


Deploying Web Applications into Kubernetes with Zero Downtime




At Preset, we run entirely on top of Kubernetes in AWS (EKS). As such, it's only natural that we need a robust and scalable method of exposing services to customers. When we started out back in 2019, we chose nginx-ingress + Elastic Load Balancer (running in layer 4 mode) to ingress traffic into our various services. Nginx-ingress was (and still is) great. It's able to update internal mappings quickly in response to ingress changes, allows for several annotation-based customizations and is, of course built on top of Nginx, which is one of the most scalable web servers available.
This was great while it lasted. Over the past few years, however, Amazon has started deprecating ELB in favor of their new breed of load balancers: (Application|Network) Load Balancers. When used in conjunction with Amazon’s CNI plugin, it’s possible for LB’s to pass traffic directly into pods via their internally routable IPs:
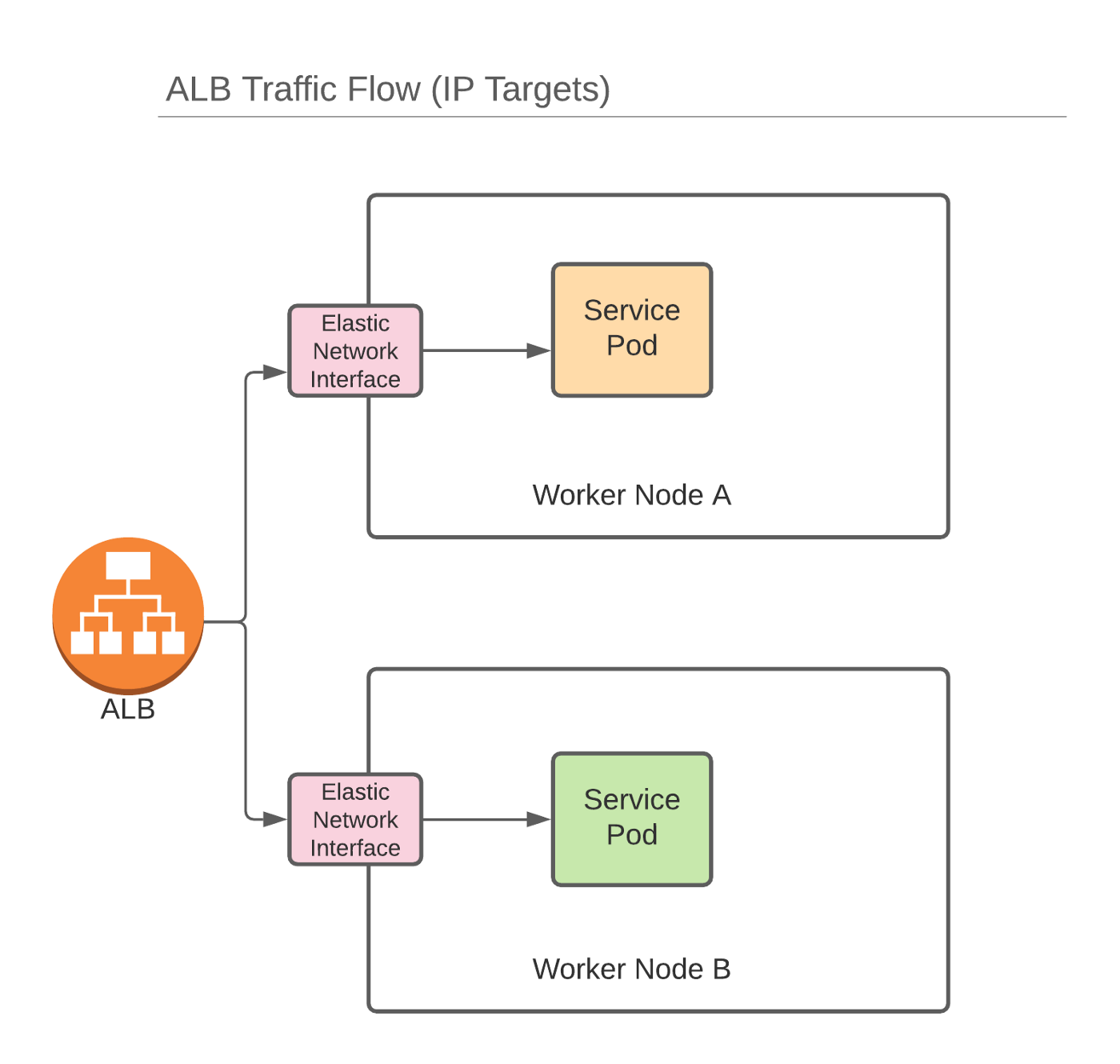
The CNI allocates network interfaces to pods running on worker nodes. This saves network hops and proxying that would normally be required when using kube-proxy and overlay networks. Fewer hops means lower latency:
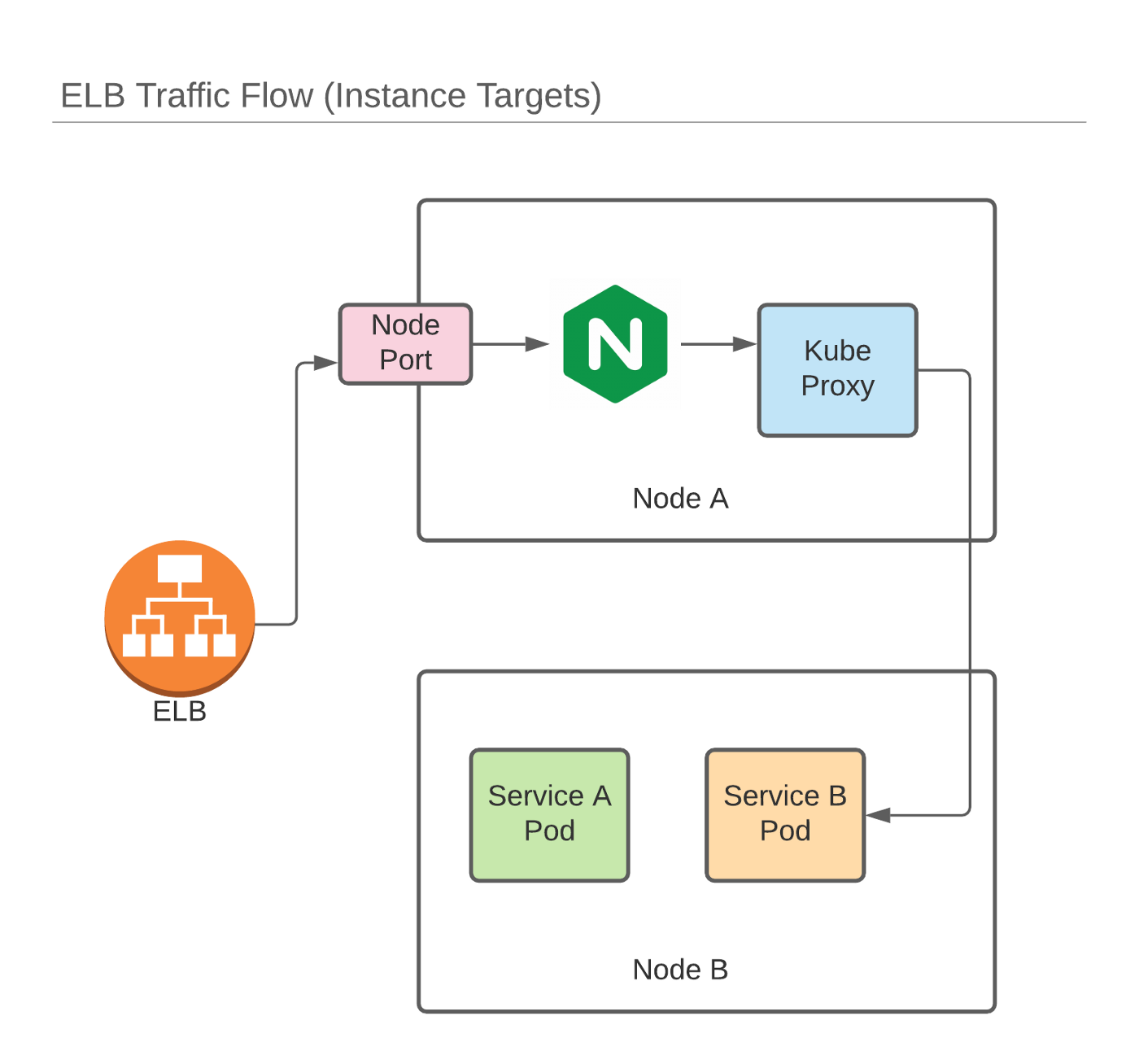
In order to wire things together, we used the AWS Load Balancer Controller. The AWS LB Controller watches for Ingress resources and creates corresponding ALB/NLB instances on their behalf. It then configures target groups using IP targets (alternatively, it can use instance targets). As a new LB is created for each ingress resource, the warm-up period for fresh Ingresses can take several minuets. This is a one time penalty, and doesn’t affect most upgrade operations as you typically don’t re-create Ingress resources on upgrade.
One other side effect of dealing with LoadBalancers and target groups directly is that the addition and removal of pods, targeted by a given Ingress, trigger registration / de-registration of target group instances. In our testing, we noticed that the registration process could take upwards of 30–60s, depending on your health check setup. Further, the de-registration process in ALB requires a minimum of 12s, which means that pods need to stick around long enough for targets to drain properly, otherwise consumers of your services will receive 504 messages from the load balancer.
In order to verify results, we used Vegeta to send some load to services while performing a pod upgrade:
Duration [total, attack, wait] 37.227s, 37.199s, 28.005ms
Latencies [min, mean, 50, 90, 95, 99, max] 24.828ms, 1.826s, 28.646ms, 10.027s, 10.028s, 10.03s, 10.077s
Bytes In [total, mean] 588408, 316.18
Bytes Out [total, mean] 0, 0.00
Success [ratio] 78.24%
Status Codes [code:count] 200:1456 502:86 504:319
Error Set:
502 Bad Gateway
504 Gateway TimeoutAs you can see in the results above, several 504 and 502 responses were returned from the load balancer as targets (pods) died before they could be completely deregistered from the ALB. Note that the image below was taken after the target pods targeted had already died:
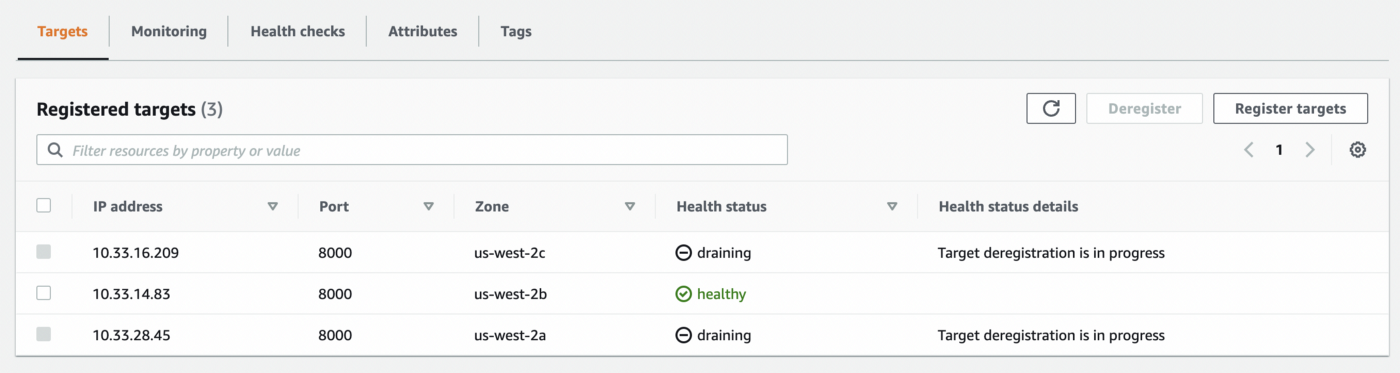
In order to give the ALB a little more time to de-register targets, we implemented a simple sleep mechanism using PreStop Hooks that force the pods to stick around long enough for their corresponding targets to fully deregister from their ALB’s target group:
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- sleep 30Putting all the pieces together, we can now perform rolling deployments of services with zero failed requests and validate our findings as we did above:
Duration [total, attack, wait] 53.355s, 53.319s, 35.181ms
Latencies [min, mean, 50, 90, 95, 99, max] 26.971ms, 31.324ms, 29.729ms, 34.105ms, 37.194ms, 51.099ms, 265.47ms
Bytes In [total, mean] 981456, 368.00
Bytes Out [total, mean] 0, 0.00
Success [ratio] 100.00%
Status Codes [code:count] 200:2667
Error Set:Next Steps
At Preset, we're building a world class data exporation and visualization platform built on top of Apache Superset. Deploying open source software is challenging but rewarding.
If you'd like to work on interesting engineering problems around deploying open source at scale, consider joining us here at Preset.
