


What Is the Modern Data Stack? History and Components




The modern data stack is composed of cloud-native applications and serves as the foundation for an enterprise data infrastructure. The concept of the modern data stack has been gaining popularity and has become the method of choice for organizations of various sizes to extract value from data. Just like a physical supply chain, the modern data stack:
- Begins with ingesting data (extraction of raw material)
- Transforming the data (production links like component construction, assembly, and merging)
- Storing the transformed data (storage facilities for goods)
- Productizing the data for consumption (final good reaching consumer)
In this post I’ll introduce the modern data stack and dive into each of the different components (with examples of technologies)!
A Brief History of the Modern Data Stack
For decades, on-premise databases were enough for the limited amount of data companies stored for their use cases. Over time, however, the amount of data storage space needed exponentially increased, requiring companies to find solutions to keep all of the information that was coming their way. This led to the emergence of new technologies that allowed organizations to deal with large amounts of data like Hadoop, Vertica, and MongoDB. This was the Big Data era in the 2000s when systems were typically distributed SQL or NoSQL.
The Big Data era lasted less than a decade when it was interrupted by the widespread adoption of cloud technologies in the early and mid-2010s. Traditional, on-premise Big Data technologies struggled to move to the cloud. The higher complexity, cost, and required expertise of on-premise technologies put them at a disadvantage compared to the more agile cloud data warehouse. This all started in 2010 with Redshift, followed a couple of years later by BigQuery and Snowflake.
Changes that Enabled Adoption of the Modern Data Stack
It is important to remember that the modern data stack as we currently know it is a very recent development in data engineering. Only very recent changes in technology allowed companies to exploit the potential of their data fully. Below we’ll highlight some of the key developments that enabled the wide-spread adoption of the modern data stack.
Rise of the Cloud Data Warehouse/Lakehouse
In 2012, when Amazon’s Redshift launched, the data warehousing world changed forever. The other solutions in the market today, like Google BigQuery, Snowflake, Databricks Lakehouse, and Dremio, followed the revolution set by Amazon. The development of these data warehousing tools is linked to the difference between MPP (Massively Parallel Processing) or OLAP systems like Redshift and OLT systems like PostgreSQL.
So what changed with the cloud data warehouse?
- Speed: cloud data warehouses significantly decrease the processing time of SQL queries. Before Redshift, the slowness of calculations was the main obstacle to the at-scale exploitation of data.
- Connectivity: cloud data warehouses connecting data sources to a data warehouse is much easier in the cloud. On top of that, cloud data warehouses manage more formats and data sources than on-premise data warehouses.
- User accessibility: on-premise data warehouses are managed by a central team. This means that there is restricted or indirect access for end-users. On the other hand, cloud data warehouses are accessible and usable by all target users. This naturally has repercussions at the organizational level. Namely, on-premise data warehouses limit the number of requests to save server resources, limiting the potential to fully exploit available data.
- Scalability: the rise of cloud data warehouses has made it possible to make data accessible to an increasing number of people, democratizing companies within organizations.
- Affordability: the pricing models of cloud data warehouses are much more flexible than traditional on-premise solutions (like Informatica and Oracle) because they are based on the volume of data stored and/or the consumed computing resources.
The Move from ETL to ELT
In a previous post, How The Modern Data Stack Is Reshaping Data Engineering, Max Beauchemin discusses the rise of ELT (extract, load, transform) over ETL (extract, transform, load). In short, with an ETL process, the data is transformed before being loaded into the data warehouse. On the other hand, with ELT, the unstructured data is loaded into the data warehouse before making any transformations. Data transformation consists of cleaning, checking for duplicates, adapting the data format to the target database, and more. Making all these transformations before the data is loaded into the warehouse allows companies to avoid overloading their databases. This is why traditional data warehouse solutions relied so heavily on ETL tools. With the rise of the cloud, storage was no longer an issue, and pipeline management’s costs decreased dramatically. This enabled organizations to load all of their data into a database without having to make critical strategic decisions at the extraction and ingestion phase.
Self-service analytics and data democratization
The rise of the cloud data warehouse has not only contributed to the transition from ETL to ELT but also the widespread adoption of BI tools like Superset, Power BI, Looker, and Tableau. These easy-to-use solutions allow more and more personas within organizations to access data and make data-driven business decisions.
Is a cloud data warehouse all that matters?
It’s essential to remember that merely having a cloud-based platform does not make a data stack a modern data stack. Many cloud architectures fail to meet the requirements to be included in the category. Technologies generally need to meet five main capabilities to be included in the modern data stack:
- Needs to be centered around the cloud data warehouse
- Must be offered as a managed service with minimal set-up effort and configuration from users
- Democratizes data: the tools are built in such a way to make data accessible for as many people as possible within organizations
- Elastic workloads
- Must have automation as a core competency
A Brief Introduction of the Components of the Modern Data Stack
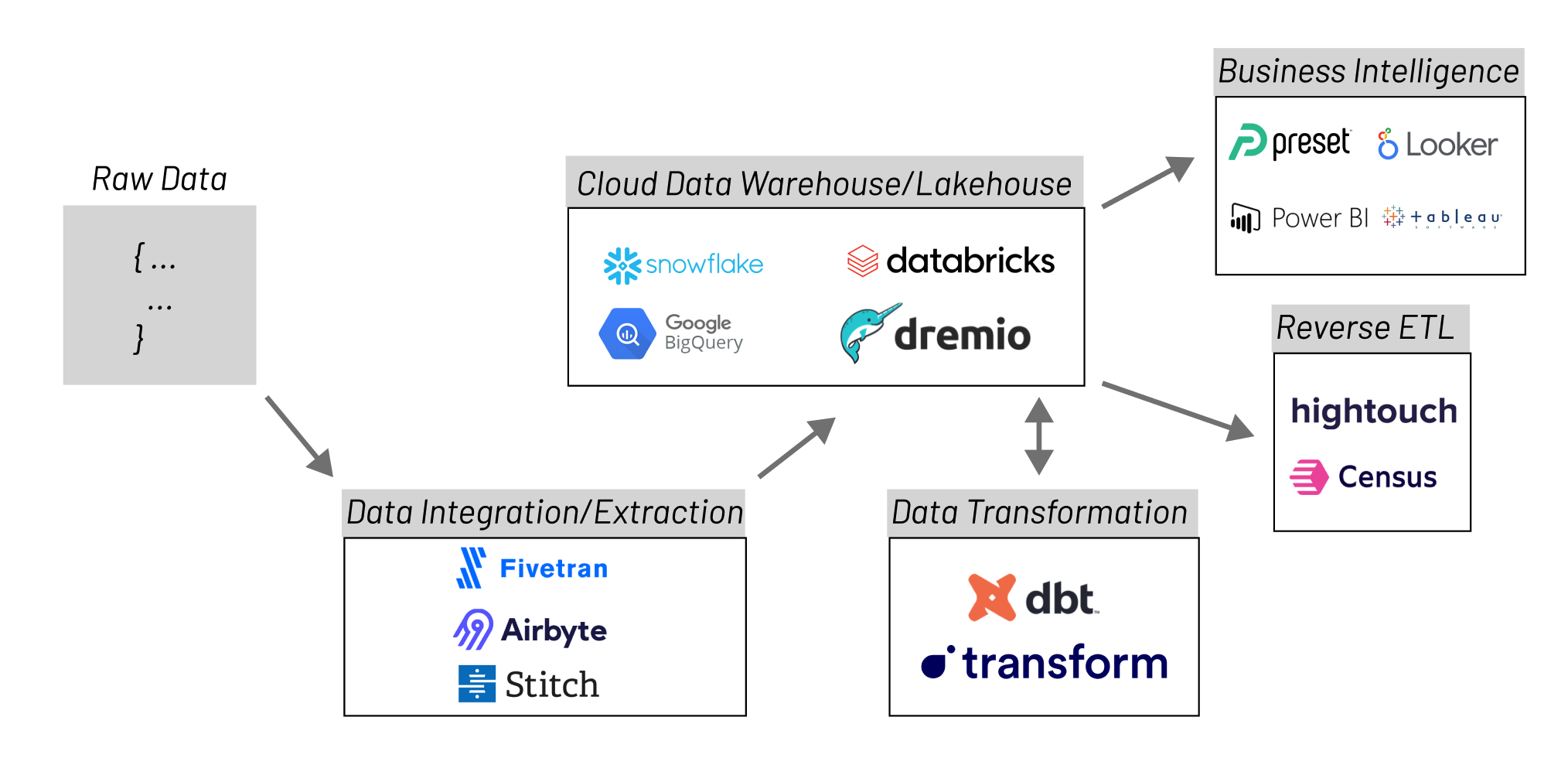
The objective of the modern data stack is to make data more actionable and reduce the time and complexity needed to gain insights from the information in the organization. However, this process is becoming increasingly complex due to the growing amount of modern data stack tools and technologies.
The diagram above is meant to only be an example of a possible architecture of a modern data stack. The individual components can vary, but they usually include the following:
Data Integration
Main tools: Airbyte, Fivetran, Stitch
Organizations collect large amounts of data from various systems like databases, CRM systems, application servers, etc. Data integration is the process of extracting and loading the data from these disparate source systems into a single and unified view. Data integration can be defined as the process of sending data from across an enterprise into a centralized system like a data warehouse or a data lake in such a way that it results in a single, unified location for accessing all the information that is flowing through the organization.
Data Transformation/Modeling
Raw data is entirely useless if it doesn’t get structured in such a way that allows organizations to analyze it. This means you need to transform your data before using it to gain insights and make predictions about your business.
Data transformation can be defined as the process of changing the format or structure of data. Data can be transformed at two different stages of the data pipeline. Typically, organizations that make use of on-premise data warehouses rely on an ETL process in which the transformation happens in the middle, before the data is loaded into the warehouse.
However, most organizations today make use of cloud-based warehouses, which makes it possible to increase the storage capacity of the warehouse dramatically, allowing companies to store raw data and transform it when needed. This model is called ELT (extract, load, transform).
Orchestration
Once you have decided on the transformations, you need to find a way to schedule them so that they run at your preferred frequency. Data orchestration automates the processes related to data ingestion, like bringing the data together from multiple sources, combining it, and preparing it for analysis.
Data Warehousing
Main tools: Snowflake, Firebolt, Google BigQuery, Amazon Redshift, Databricks Lakehouse, Dremio
Nothing can reach your data without accessing the warehouse, as it is the one place that connects all the other pieces between each other. So, all your data flows in and out of your data warehouse. This is why we consider it the center of the Modern Data Stack.
Reverse ETL
Put simply, reverse ETL is the exact inverse process of ETL. It’s the process of moving data from a warehouse into an external system (like a CRM, an advertising platform, or any other SaaS app) to make the data operational. In other words, reverse ETL allows you to make the data you have in your data warehouse available to your business teams, bridging the gap between the work of data teams and the needs of the final data consumers.
The challenge here is linked to the fact that more and more people are asking for data within organizations. This is why organizations today aim to engage in what is called Operational Analytics, which basically means making the data available to operational teams (like sales, marketing, etc.) for functional use cases. However, the lack of a pipeline moving data directly from the warehouse to the different business applications makes it difficult for business teams to access the cloud data warehouse and make the most out of the available data. The use of the data sitting in the data warehouse is limited to creating dashboards and BI reports. This is where the bridge provided by reverse ETL becomes essential to use your data entirely.
BI & Analytics
Main tools: Superset, Power BI, Looker, Tableau
BI and analytics include the applications, infrastructure, and tools that enable access to the data collected by the organization to optimize business decisions and performance.
Data Observability
Main tools: Monte Carlo, Amazon CloudWatch, Datadog
Data observability has become essential to support and enhance any modern data architecture. As explained in her post, What is Data Observability? 5 Pillars You Need To Know, Barr Moses, CEO and co-founder of Monte Carlo, writes that data observability is a concept from the DevOps world adapted to the context of data, data pipelines, and platforms. Similar to software observability, data observability uses automation to monitor data quality to identify the potential data issues before they become business issues. In other words, it empowers data engineers to monitor the data and quickly troubleshoot any possible problem.
As organizations deal with more data daily, their data stacks become increasingly complex. At the same time, bad data is not tolerated, making it increasingly critical to have a holistic view of the state of the data pipelines to monitor for loss of quality, performance, or efficiency. On top of this, organizations need to identify data failures before they can propagate, creating insights on what to do next in the case of a data catastrophe.
Data observability can take the following forms:
- Observing data & metadata: this means monitoring the data and its metadata and changes in historic patterns and observing accuracy and completeness.
- Observing data pipelines: this means monitoring any changes in the data pipelines and metadata regarding data volume, frequency, schema, and behavior.
- Observing data infrastructure: this means monitoring and analyzing processing layer logs and operational metadata from query logs.
These different forms of data observability help technical personas like data engineers and analytics engineers, but also business personas like data analysts and business analysts.
Why Use a Modern Data Stack?
The ultimate goal of a modern data stack is to provide the ability to proactively analyze your business’s data to improve efficiency and uncover areas of opportunity.
The biggest advantage of transitioning from legacy data stacks to modern data stacks lies in the transition to using cloud-native technologies. Managed cloud services require far less technical configuration by end-users. This in turn promotes end-user accessibility to data as well as the ability to scale with growing data needs without the costly downtime associated with scaling legacy data stacks!
Ultimately, the modern data stack lowers the technical barrier of entry for integrating new data sources or systems. The components of the modern data stack are built out with the needs of the analysts and business users as the top priority. This ends up allowing users of all backgrounds to not only easily use all the different tools, but also administer them without requiring in-depth technical knowledge.
Improved Time to Value of Core BI
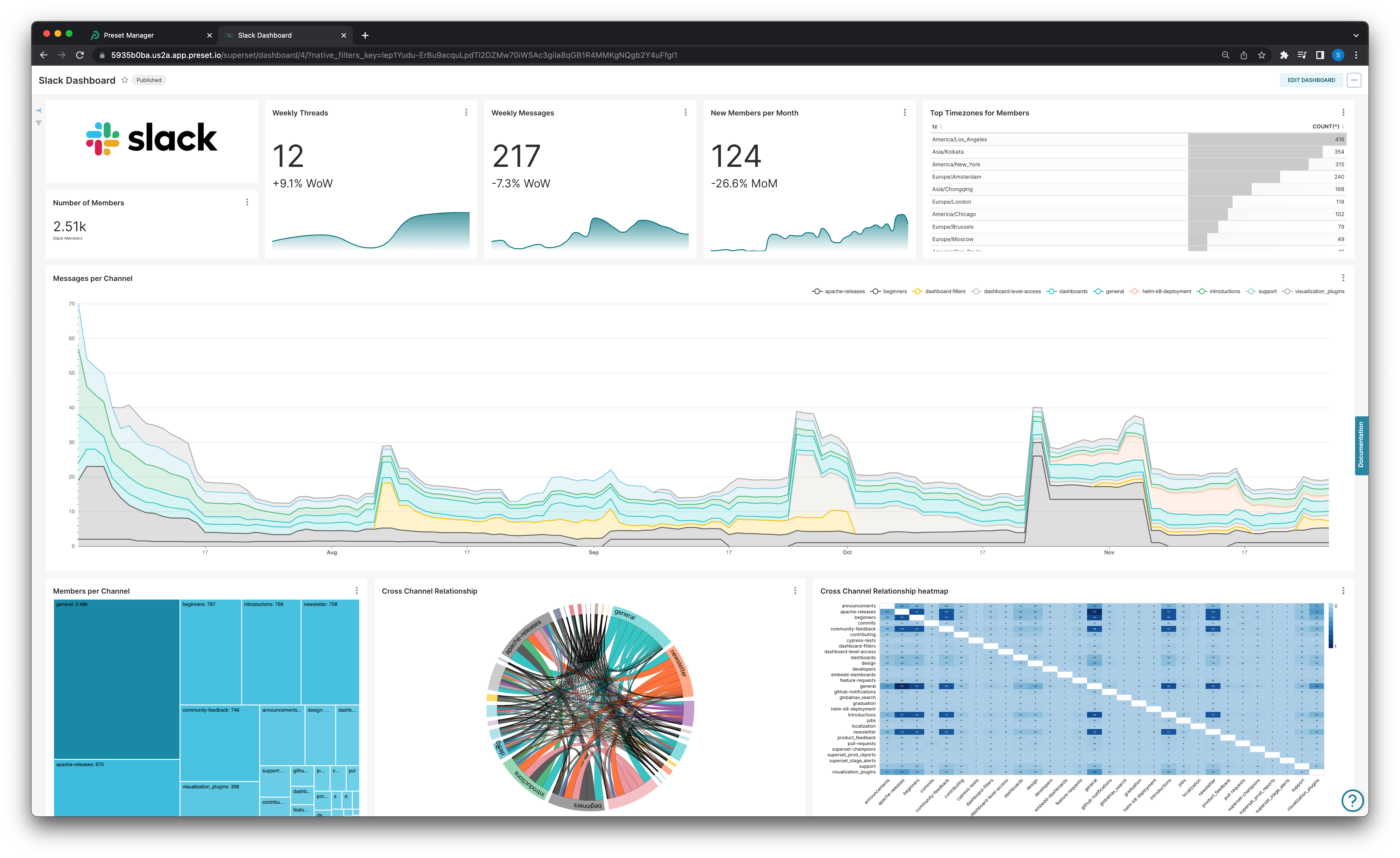
The use of a modern data stack not only democratizes data access, but speeds up the process of enabling core business intelligence use-cases that business users care most about like:
- Improving data comprehension by highlighting patterns, trends, outliers, and key points
- Removing excess noise
- Facilitating faster comprehension
- Making data more accessible, especially when it comes to sharing
- Supporting the storytelling process and helping drive home key ideas
- Allowing a clearer, nuanced understanding of information
- Enabling new insights and conclusions that weren’t possible before
- Capturing and retaining an audience’s attention with engaging charts, maps, and other visualizations
Conclusion
We spoke a lot about the different components and why the modern data stack is on the rise. In our next post in this series about the modern data stack I’ll present a use case in how we at Preset use the modern data stack to visualize our advanced revenue analytics internally!
