


Introducing Promptimize: Test-Driven Prompt Engineering







Visit the GitHub repository to learn about the open-source project, Promptimize.
AI, AGI, LLM, and GPT are the buzzwords of the moment. Like you, I'm excited, concerned, and constantly getting goosebumps as I try to keep up with everything happening in the field. It's time for me to put on my helmet, secure it with duct tape, and contribute something that can help propel this frenzy forward 💪🔥🛷
Thousands of product builders are currently exploring ways to harness the power of AI in the products and experiences they create. The probabilistic, often semi-random, and sometimes chaotic nature of LLMs presents a unique challenge. Although we're still figuring out new patterns, we know that prompt engineering is a key piece of the puzzle. With GPT's vast potential, it's evident that effective prompt engineering is vital for success. This is especially true considering the complexity, risks, and limitations surrounding model tuning.
I firmly believe that product builders can enhance user experiences by taming AI through proper and rigorous prompt engineering. Doing so transforms the probabilistic nature of AI into something more deterministic or predictable, enabling builders to apply a hyperparameter tuning-like mindset and approach to prompt engineering.
To support engineers in this process, I am introducing Promptimize, a Python toolkit designed to measure success and outcomes while doing prompt engineering. With Promptimize, engineers can benefit from an easy-to-use framework to measure the effectiveness of their prompts as they iterate on them, while incorporating ideas and practices more prevalent in test-driven development (TDD) and model tuning.
This blog post is about prompt engineering, its challenges, and the advantages of using Promptimize to support engineers building prompts.
Oh, and I have to note that this was co-authored with ChatGPT4. What a stellar assistant!
Note: The art in the post is inspired by the Promptimize logo and AI-generated by Midjourney.
What’s Prompt Engineering?

Let’s ask ChatGPT:
Prompt engineering is the process of designing and refining input prompts for an AI language model, such as GPT-4, in order to elicit desired responses or improve the quality and relevance of generated output. It involves crafting and experimenting with different phrasings, context, or constraints to guide the model's behavior and optimize its performance for specific tasks or applications.
Prompt engineering can include techniques such as:
- Adding context: Providing additional information or clarifying the purpose of the question to guide the model's response.
- Specifying answer format: Requesting the answer in a specific format (e.g., list, summary, or step-by-step) to focus the output.
- Limiting scope: Narrowing down the topic or specifying the desired level of detail in the response.
- Asking for pros and cons: Encouraging the model to present a balanced view by considering different perspectives.
- Incorporating verification or sourcing: Requesting the model to provide evidence or sources for its claims.
The goal of prompt engineering is to maximize the utility and accuracy of the AI's output while minimizing biases, errors, or irrelevant content. It's an important aspect of using AI language models effectively and responsibly, as it can significantly impact the quality of the generated responses.
Clarifying differences between prompt crafting and prompt engineering
As AI language models like GPT gain popularity, new terms and concepts emerge to describe the various ways we interact with and use these models. Two such terms are "prompt crafting" and "prompt engineering," which, while related, encompass different approaches to working with AI-generated text. It's important to note that these terms are relatively new and potentially unsettled. The following distinctions represent my interpretation and stance on how we should clarify these concepts:
Prompt crafting
Prompt crafting is the art of creating questions or statements for personal interactions with AI models to receive useful and relevant responses. The focus here is on individual use cases, and it requires creativity, intuition, and a basic understanding of the model's limitations. The art of crafting prompts is essential to making the most out of AI models for personal use, as it allows users to refine their questions and receive better results.
Prompt engineering
In contrast, prompt engineering involves a more systematic and technical approach to designing and building systems, applications, or products that use AI models like GPT. Engineers iteratively test and evaluate the performance of prompts, refining them for optimal results within a specific context. Prompt engineering requires programming skills, data analysis expertise, and a deep understanding of the AI model's behavior. This process is essential for developing scalable solutions and optimizing prompts across diverse use cases.
While prompt crafting and prompt engineering share similarities, it's important to recognize the differences between the two. The art of crafting prompts matters for personal interactions with AI models, but the more technical and systematic approach of prompt engineering is key to building effective systems and products that harness the power of AI. By understanding these distinctions, we can better appreciate the roles that both crafting and engineering play in the broader AI field.
While building products
When integrating AI into a product, engineers must iterate and determine the optimal combination of context, system instructions, and user input to achieve the best results. This process also requires the product to dynamically perform "prompt assembly" in real-time.
Note that prompt engineering builds upon crafting methodologies and brings rigor and scaling to them. In other words, it's part art, part science. We're not dealing with a predictable, deterministic API call here. The choice of words, their ordering, the instructions, context, and examples provided can all affect the outcome in complex ways.
From the engineering perspective, prompt engineering involves fetching and formatting external context from the session state, a database, or even integrating with a vector database designed specifically for such use cases. It also means fine-tuning and adjusting elements, as even the slightest alteration to the prompt can dramatically change results in ways that are difficult to predict or control. It's challenging to anticipate or regulate what the AI may answer. Here's a list of factors in the prompt that can significantly alter the response:
- The formatting and ordering of the context can change the answer.
- Emphasizing certain words, such as adding "IMPORTANT!" in front of something or capitalizing a word.
- Too much [dynamically generated] context can lead to AI confusion.
- The "engine" or version of a model can completely change the answers, even when provided the same prompt.
- The "temperature" (not literally, of course!) is a parameter we pass to the API to indicate how "creative" we want the AI to be.
- And countless other factors that are not yet fully understood or controlled.
Some more advanced prompt engineering concepts
Prompt chaining
Prompt chaining is a technique in prompt engineering that involves breaking down a complex task into a series of smaller, more manageable sub-tasks. By sequentially feeding the outputs of one sub-task as inputs to the next sub-task, an AI model can be guided through a series of steps to arrive at a more complex or nuanced response. This technique can help improve the performance of AI models like GPT-4 in generating accurate and contextually appropriate responses.
Agents
Agent serves as a dynamic and adaptable orchestrator that intelligently interacts with various tools and AI models to accomplish complex tasks. Agents have the unique ability to decide which tools to use and determine the next action dynamically based on the output of different tools. By analyzing the context and user input, agents can seamlessly switch between tools or models, ensuring the most appropriate and accurate response is generated.
One of the key strengths of agents is their capacity for self-healing. They can try different options and iterate through various steps until they are satisfied with the output in relation to the task at hand. This self-healing capability enables Agents to tackle challenges, adapt to changing requirements, and consistently deliver high-quality results.
In essence, agents in modern prompt engineering serve as a versatile and powerful intermediary, bridging the gap between user input and AI models or tools. Their ability to dynamically choose and engage with the most suitable tools, combined with their self-healing capabilities, makes agents an essential component in creating more efficient, responsive, and effective AI applications.
Some prompt engineering libs
The development and application of large language models (LLMs) is a rapidly evolving field, making it challenging to keep track of the numerous tools and libraries available. To help navigate the scene, we've enumerated several key resources that can assist developers in tapping the potential of LLMs. The author has personal experience working with LangChain, which appears to be quickly emerging as a leader in the space. Nevertheless, here are some pointers to some of the notable tools in the prompt engeinering space
- LangChain: Assists in developing applications that combine LLMs with other sources of computation or knowledge.
- Dust.tt: Offers a graphical UI and custom programming language for building and processing LLM applications.
- OpenPrompt1: Provides a standard, flexible, and extensible framework for prompt-learning in PyTorch.
- BetterPrompt: Serves as a test suite for LLM prompts before deployment to production.
- Prompt Engine: An NPM utility library for creating and maintaining LLM prompts.
- Promptify: Helps develop pipelines for using LLM APIs in production and solving various NLP tasks.
- TextBox2: A Python and PyTorch-based text generation library for applying pre-trained language models.
- ThoughtSource: A central resource and community for data and tools focused on chain-of-thought reasoning in LLMs.
Test-Driven Development for Prompts: An Essential Aspect

The challenges posed by AI systems, such as their probabilistic nature, make test-driven development (TDD) even more vital in prompt engineering than in traditional software engineering. As AI becomes an integral part of products and user experiences, ensuring predictability and reliability is vital.
Why Test-Driven Development is Essential in Prompt Engineering?
- Embracing unpredictability: Unlike traditional software, AI systems are inherently unpredictable, making it necessary to rigorously test prompts to understand their behavior and outcomes better. TDD in prompt engineering helps manage this unpredictability, ensuring that AI systems provide reliable and consistent results.
- Handling complexity: AI systems are complex, and their outcomes depend on numerous factors, such as engine, model version, temperature, and prompt variations. TDD helps developers systematically test and analyze the impact of these factors, making it easier to identify optimal combinations for specific use cases.
- Reducing risk: The risks associated with AI systems, such as biases and ethical concerns, make testing essential. TDD in prompt engineering can help mitigate these risks by ensuring that the AI system's responses are thoroughly evaluated and refined before deployment.
- Continuous improvement: As AI systems evolve, so do their capabilities and potential use cases. TDD allows prompt engineers to constantly update and improve their prompts, ensuring that the AI system remains effective and relevant.
- Performance measurement: TDD provides a structured approach to measure AI system performance, allowing prompt engineers to identify areas for improvement and make data-driven decisions.
It’s clear that test-driven development plays a central role in prompt engineering, potentially even more so than in traditional software engineering. By embracing TDD, product builders can effectively address the unique challenges presented by AI systems and create reliable, predictable, and high-performing products that harness the power of AI.
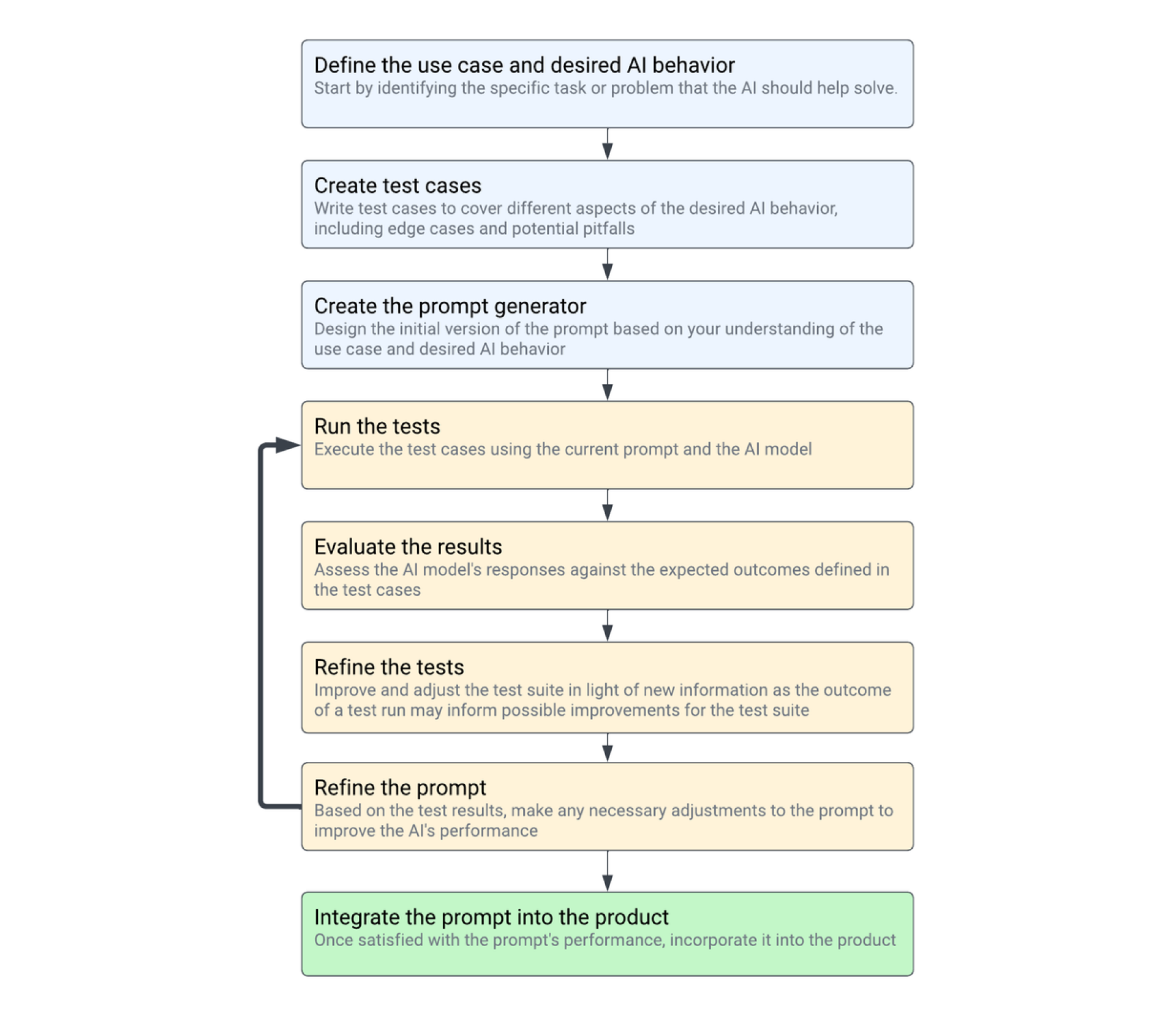
Measuring success while iterating on prompt generation
To build products that harness AI, we must tame this probabilistic beast and integrate it into our more deterministic world. As we craft and fine-tune intricate prompts on behalf of our users and parse the answers to deliver them, we need to take control of the use case space we're trying to cover.
Understanding the importance of prompt engineering and the necessity for a test-driven or heavily tested approach, we must consider the properties and features of a toolkit that would best support engineers in building high-quality prompts with confidence.
Test-driven development vs. test-driven prompt engineering
While several concepts from Test-Driven Development (TDD) can be effectively adapted for prompt engineering, there are some significant distinctions between the two approaches that should be highlighted:
- Determinism vs. Probabilistic Outcomes: In TDD, a well-designed software test case should consistently produce the same result. However, in prompt engineering, the outcome is inherently probabilistic. Even with low
temperaturesettings, the exact same prompt might yield different responses, making it less predictable than traditional software tests. - Binary vs. Gradual Results: Conventional unit tests in TDD yield binary results – either success or failure – and any failures are expected to be addressed. On the other hand, prompt engineering test cases may demonstrate varying degrees of success. Instead of a simple pass/fail, the evaluation should incorporate a success score, ranging from 0 to 1, to better represent the quality of the generated response.
- Objective vs. subjective evaluation: in TDD, software test cases often have objective, quantifiable criteria to determine success or failure. However, in prompt engineering, evaluating the quality of generated responses may involve subjective judgments, as the assessment of output quality can depend on various factors such as context, coherence, and relevance.
- Test Coverage and Complexity: While traditional TDD emphasizes comprehensive test coverage to ensure that all possible code paths are tested, prompt engineering may face a nearly infinite combination of input scenarios. As a result, it is more challenging to design test cases that cover every possibility. Instead, prompt engineering tests should focus on a representative sample of input scenarios to assess the model's performance.
- Debugging and iterative improvement: in TDD, when a test fails, developers can usually pinpoint the exact location in the code that needs improvement or bug fixing. In contrast, prompt engineering is based on complex machine learning models, making it harder to trace the root cause of a specific issue or unexpected output. Improving the model often involves fine-tuning or retraining rather than straightforward code modifications.
Introducing Promptimize!

To address these needs around prompt evaluation and scoring, I created Promptimize and open-sourced it within the same week, as I couldn't find an existing tool that met my requirements.
https://github.com/preset-io/promptimize
Promptimize is a toolkit designed to support prompt engineering and evaluation. You can use it to:
- Define “prompts cases” as code: Promptimize allows users to define their prompts programmatically using Python, making it easier to manage, modify, and reuse prompts across various applications.
- Attach evaluation functions: Users can associate evaluation functions with prompts, enabling objective assessment of generated responses and simplifying the comparison of different prompt variations.
- Generate prompt variations dynamically: the toolkit supports the creation of various prompt variations, helping users experiment with different phrasings, context, or constraints to optimize the model's performance.
- Execute and rank across engines: Promptimize can run prompts on different AI engines and rank the output based on the associated evaluation functions, streamlining the process of identifying the best-performing prompt.
- Report on prompt performance: the toolkit offers reporting capabilities that summarize the performance of different prompts, enabling users to make data-driven decisions and effectively iterate on their prompt designs.
Now that I've piqued your curiosity, I encourage you to visit the Promptimize GitHub repository
to learn more about how it works. The README there contains more detailed and practical information, examples, and step-by-step guides for getting started with the toolkit. By visiting the GitHub page, you'll have access to the most up-to-date information and resources to help you make the most of Promptimize in your prompt engineering endeavors.
Please note that this project, like many in the space, is very young and still settling. Promptimize did not exist a month ago, and the author had not heard of prompt engineering 3 months ago. While it’s a good time to get involved and shape the direction of the project, you have to assume that APIs/CLI will evolve at a dizzying pace.
Promptimize in Action: the Preset Use Case

At Preset, our mission is to enable teams to understand and act on their data effectively. We believe that AI has the potential to significantly enhance our ability to deliver on this mission. To achieve this, we're integrating AI into various aspects of our product, such as natural language data queries, text-to-SQL, and chart suggestions.
Focusing on the text-to-SQL use case specifically, GPT-4 is exceptional at writing code and highly proficient in SQL. However, to perform optimally, GPT requires context. Assembling this context about the database structure, the data itself, and the kind of SQL we want requires a fair amount of prompt crafting and engineering.
Also note that there’s a vast spectrum of database schema size and complexity, different data modeling techniques, a variety of naming conventions, and many SQL dialects. Clearly, this problem space is multidimensional and complex.
Offering a sample taste of the complexity of the text-to-SQL problem is Spider 1.0 - the Yale Semantic Parsing and Text-to-SQL Challenge, self-described as:
Spider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students. The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases. It consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables covering 138 different domains. In Spider 1.0, different complex SQL queries and databases appear in train and test sets. To do well on it, systems must generalize well to not only new SQL queries but also new database schemas.
To address this challenge, we developed an internal SqlLangchainPromptCase class, which inherits from Promptimize's LangchainPromptCase. The SQL specifc logic would:
- Build a solid prompt with Langchaing that
- tells the system about its goals (generate SQL!)
- define SQL formatting rules, including which SQL dialect to use
- define an output schema including hints, query description, confidence,
- show a few, most-relevant examples of good prompt/answers (few-shots)
- provide information about the database table schemas, columns, data types, sample data
- Process and score the results
- receive and run the suggested SQL
- run the Spider-recommended SQL
- compare the result set
- score the test based on whether the dataframes match
To get a glimpse of what using Promptimize looks like, first, let’s look at some output from a $promptimize run spider_sql_prompts.py --output ./sql_report.yaml run.
prompt-c0d5aa66:
key: prompt-c0d5aa66
prompt_kwargs:
input: Which country does Airline "JetBlue Airways" belong to?
dialect: sqlite
db_id: flight_2
query: SELECT Country FROM AIRLINES WHERE Airline = "JetBlue Airways"
category: flight_2
promtp: You are and AI that generates SQL {...REMOVED VERY LONG PROMPT...}
weight: 1
execution:
api_call_duration_ms: 3019.1709995269775
df: |2-
Country
0 USA
exp_df: |2-
Country
0 USA
is_identical: true
run_at: '2023-04-19T00:02:45.287234'
score: 1
response_json:
sql_query: SELECT Country FROM airlines WHERE Airline = 'JetBlue Airways'
hints: You can provide a time period to filter on to get more specific in time
info: This query retrieves the country of origin for the airline 'JetBlue Airways'
from the 'airlines' table.
confidence: '1.0'
error: NoneAt the top, under prompt_kwargs, we see some of the input that was used to generate the prompt itself, at the bottom in response_json you see the structured output from the AI, including not only the SQL query itself, but useful hints and info about the ongoing request that we can surface to the user. You also see execution details, and results from the post-processing and evaluation process, namely the dataframes retrieved from running both SQL queries. Given that the two dataframes are identical, the evaluation function compares them and attributes a score of 1 .
Also note that the command line interface (CLI) subcommand for run offers a lot of options
$ promptimize run --help
Usage: promptimize run [OPTIONS] PATH
run some prompts
Options:
-v, --verbose Trigger more verbose output
-f, --force Force run, do not skip
-h, --human Human review, allowing a human to review and force
pass/fail each prompt case
-r, --repair Only re-run previously failed
-x, --dry-run DRY run, don't call the API
--shuffle Shuffle the prompts in a random order
-s, --style [json|yaml] json or yaml formatting
-m, --max-tokens INTEGER max_tokens passed to the model
-l, --limit INTEGER limit how many prompt cases to run in a single
batch
-t, --temperature FLOAT max_tokens passed to the model
-e, --engine TEXT model as accepted by the openai API
-k, --key TEXT The keys to run
-o, --output PATH
-s, --silent
--helpAlso note that by default, the run command will append/merge to an existing report. If the same prompt was executed before and hasn’t changed, there’s no need to re-run it. This limits the number of API calls and the related execution time and costs. Given this “append/merge” default approach, we have flags like --repair, to force re-execute prompts that failed at scoring positive in the past and a --force to force re-run prompts.
Below, you can see that promptimize can generate reports and provide summaries. Here we’re looking at the sum of the “weight” of the prompt cases, the score, and the percentage achieved. Below is a breakdown by category. For this text-to-SQL use case, we’re using category as the database id on which we’re running the test. Note that it’s also possible to export the atomic report data to a database and perform more complex analysis on any element in the report.
$ promptimize report ./sql_prompts_report.yaml
# Reading report @ ./sql_prompts_report.yaml
+--------+--------+
| weight | 944.00 |
| score | 660.00 |
| perc | 69.92 |
+--------+--------+
+------------------------------+----------+---------+--------+
| category | weight | score | perc |
|------------------------------+----------+---------+--------|
| world_1 | 112 | 61.00 | 54.46 |
| car_1 | 92 | 49.00 | 53.26 |
| dog_kennels | 74 | 42.00 | 56.76 |
| flight_2 | 73 | 55.00 | 75.34 |
| cre_Doc_Template_Mgt | 72 | 57.00 | 79.17 |
| student_transcripts_tracking | 69 | 40.00 | 57.97 |
| wta_1 | 56 | 40.00 | 71.43 |
| network_1 | 50 | 35.00 | 70.00 |
| tvshow | 49 | 39.00 | 79.59 |
| concert_singer | 45 | 35.00 | 77.78 |
| pets_1 | 42 | 35.00 | 83.33 |
| poker_player | 38 | 38.00 | 100.00 |
| orchestra | 32 | 26.00 | 81.25 |
| employee_hire_evaluation | 32 | 29.00 | 90.62 |
| singer | 28 | 20.00 | 71.43 |
| course_teach | 28 | 22.00 | 78.57 |
| museum_visit | 17 | 13.00 | 76.47 |
| battle_death | 16 | 9.00 | 56.25 |
| voter_1 | 15 | 14.00 | 93.33 |
| real_estate_properties | 4 | 1.00 | 25.00 |
+------------------------------+----------+---------+--------+With this versatile prompt case suite, users can quickly explore various aspects of their prompts and answer key questions such as:
- Which is the best-performing model available?
- How does adjusting the
temperatureparameter impact outcomes? - Which prompt cases are positively or negatively affected when I change a specific aspect of the prompt?
- How well does the new prompt version perform with sensitive use cases?
- What happens to the prompt's performance if I don't provide sample data?
- Should I deploy this new prompt in production?
Given our use case, Promptimize empowers our product builders to make informed decisions, measure progress while iterating, and ultimately integrate AI into their products with confidence
Conclusion

In this blog post, we have explored the significance of prompt engineering in the realm of AI-powered products and the distinct challenges it poses. We've discussed the vital role test-driven development (TDD) plays in managing the unpredictability and complexity of AI systems while ensuring their reliability and performance.
Promptimize addresses these challenges by offering a comprehensive toolkit for prompt engineering and evaluation. Equipped with robust features, such as programmable prompt assembly, dynamic prompt generation, response evaluation, and reporting capabilities, it enables developers to confidently harness the power of AI.
As demonstrated with the Preset use case, Promptimize has proven to be an invaluable tool in our product development process, even in its early stages. It allows us to iterate rapidly and effectively integrate GPT into our prototypes and products.
If you're interested in learning more about Promptimize, we encourage you to visit the GitHub repository. The README provides a comprehensive overview of the toolkit, and you'll find everything you need to get started with Promptimize and enhance your prompt engineering process.
We believe the future of AI-powered products lies in the effective collaboration between humans and machines. Promptimize is our contribution towards making that future a reality. Join us on this journey and unlock the full potential of AI in your own projects.
Related Reading
- Building Preset AI Assist — How we used Promptimize to build our production text-to-SQL feature
- AI in BI: the Path to Full Self-Driving Analytics — The broader vision for AI-powered analytics
- GPT x Apache Superset — Early experiments that led to these developments
