


Building Database Connectors for Superset Using SQLAlchemy




Unlike some BI tools in the market, Apache Superset doesn't have its own ingestion layer and the platform acts as a thin layer over your existing data stack.
This unlocks a few capabilities:
- Superset can be piloted easily, without needing to setup a pipeline from your data to Superset's ingestion layer (which doesn't exist)! Just point Superset to your data stores and start building charts.
- As your organization grows, so does the data stack & infrastructure. Superset supports the fast moving and dynamic nature of analytical data stores as the organization and the technology landscape changes (the familiar interface of SQL has persisted over decades!).
To query a SQL speaking database, Superset requires:
- a SQLAlchemy dialect + a companion Python DB-API 2 library to enable basic functionality
- some database-specific connector code to enable all features
In this post, we'll walk through these components and use CrateDB as the motivating example.
This post is a companion blog post to the recording from the Building a Database Connector community event.
CrateDB
CrateDB is a relational, time series database focused on the IoT (internet of things) use case.

Because working with time series data was one of the early motivations behind the launch of the Superset project, we expect CrateDB to work quite well with Superset. In addition, the CrateDB team has already done some foundational work connecting CrateDB to Superset!
SQLAlchemy & Python DB-API 2.0
For software that regularly queries databases, the common pattern that's emerged is the adoption of an object-relational mapper (or ORM for short). An ORM acts as middleware that lets the developer write idiomatic code that is translated to the flavor of SQL particular to the database that the developer wants to query.
SQLAlchemy is one of the most popular ORM's out there and it's written in Python. SQLAlchemy enables you to write idiomatic Python code that generates SQL. Here's a great example from the SQL Alchemy documentation.
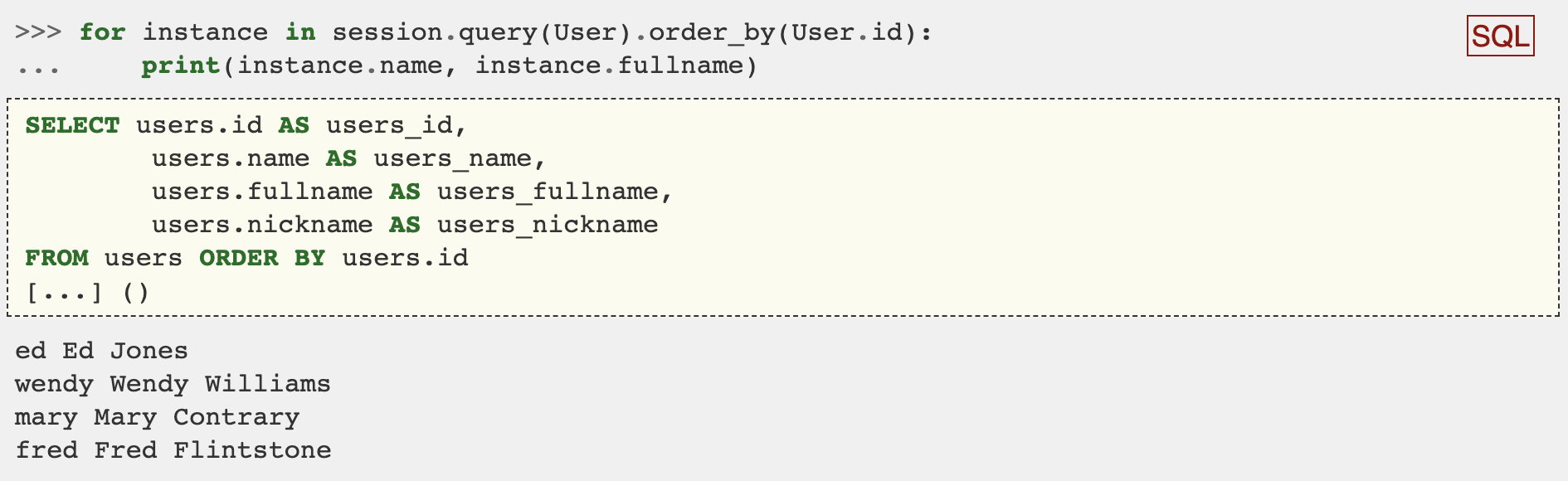
As described in PEP 249, the Python DB-API is an API standard for how Python code should access databases. The main goal of this standard is to promote unity between Python libraries that seek to interact with databases.
The backend components of Superset are all written in Python and the early contributors bet on the SQLAlchemy ORM and the Python DB-API 2 standards to enable the support for the most number of data stores.
In our motivating example, the CrateDB team has already created an excellent Python library called crate that's compliant with both of these standards. You'll need to install it with the sqlalchemy extras in the same environment you're running Superset:
pip install crate[sqlalchemy]==0.26.0If you want to cut straight to the chase and look at the code for the CrateDB example, you can view the PR on Github here.
SQL Lab vs Explore
Superset has two key modes of usage:
- SQL Lab: state-of-the-art SQL IDE for writing SQL queries and viewing the results
- Explore: no-code visualization builder
SQL Lab exposes an IDE that enables SQL speaking analysts to write SQL queries directly to the database and doesn't rely much on the Python DB-API and SQL Alchemy components.
Explore provides a rich UI to enable people to quickly craft charts by selecting options from friendly drop down menus. Superset, using DB-API and SQLALchemy, then uses these options to generate SQL queries on the users' behalf.
Database Engine Specs
To generate queries, Superset has an API layer that lives in superset/db_engine_specs. The base API that's common for all databases is exposed in superset/db_engine_specs/base.py.
To better support the nuances of each database, individual database engines can be extended using BaseEngineSpec.
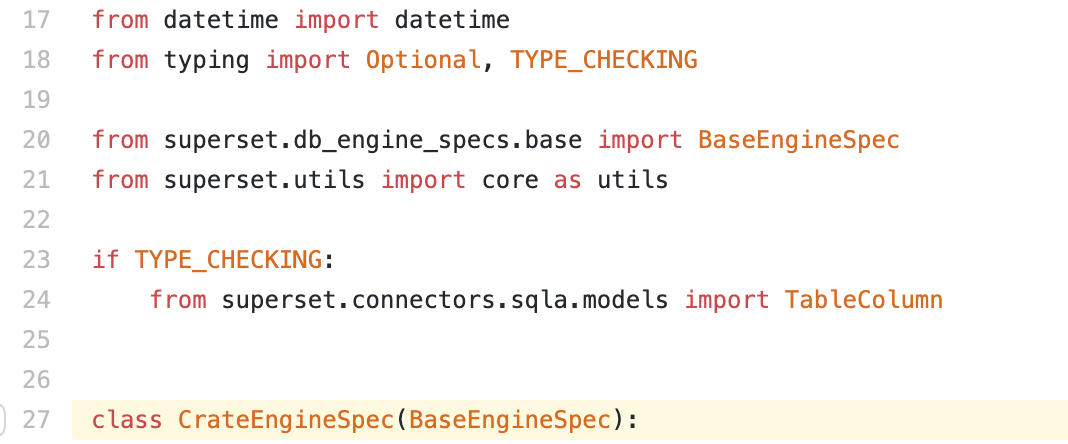
First things first, you'll want to specify the name of the engine name using the engine and engine_name variables. Superset uses this information in a few different places, especially on the front-end!

Next, we highly recommend adding a conversion dictionary for time grains. In Superset Explore, time-oriented charts support the ability to group by time grains like:
- second
- minute
- hour
- day
- week
- month
- quarter
- year
To enable time grain support, Superset needs to understand how to support the proper query augmentation so that values are returned properly. Most databases have a DATE_TRUNC() or similar function to format datetime values with specific time grains.
Superset abides by the ISO 8601 format for datetime expressions. You can set the database specific time grain mappings (from ISO to SQL date truncating functions) by setting the _time_grain_expressions dictionary object.
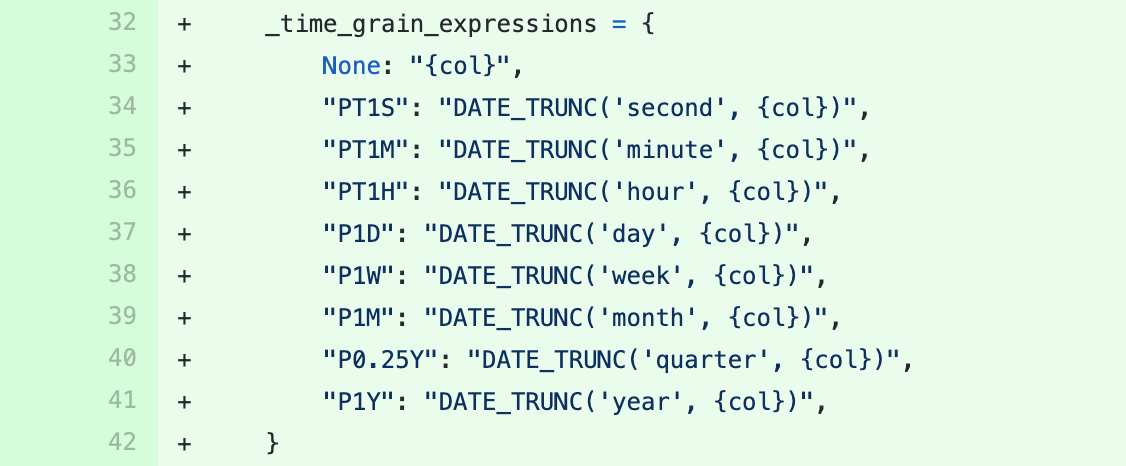
You can find other base class methods to override in base.py
Adding Tests
For each of the class methods that were over-ride in your custom database engine spec, we recommend writing some simple test cases.
In this example, we test the following:
test_convert_dttm()test_epoch_to_dttm()test_epoch_ms_to_dttm()test_alter_new_orm_column()

Adding Documentation
Once you've tested your custom database engine code, the next step is to document it for others to use! If you look at the PR for adding CrateDB support, you'll notice that some very basic documentation was also added.
At a minimum, we recommend listing the Python library that needs to be installed alongside the Superset installation and the connection string in Superset.
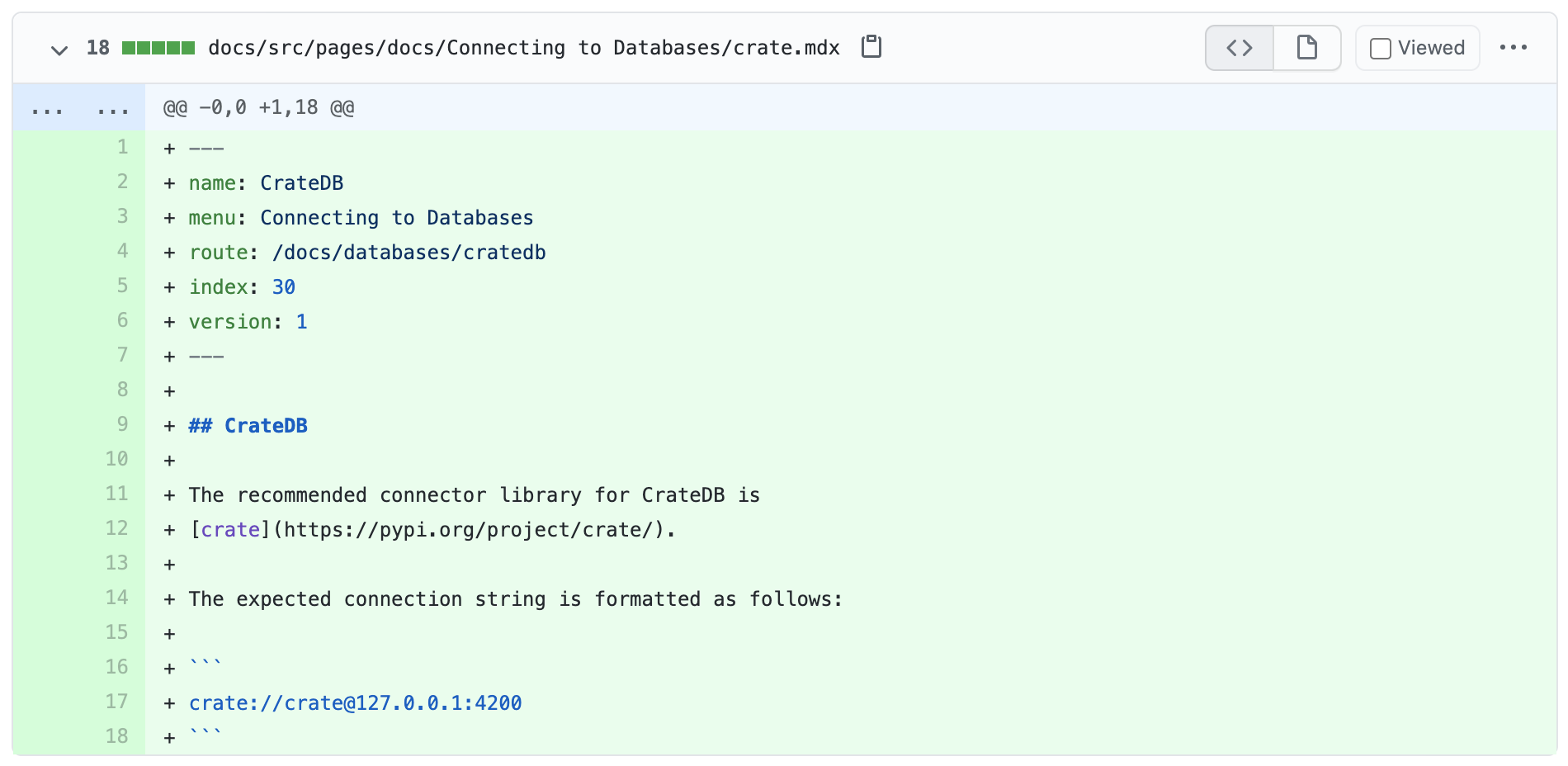
Wrap up by documenting your new connector in the Superset documentation.
Next Steps: Add your own database connectors!
If you're interested in adding foundational or better support for your database in Superset, we recommend running Superset in development mode to enable faster iteration.
We'd also encourage you to join our Slack community and use the #contributing channel to get help!
Related Reading
- Improving Superset Database Integration with SQLAlchemy — More on how Superset connects to databases
- Apache Superset Now Supports Rockset — Example of a database connector in action
- Visualizing ClickHouse Data — Step-by-step database connection tutorial
- How to Contribute to Superset — Getting started as a Superset contributor
