


How The Modern Data Stack Is Reshaping Data Engineering




Back in 2017, I wrote two blog posts about the then-emerging data engineer role. The Rise of the Data Engineer post detailed the role and responsibilities while,the Downfall of the Data Engineer detailed the challenges around the role.
Now almost 5 years later, it’s a good time to check point and explore how the landscape has changed. How have things evolved? What are the major trends around this role today? Where are we headed?
While I’m a startup founder and a CEO now, I’m still a data practitioner who has been very involved in everything data at Preset. This has allowed me to experience how data-related functions can be tackled in smaller organizations starting from scratch. Interestingly, accessibility for smaller data teams is one of the trends that I’ll be exploring in this post.
Major trends affecting data engineers
In this post, I’m going to highlight the major trends in the modern data ecosystem and how they are affecting the data engineering role. Note that the goal here is to go wide and shallow and cover a lot of trends at a super high level before diving deeper into each trend separately in future blog posts.
Here are the trends I’m looking to cover:
- Data infrastructure as a service
- Data integration services
- Mountains of Templated SQL and YAML
- ELT > ETL
- The rise of the analytics engineer
- Data literacy and specialization on the rise
- Computation Frameworks
- Accessibility
- Democratization of the analytics process
- Erosion of the semantic layer in BI
- Decentralized governance
- Every product is becoming a data product
Data infrastructure as a service
While it was already clear that DBAs (database administrator) were becoming extinct 5 years ago, the data infrastructure engineer role was alive and well. Today, it’s clear that much of the infrastructure-related work is moving to the cloud under specialized multi-tenant, fully managed, elastic services.
Snowflake, BigQuery, Firebolt, Databricks, and others offer pay-as-you-go, managed cloud data warehouses or data lakes and this really feels like the future. Beyond data warehouses, managed services are popping across the data infrastructure landscape. For Apache Airflow alone, there are 3 commercial offerings (Astronomer, Amazon’s MWASS and Google’s Cloud Composer).
All of these services in aggregate will outperform any given data infrastructure team, both from a stability and a cost effectiveness standpoint. This is somewhat required given the fact that even if you had the budget, there simply weren’t enough data infrastructure engineers in the world to serve every organization’s needs. This creates significant economies of scale for all of us to benefit from.
Given this trend, new needs are emerging for data engineering teams:
- procurement: researching technologies and vendors, evaluating compliance and data-related policies, and negotiating a decent deal can be fairly time consuming
- integration: despite a clear incentive for vendors to play nicely with each others, making all this heterogenous software work well together can be a challenge
- cost-control: with infinitely scalable multi-tenant cloud-native services, the challenge shifts from “how do I make the best out of what I paid for” to “how do we keep costs under control!?”
Data engineering teams are increasingly involved in selecting modern data stack tools, integrating them, and keeping costs in check.
Data integration services
A significant chunk of the 2017 data engineer’s time and frustration was to process atomic REST APIs to extract data out of SAAS silos and onto your warehouse. Now with the rise in quality and popularity of services like Fivetran and open source counterparts like Meltano and Airbyte, this is becoming much less of a focus. Many organizations rightfully decided to dump their dubious scripts in favor of a managed service that can simply sync atomic data to your warehouse.
Given the availability and/or price point of these solutions, it’d be misguided to attempt the from-scratch approach. In 2021 it’s a no-brainer to use a data integration service like one of the solutions mentioned above.
Reverse ETL
Reverse ETL is a more recent addition tackling integrating from data warehouses and into operational systems (read SaaS services here) seems like a modern new way of tackling a subset of what traditionally we might have called Master Data Management (MDM) . For those curious on fossilized technology, you may want to read about EAI or EII, some of the concepts and ideas are still interesting today. To provide an example to people less familiar with the term, the common use case here is to bring behavioral product information into your CRM to run targeted product-engagement campaigns.
High Touch , Census , and Grouparoo are great options and make it super easy to push your entity data and their attributes to a wide array of targets. Similar to the pains of extracting data from 3rd party APIs when it came to data integration, the pains of syncing data from your warehouse back to a 3rd party SaaS tool is not something that makes sense to do anymore. The rise of reverse ETL is a great thing because the process was tedious, results were brittle, and it was simply extremely inefficient for every company to be reinventing those wheels.
More generally speaking, I’d strongly advocate teams who are managing custom data integration scripts should treat those scripts as technical debt and actively migrate away from custom solutions and towards hosted solutions.

Thanks to Astasia Myers for this flow diagram!
ELT > ETL
While an ELT based transformation approach is not new (personally I’ve been doing mostly ELT over ETL for the past 2 decades), this approach is increasingly settling as the common approach. Informatica, DataStage, Ab Initio and SSIS are increasingly distant memories for most practitioners. It simply makes sense to bring the computation to where the data lives. Distributed cloud database are a wonder of distributed system technology, and it just makes tons of sense to leverage the highly optimized query engines to also generate the datasets.
Interestingly, the rationale for the same engine to both perform transformation and serve analytics queries is so clear, that we’ve seen the Spark ecosystem increasingly become a database through the rise of SparkSQL. Meaning not only databases are increasingly good at supporting ETL workloads, some ETL systems are increasingly good at acting as a database.
Despite this shift, it feels like it’s still challenging to define arbitrary inline/procedural computations to take place in database engines, but progress is being made there as it’s inevitable. I haven’t personally attempted to push UDFs (user defined functions) and arbitrary script workloads into BigQuery or Snowflake, but can only assume that data warehouses are becoming better at supporting external workloads. Also assuming that the array of functions are expanding, a good example of that is the geospatial functionalities in BigQuery.

dbt has helped popularize ELT and analytics engineering.
Mountains of templated SQL and YAML
The industry is doubling down on templated SQL and YAML as a way to manage the “T” in ELT. To be clear, this direction was already materializing when I created Airflow in 2014, but many in the industry thought we were going to move towards dataframe-type APIs (like Spark dataframe API, or the Apache Beam spec). From my visibility on the Airflow ecosystem, templated SQL is a large portion of what Airflow DAGs are operating on, and the prevalence of DBT is also a clear signal that a large portion of the ELT logic is implemented in that way.
There’s a lot of good reasons for this direction: SQL is a mature standard, well established, well known, easy to learn, and declarative. Couple this with a templating language like Jinja and you can make it parameterized and much more dynamic. Given this purely text-file way to express all this, it can be checked into source control and continuous integration and deployment can be applied, which is major progress over previous no-code centric methods. Connor’s McArthur’s 2018 talk “KISS: Keep it SQL, Stupid” captures well why this approach makes sense.
On the other hand, and to make a comparison that most data engineers may not fully grasp, it feels like what early PHP was to web development. Early PHP would essentially be expressed as PHP code snippets living inside HTML files, and led to suboptimal patterns. It was clearly a great way to inject some more dynamisity into static web pages, but the pattern was breaking down as pages and apps became more dynamic. Similarly, in SQL+jinja, things increasingly break down as there’s more need for complex logic or more abstracted forms. It falls short on some of the promises of a richer programming model. If you take the dataframe-centric approach, you have much more “proper” objects, and programmatic abstractions and semantics around datasets, columns, and transformations.
This is very different from the SQL+jinja approach where we’re essentially juggling with pieces of SQL code as a collage of strings. Another core issue is the fact that this programming model punts on the dialect issues inherent to SQL implementations. SQL + Jinja logic cannot really be re-used across database engines, or it gets messy very quickly, making it hard to build cross-engine reusable logic.
I’ve been very interested in higher level abstractions sitting over the transform layer - namely “computation frameworks” or “parametric pipelines” as pieces of reusable data engineering machinery that can perform complex tasks. It’s pretty clear to me that combining SQL with Jinja templating doesn’t provide the proper foundation for these emerging constructs.
But clearly this topic warrants a full post to decompose how we got here, what it means for the industry, and explore which tool works best for different personas and use cases.
Rise of the Analytics Engineer
It’s been amazing to see analysts perfect their SQL and learn tools like git and jinja, but what does that mean for data engineers? It’s clear that managing mountains of templated SQL has been in-scope for data engineers since the early days, so does that mean data engineers are passing this on to the analytics engineer? I do not think that it is the case: data engineers are and will stay active on the transform layer.
There’s something interesting here about orientation of the role. Specifically, I mean whether the role is:
- primarily vertically aligned (as in supporting a specific product vertical or team) or
- primarily horizontally aligned (as in building things that support a variety of teams and functions).
Assuming that the analytics engineer is primarily vertically-minded, this will enable the data engineer to focus more on horizontally-aligned initiatives. If the data engineers in an organization are excited to operate at a more foundational layer supporting analyst engineers, this brings new functions and responsibilities:
- owning core datasets: as analytics engineers cover more specific subject areas, data engineers may cover the mission-critical datasets that are heavily shared across teams
- data modeling: define and refine best practices around modeling data
- coding standards: define and defend naming conventions, coding conventions, and testing standards.
- abstractions: create and manage reusable components in the form of jinja macros libraries and computation frameworks
- metadata management: data assets documentation, discoverability, metadata integration, etc
- data operations: SLAs, data warehouse cost management, data quality monitoring, anomaly detection, and garbage collecting unused resources
Here’s a helpful diagram from Claire Carroll’s blog post on the dbt Labs website:
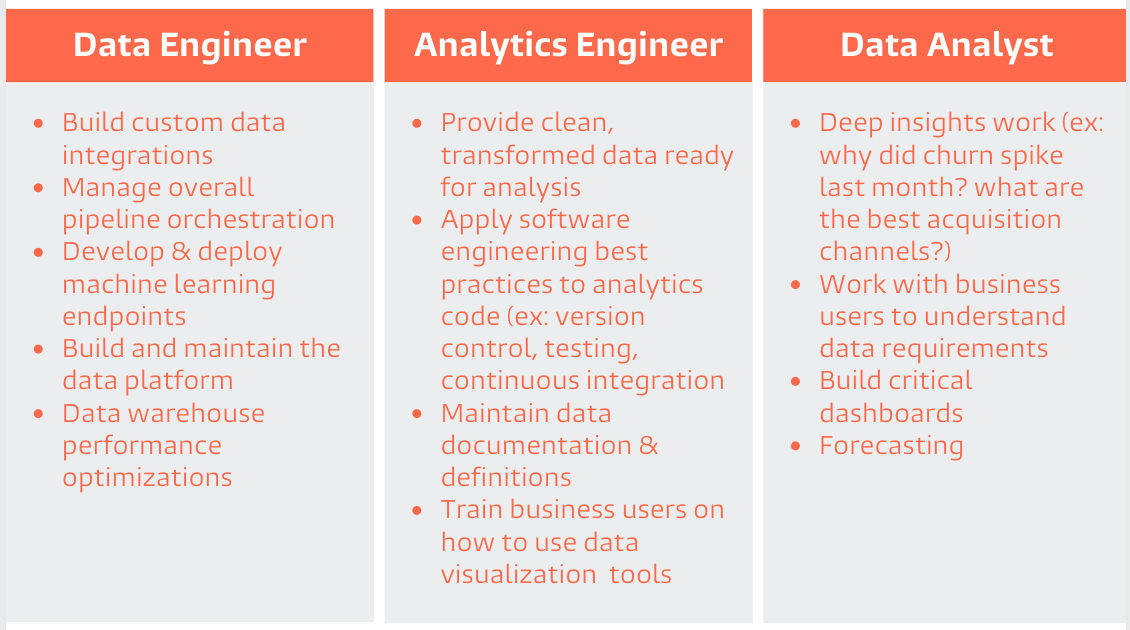
Claire’s categorization is enlightening, though my mental model for it is probably better expressed as a venn diagram, where analytics engineering exists where the 2 established roles overlap with an emerging role in this middle section.
Another way to think about it is by relating it to the frontend, backend, and fullstack flavors of web development. There’s a spectrum with certain individuals covering different ranges and depth in different areas (T-shaped individuals!). Increasingly we hear conversations about where individuals fit on that spectrum, and job descriptions are more clear about the area or range they’re targeting.
Data Literacy and Specialization on the Rise
This shouldn’t be a surprise to anyone, but in the information age, data-skills are increasingly important, and every information worker is becoming increasingly sophisticated with analytics.
Given the greater investment in data teams, we’re seeing further specialization around “data professionals” (which I define as people with the word “data” or “analytics”-derivative somewhere in their title). “Data ops”, “data observability”, “analytics engineering”, “data product manager”, “data science infrastructure”.
We’re also seeing software engineers sharpening their data products-making skills, showing experience with data visualization library, and having developed experience building analytics-heavy products.
A clear trend is developing around applying some of the devops learning to data and creating a new set of roles and functions around “dataops”. We’re also seeing all sorts of tooling emerge around dataops, data observability, data quality, metadata management.
Extrapolating on this trend, maybe it’s just a matter of time before someone writes about “the rise of the metadata engineer”.
Democratization of the Analytics Process
Democratization of access to data is old news and somewhat cliché at this point. A more interesting trend is how the whole analytics process (the process by which data is logged, accumulated, transformed and consumed) is becoming increasingly accessible to more people.
We see PMs getting more familiar and closer to instrumentation, more people learning SQL and contributing to the transform layer, more people using the abstractions provided by data engineers in the form of computation frameworks.
Also software engineers are becoming more data-aware, whether they’re using product analytics themselves or building analytics in their products.
Computation Frameworks
We’re seeing more abstractions emerging in the transform layer. The metrics layer (popularized by Airbnb's Minerva, Transform.co, and MetriQL), feature engineering frameworks (closer to MLops), A/B testing frameworks, and a cambrian explosion of homegrown computation frameworks of all shapes and flavors.
Call this “data middleware”, “parametric pipelining” or “computation framework”, but this area is starting to take shape. Since we’re in the very early stages here, I’ll punt on the topic for a deeper dive in a future blog post.
Accessibility
Building on other trends, and most notably on the “data infra as a service” item mentioned above — it’s becoming more accessible for smaller organizations to be mighty with data. This is largely due to the accessibility of SAAS pay-as-you-go-type solutions. Not only you can have the equivalent of the best data infrastructure team as a service, these services generally integrate fairly well together, offer great compliance guarantees (SOC2, HIPAA, GDPR/CCPA, etc.) and offer amazing time-to-value, scale to infinity and are super cheap for smaller data volume.
Accessibility seems to be a crucial factor around the modern data stack and companies born in the “analytics age” are able to develop their data skills very early and use this as a competitive advantage.
Erosion of the Semantic Layer
As a quick refresher, here’s a good definition of what the semantic layer is (shamelessly copy/pasted from this great article ):
A semantic layer is a business abstraction derived from the technical implementation layer – a model layer that uniformly maintains business logic, hierarchies, calculations, etc. This frees business users from concerns about the technical complexity and implementation of the underlying data source. A data consumer (no matter his/her data literacy) needs to be able to easily discover, understand, and utilize the data. The semantic layer provides business users with an easy way to understand the data.
The first challenge with this abstraction is the fact that most companies use multiple tools, and that this precious information has to be maintained in multiple systems. Informing such a layer requires a deep knowledge of the information architecture of the given tool. For example Looker’s LookML is complex, and only a small population of data professionals are familiar with it. Similarly and historically, Business Objects’ Universes, MicroStrategy Projects, or Microsoft’s OLAP are very complex and not-so-transferable skills. As a data professional, it’s not clear that I want to be the semantic layer maintainer. Clearly there’s a need for a “universal semantic layer” as an open standard that tools can subscribe to, but that has failed to materialize for a variety of reasons that I’ll refrain from expanding in this post.
Secondly, and multiplying the scale of the problem, is the fact that change management in data is extremely hard already, without having to fiddle with this abstraction layer. In fast-moving organizations, not only the schema is evolving quickly to reflect the changing nature of the internal systems, the way to business is thinking about metrics and dimension is also a moving target. Given the mandate of the semantic layer to bridge these two worlds, it sits at an uncomfortable place and takes on a lot of forces / pressure. Historically the GUI nature of the semantics made it even harder to manage along with code and data migration changes.

Semantic layer artifacts from before data was cool - a screenshot from the Business Object Universe Editor
For all these reasons and more, the semantic layer has been eroding into the data transformation layer (read DBT, Airflow, other ETL/ELT) where modern data modelers tend to use more denormalization, often as a layer on top of dimensional modeling, to create easy-to-consume data structures. Those rich data structures (whether they are physical tables or views) are more self contained and require less or no joins in most cases, and generally less semantics to make sense of them.
Conceptually the join semantics still exist somewhere, but they have been moved to the transform layer and often “materialized”. Moving those semantics to the transform layer has lots of advantages that can’t be undersold — that layer is in source control, and converges on the same technologies and deployment methodology that you’re using already for transformations and the resulting datasets are easy to reason about.
It is clear that there’s huge value in these semantics and that the cost of maintaining this layer is substantial. Generally the trend is for these semantics to move closer or into the transform layer, be progressively adoptable, be managed in source control as opposed to GUIs, and the need for it to become less siloed/duplicated. Looking forward to digging deeper in a future blog post.
Decentralized Governance
For the longest time, central data teams were responsible for maintaining data systems and making data assets available to the rest of the organization. Increasingly, mid to large organizations have been feeling the pain of centralization (data bureaucracy!).
Whether you call it data mesh or more generally “decentralized governance”, teams of domain experts are starting to own and drive data systems. Each team will start to be responsible for data quality SLA’s and publishing metrics and dimensions for the rest of the organization to consume.
Central data & data engineering teams have a critical role to play here. Not every team in an organization will be equipped day one to be accountable for maintaining their data assets. After all, with great power comes great responsibility! Members of the central data and data engineering teams will play a big role in mentoring, educating, and empowering the rest of the organization with best practices.
One big challenge is that the matrix of how teams relate to “subject areas” (or more atomically to the “bus matrix” of dimensions and metrics) is extremely intricate. It turns out that it’s not always clear who should own what as everything here is tangled in a web of interest and dependencies. Drawing clear lines isn’t easy when possible at all.
It’s a huge mes(s/h)!
Clearly there are parallels and learning to be drawn from the microservice world but things don’t translate as easily given stronger gravitational forces around data. Let’s explore this in a follow up post.
Every product is becoming a data product
Customers of software now expect to interact with the data they and their team are generating in the software. This can range from something as “simple” as an API to something more complex like an analytics dashboard.
Cutting edge companies like Hubspot, Stripe, GitHub, Slack, and others have led the way by introducing analytics products for their customers. The caveat here, however, is that the amount of effort here is colossal. These organizations have had to spin up an entire team to build and maintain customer facing data products, often having to hire frontend engineers, backend engineers, data specialists (viz engineers, data analysts, etc), and product managers.
Moving forward, creating embedded data products is going to become much, much easier. Whether you call it headless BI or productized analytics, I’m excited for the future where tools like Superset will make it easier for teams to rapidly build and iterate on customer facing data products.
Conclusion
We’re just scratching the surface here, which was the intent of this blog post (I wanted to go wide before going deep). In the following posts, I hope to go dig into each of these trends to brainstorm how modern data and data engineering teams will be reshaped as a result of each trend.
Our first deep dive post will cover data infrastructure as a service and data integration services. Stay tuned!
