


Checklist for Improving the Superset Integration for a Database




In the early days of the Apache Superset project, the tool could only query Apache Druid using it’s native API. Over time, Apache Druid learned to speak SQL and there was also a desire from the early adopters to extend Superset to support more databases.
Today, Apache Superset supports a LOT of databases, including nearly all of the popular SQL speaking databases. Here's a picture of just a fraction of the supported databases:

In an earlier post, Building Database Connectors for Superset Using SQLAlchemy, I wrote about how Superset talks to SQL databases using:
- a SQLAlchemy dialect + a companion Python DB-API 2 library to enable basic functionality
- some database-specific engine code to enable all features (called
db_engine_specin Superset)
Using CrateDB as a reference point, I showcased the mandatory and highly recommended properties and methods that need to be implemented in the custom database engine.
In this post, I”ll walkthrough the full checklist that covers the rest of the properties and methods you can implement in a database engine to improve the experience in Superset!
Mandatory
To quickly recap:
- To generate queries, Superset has an API layer that lives in superset/db_engine_specs. The base API that's common for all databases is exposed in superset/db_engine_specs/base.py.
- To better support the nuances of each database, individual database engines can be extended using BaseEngineSpec. Each database engine should live in a separate file (e.g. bigquery.py for Google BigQuery and clickhouse.py for ClickHouse).
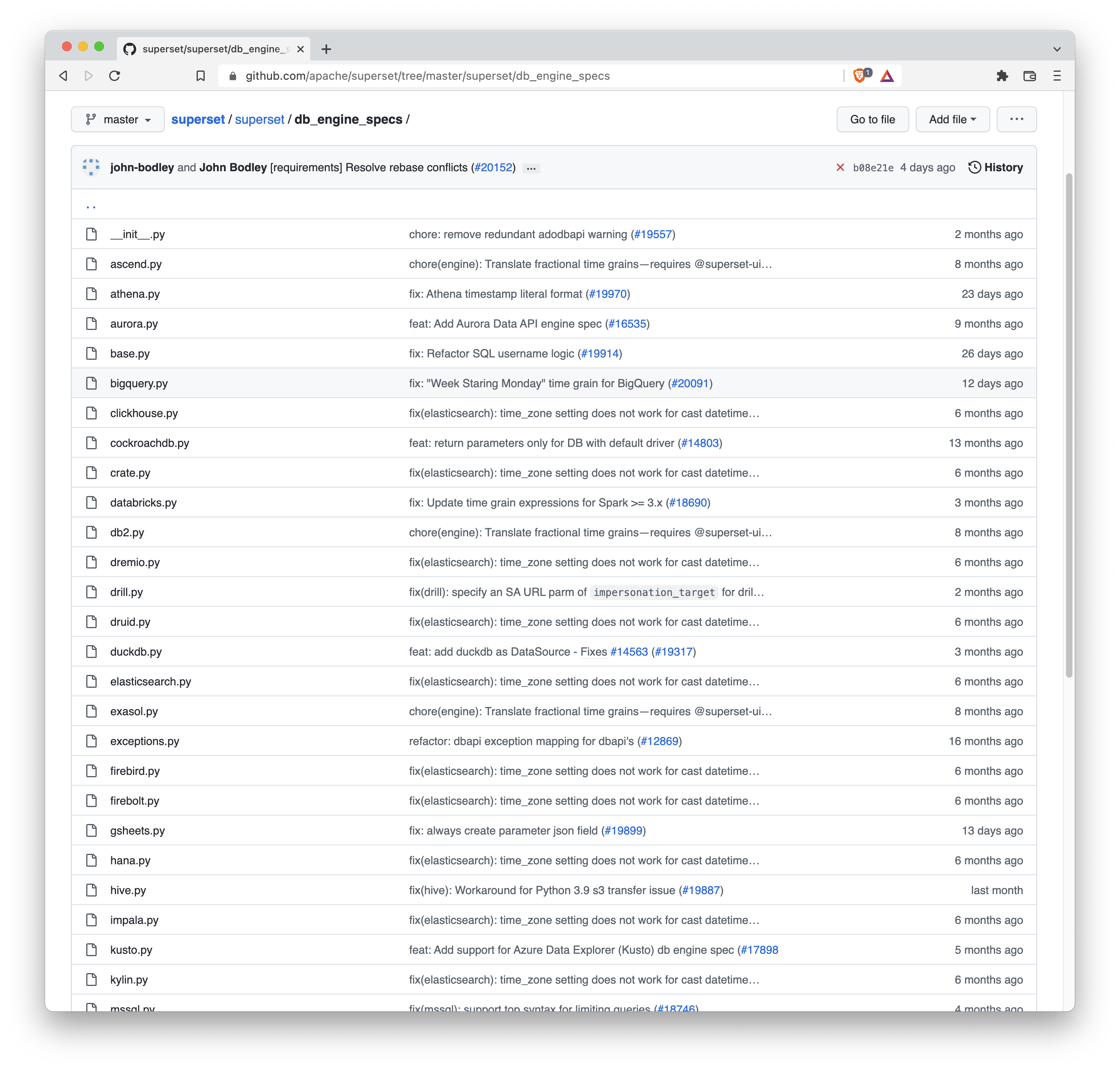
- At a minimum, a custom database engine needs to have the following attributes set so the database is shown in the Add Database modal (if the database driver is installed):
engineengine_name
Here’s a screenshot of this in action from the CrateDB database engine:
Highly Recommended
Next up are a set of properties and functions that are core the Superset experience and are highly recommended to implement.
Time Grain Expressions
Superset’s roots are in time series visualization, where slicing time by specific time grains is a critical feature.
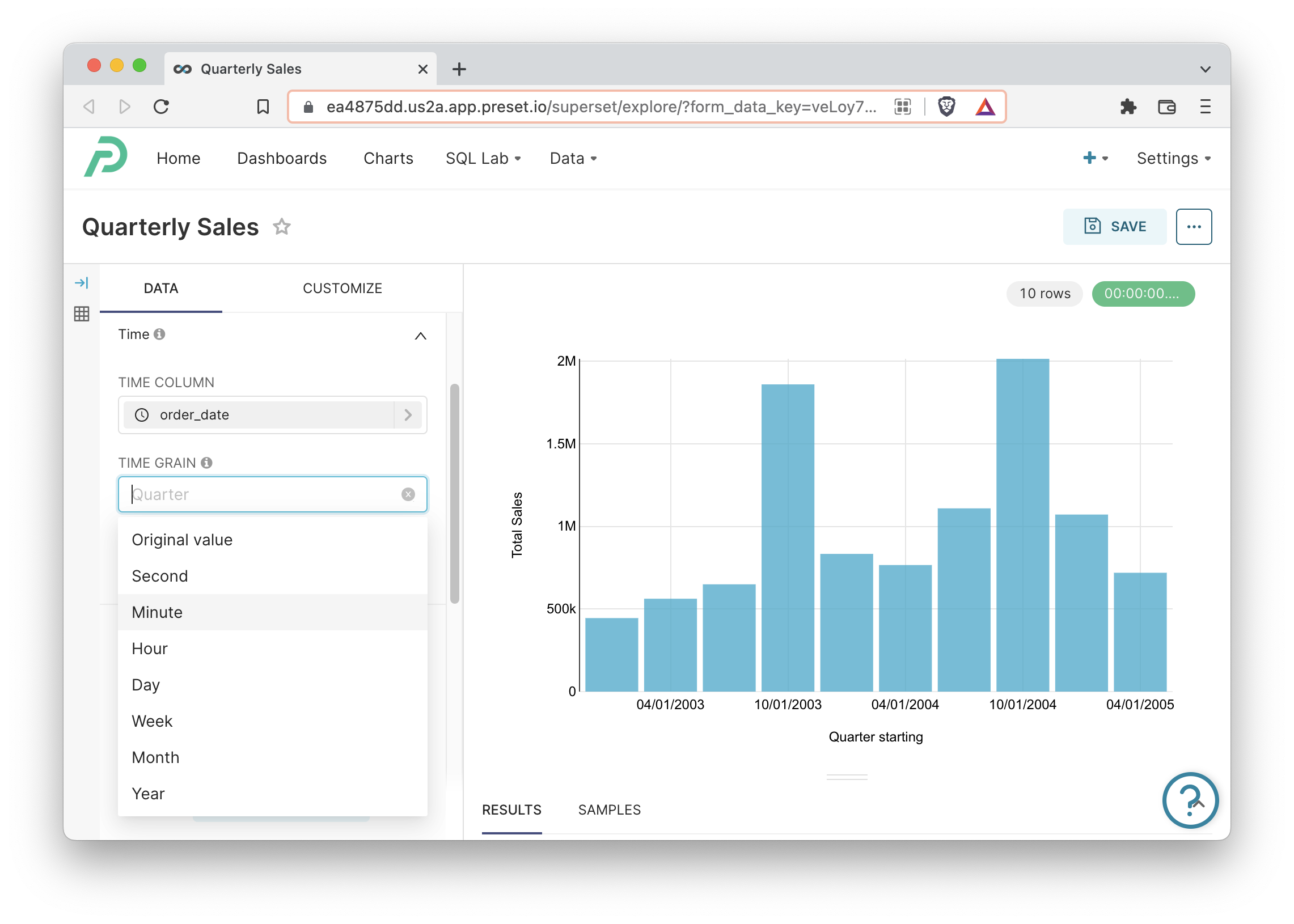
If you want people to create time-series charts and choose the granularity of the time bucketing in Explore, then you’ll need to define the _time_grain_expressions dictionary as a class attribute.
- class attribute:
_time_grain_expressions- Dictionary that defines the mapping from ISO-8601 durations to SQL expression that truncate a temporal value to the specified time grain.
The following is a reference from the BaseEngineSpec class:
builtin_time_grains: Dict[Optional[str], str] = {
None: __("Original value"),
"PT1S": __("Second"),
"PT5S": __("5 second"),
"PT30S": __("30 second"),
"PT1M": __("Minute"),
"PT5M": __("5 minute"),
"PT10M": __("10 minute"),
"PT15M": __("15 minute"),
"PT30M": __("30 minute"),
"PT1H": __("Hour"),
"PT6H": __("6 hour"),
"P1D": __("Day"),
"P1W": __("Week"),
"P1M": __("Month"),
"P3M": __("Quarter"),
"P1Y": __("Year"),
"1969-12-28T00:00:00Z/P1W": __("Week starting Sunday"),
"1969-12-29T00:00:00Z/P1W": __("Week starting Monday"),
"P1W/1970-01-03T00:00:00Z": __("Week ending Saturday"),
"P1W/1970-01-04T00:00:00Z": __("Week_ending Sunday"),
}Here’s an example implementation from CrateDB that implements a subset of these:
_time_grain_expressions = {
None: "{col}",
"PT1S": "DATE_TRUNC('second', {col})",
"PT1M": "DATE_TRUNC('minute', {col})",
"PT1H": "DATE_TRUNC('hour', {col})",
"P1D": "DATE_TRUNC('day', {col})",
"P1W": "DATE_TRUNC('week', {col})",
"P1M": "DATE_TRUNC('month', {col})",
"P3M": "DATE_TRUNC('quarter', {col})",
"P1Y": "DATE_TRUNC('year', {col})",
}Convert Python DateTime to SQL Expression
Superset’s backend is written in Python and this function is needed to help bridge the Python-SQL conversion.
- class method:
convert_dttm()defines how to convert a Python date or datetime object to a SQL expression
Here’s an example implementation from CrateDB:
@classmethod
def convert_dttm(
cls, target_type: str, dttm: datetime, db_extra: Optional[Dict[str, Any]] = None
) -> Optional[str]:
tt = target_type.upper()
if tt == utils.TemporalType.TIMESTAMP:
return f"{dttm.timestamp() * 1000}"
return None Convert Epoch Value to DateTime
SQL expression that converts an epoch Unix time (seconds since 1970-01-01) to a datetime type.
- class method:
epoch_to_dttm()
Here’s an example implementation from CrateDB:
@classmethod
def epoch_to_dttm(cls) -> str:
return "{col} * 1000"Customize SQLAlchemy String
A user registers a new database to connect to in Superset either by manually typing the SQLAlchemy connection string or by filling out a form in the Add Database screen that builds the string on the user’s behalf.
If the SQLAlchemy connection string needs to be customized somehow (e.g. for connecting to a specific schema in the database), then the following function is the right place to define this logic.
- class method:
adjust_database_uri
Here’s an example implementation from Presto that mutates the connection string and appends / followed by the selected_schema value:
@classmethod
def adjust_database_uri(
cls, uri: URL, selected_schema: Optional[str] = None
) -> None:
database = uri.database
if selected_schema and database:
selected_schema = parse.quote(selected_schema, safe="")
if "/" in database:
database = database.split("/")[0] + "/" + selected_schema
else:
database += "/" + selected_schema
uri.database = databaseRecommended
Next up in the checklist is a set of recommended methods & properties.
Better Database Exceptions
Superset talks to databases to run queries using the Python DB-API 2.0 driver for that specific database. Sometimes, the DB-API driver returns an error / exception (e.g. if the query contains syntax errors). Exceptions from the Python DB-API driver can be mapped to Superset exceptions to provide better feedback to end-users in Superset.
- class method:
get_dbapi_exception_mapping()
Here’s an example from the ElasticSearch database engine:
@classmethod
def get_dbapi_exception_mapping(cls) -> Dict[Type[Exception], Type[Exception]]:
# pylint: disable=import-error,import-outside-toplevel
import es.exceptions as es_exceptions
return {
es_exceptions.DatabaseError: SupersetDBAPIDatabaseError,
es_exceptions.OperationalError: SupersetDBAPIOperationalError,
es_exceptions.ProgrammingError: SupersetDBAPIProgrammingError,
}The dictionary above tells Superset how to translate the exceptions from the elasticsearch driver to the Superset exceptions. Also notice the exception classes that were importing from Superset at the top of the database engine:
from superset.db_engine_specs.exceptions import (
SupersetDBAPIDatabaseError,
SupersetDBAPIOperationalError,
SupersetDBAPIProgrammingError,
)Column Type Mappings
Many databases implement custom data types for columns and need to be mapped to both SQLAlchemy types and the GenericDataType in Superset. Note that the BaseEngineSpec that all database engines inherit from cover most of the typical ANSI SQL column types like CHAR, VARCHAR, INT, etc so only non-standard types need to be handled in the database engine. At the time of writing, only three database engines in Superset implement column type mappings: MySQL, Postgres, and Presto.
- attribute:
column_type_mappings: Tuple[ColumnTypeMapping, ...]
Let’s look at a simple example from PostgresEngineSpec:
column_type_mappings = (
(
re.compile(r"^double precision", re.IGNORECASE),
DOUBLE_PRECISION(),
GenericDataType.NUMERIC,
),Here’s a breakdown of each tuple value:
re.compile(r"^double precision", re.IGNORECASE): a regular expression that matches against text like “double precision”DOUBLE_PRECISION(): the double precision type from Postgres SQLAlchemyGenericDataType.NUMERIC: the simplified Superset data type we want it mapped to
Superset has a few GenericDataTypes that all column types map to simplify things for visualization:
- NUMERIC
- STRING
- TEMPORAL
- BOOLEAN
This can be found in the class definition for GenericDataType.
Here’s a preview of the base template from BaseEngineSpec, which maps a lot of the standard column types:
column_type_mappings: Tuple[ColumnTypeMapping, ...] = (
(
re.compile(r"^string", re.IGNORECASE),
types.String(),
GenericDataType.STRING,
),
(
re.compile(r"^n((var)?char|text)", re.IGNORECASE),
types.UnicodeText(),
GenericDataType.STRING,
),
(
re.compile(r"^(var)?char", re.IGNORECASE),
types.String(),
GenericDataType.STRING,
),
.....
)From the 3 tuples above, we can see that column types that look like “string”, “nchar”, “varchar”, and “text” will be mapped to different SQLAlchemy types but the same Superset GenericDataType (of String!).
Convert Epoch Value (in Milliseconds) to DateTime
SQL expression that converts an epoch Unix time (seconds since 1970-01-01) in milliseconds to a datetime type. Note the difference between this and epoch_to_dttm from the earlier section in this post!
- class method:
epoch_ms_to_dttm()
Here’s an example implementation from CrateDB:
@classmethod
def epoch_ms_to_dttm(cls) -> str:
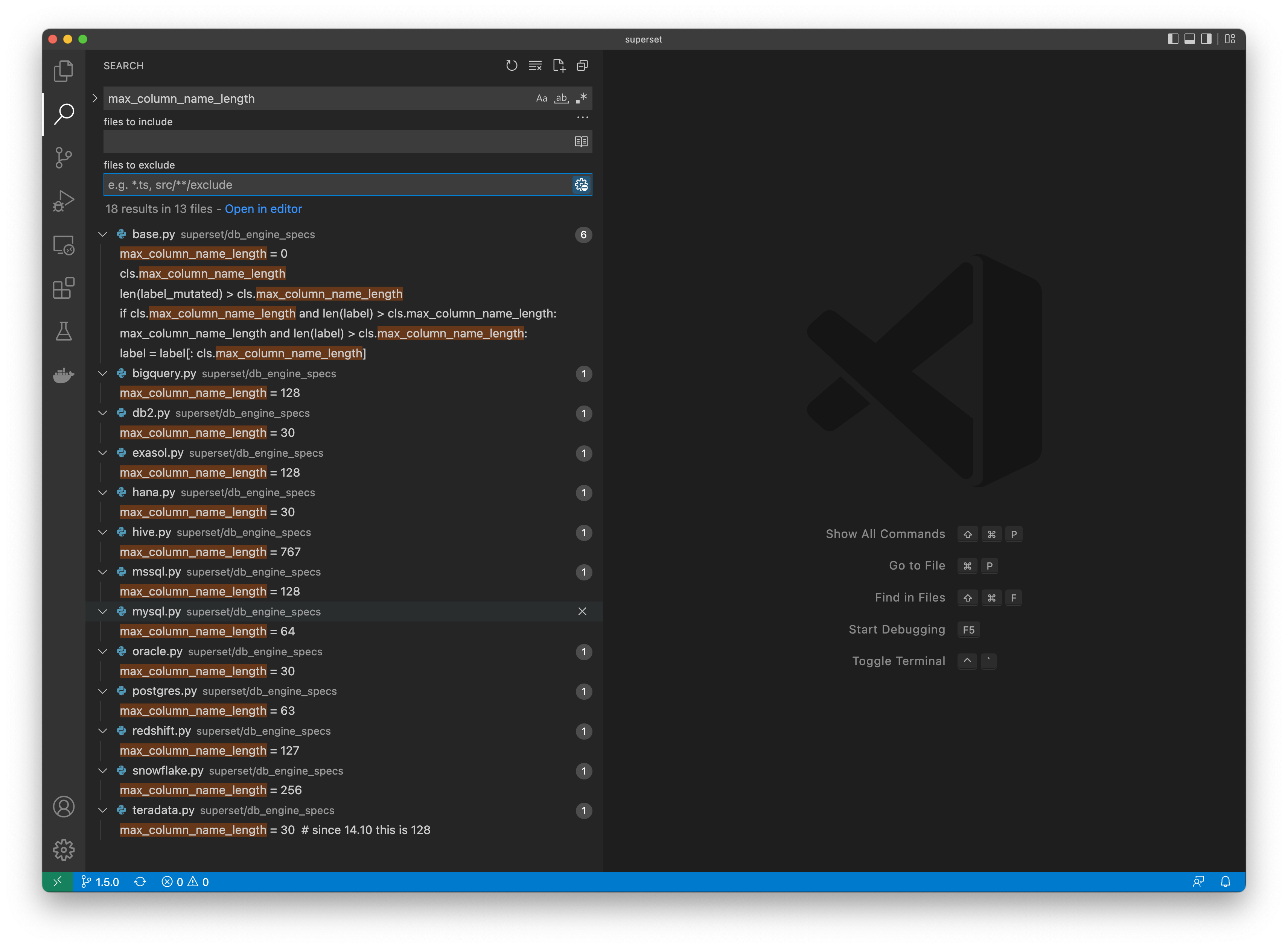
return "{col}"Max Column Name Length
Databases often have different limitations on how long a column name or alias can be. When a column name or alias exceeds this value, it’ll be replaced by a truncated MD5 hash representation of the full, untrucated column name or alias at query time to ensure that the query can be executed.
- attribute:
max_column_name_length(integer value)
In the following screenshot, you can see the diversity of column name lengths that different databases support.
Optional (Nice to Have)
Lastly, you can specify a list of function names to aid in auto-completion in SQL Lab (Superset’s SQL Editor):
- class method:
get_function_names()
Here’s how ClickHouse implements this function in ClickhouseEngineSpec:
@classmethod
@cache_manager.cache.memoize()
def get_function_names(cls, database: "Database") -> List[str]:
system_functions_sql = "SELECT name FROM system.functions"
try:
df = database.get_df(system_functions_sql)
if cls._show_functions_column in df:
return df[cls._show_functions_column].tolist()
columns = df.columns.values.tolist()
logger.error(
...Interestingly, ClickHouse has a way to return the list of functions using SQL and that feature is used here to return the list of available functions for auto-completion.
Checklist
Here’s a shortened, glanceable checklist to use when building a custom database engine:
Mandatory
- attribute:
engine: name of the SQLAlchemy dialect - attribute:
engine_name: name that should be displayed in the Superset UI
Highly Recommended
- attribute:
_time_grain_expressions: mapping from ISO-8601 durations to SQL expressions that truncate a temporal value to the specified time grain. - class method:
convert_dttm: convert a Python date/datetime object to a SQL expression - class method:
epoch_to_dttm: SQL expression that converts an epoch value to a datetime type - class method:
adjust_database_uri: function to customize the SQLAlchemy connection string if needed (e.g. appending the chosen schema to the connection string)
Recommended
- class method:
get_dbapi_exception_mapping(): mapping from database driver specific exceptions to Superset exceptions to showcase the correct feedback to the end-user. - attribute:
column_type_mappings: tuple of values to map non-standard column types to both the SQLAlchemy type and the Superset GenericDataType - class method:
epoch_ms_to_dttm: SQL expression that converts an epoch value (in milliseconds) to a datetime type - attribute:
max_column_name_length: max length of a column name / alias that the database supports
Optional (Nice to Have)
- class method:
get_function_names: return a list of function names to be used in SQL Lab auto-complete
Long Tail of Other Customization Options
The BaseEngineSpec class from superset/db_engine_specs/base.py is well-documented and contains a lot of documented properties and class methods you may find yourself needing to inherit & over-ride. I recommend referencing it to continue optimizing your specific database’s compatibility in Superset:
Here are some examples that may be relevant for the database you’re hoping to customize the Superset experience for:
- attribute:
allows_cte_in_subquery: if True, then use CTE subquery. If False, use regular CTE. - attribute:
allows_hidden_ordeby_agg: If True, ORDER BY doesn’t need to appear in the SELECT query.
