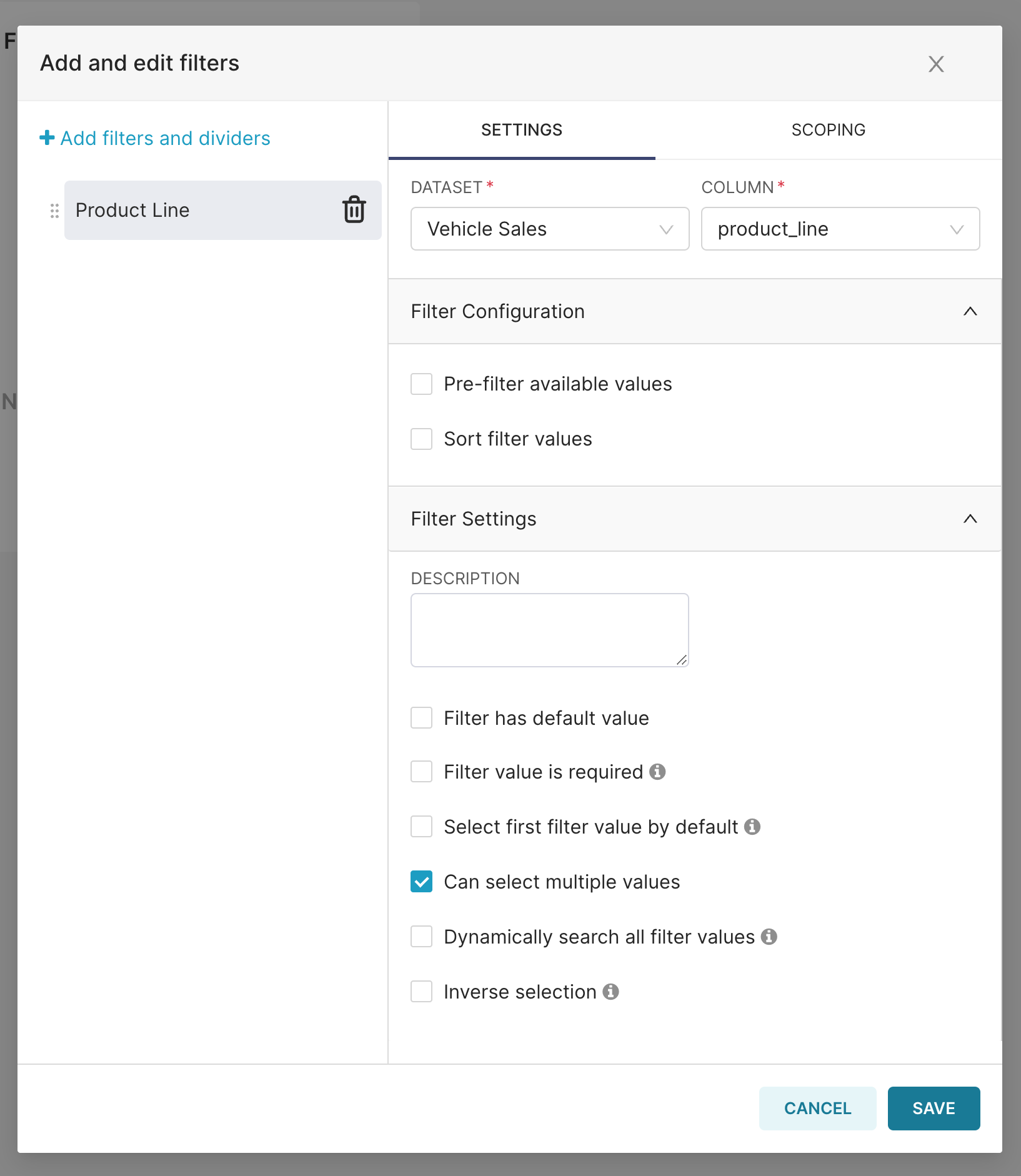
The Add and edit filters window appears.
- In the Filter Name field, enter a name for your filter. In this example, we will create a filter that displays options from our Jinja-revised product line, so we’ll call the filter "Product Line".
- In the Dataset field, let's switch from our virtual dataset to the actual source for the inner query, which is Vehicle Sales.
- In the Column field, we’ll select product_line because this is what defines our column name in the Jinja structure.
- Next, select the Scoping tab to ensure that the filter is mapped to your chart.
- When done, select Save.
Now let's see the filter in action!
In the new Product Line filter, we selected Motorcycles, Planes, Trains, and Ships, and then selected Apply Filters.
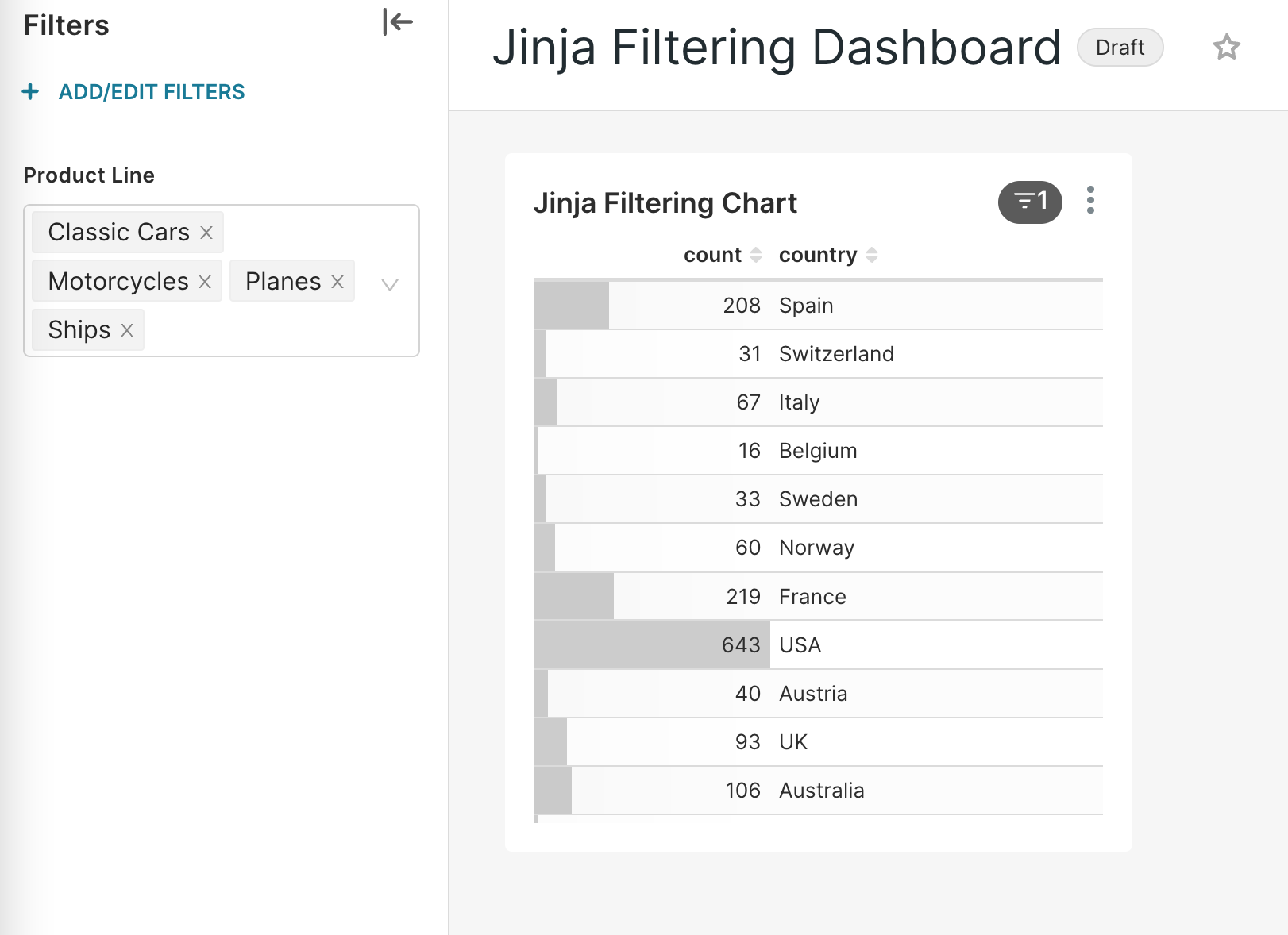
If you'd like to see your inner query displayed via Jinja Templating — select the vertical ellipsis icon in the chart and then choose View query.
Now the query updates to include the filter values of Product Line:
Conclusion
It should be re-emphasized that Jinja via Superset serves as an escape valve to perform actions against the underlying datasets. Complexity can become increasingly difficult to manage if Jinja templating is used to create intense custom queries and virtual datasets for every piece of advanced transformation logic, rather than having these datasets created and transformed accordingly further upstream in the data architecture, and making them available for proper visualization within Superset (where it really shines). All of this can result in much harder to debug issues, should they arise, because the data lineage and transformation logic becomes that much more obfuscated and harder to trace.
The core use case for Superset is to enable people to explore, visualize, and collaborate on their data effectively. If you've set up the transformation layer to power the datasets you need for your analysis, Superset aims to be the fastest way to craft a chart. Superset ideally serves fast-moving data teams and works best with a dataset-centric approach which you can learn more about from the Case for Dataset-Centric Visualization blog post by Max Beauchemin.
If you prefer an up-to-date documentation reference for Jinja templating in Superset / Preset, we recommend our Preset Documentation!
