


Building Preset AI Assist: Bringing Text-to-SQL to Superset




As recently announced Preset has released its new AI Assist solution, a Text-to-SQL solution to seamlessly turn natural language into SQL queries. In this article, we'll explore the intricacies of building such a solution, the challenges faced in this space, and how Preset's approach is revolutionizing data interaction.
Understanding Text-to-SQL Solutions
Text-to-SQL is not merely a technical challenge; it's a bridge between the fluidity of human language and the precision of SQL. It involves translating natural language queries into structured SQL queries for efficient data retrieval. Preset has taken a strategic and innovative approach with AI Assist, leveraging the power of Language Learning Models (LLMs).
Challenges in the Space
The journey to create a robust Text-to-SQL solution has historically been fraught with intricate challenges, stemming from the fundamental disparities between the fluid, context-dependent nature of human language and the precise, structured syntax of SQL. Early attempts at addressing this gap often focused on treating the problem as a query reformulation task. While these approaches demonstrated promise, they introduced their own set of challenges, requiring extensive curation of datasets containing pairs of human language queries and corresponding SQL statements for effective pre-training or fine-tuning. The need for normalization, both in the input (natural language queries) and the output (SQL queries), added layers of complexity, necessitating pre-processing and post-processing stages that significantly heightened the complexity of the SQL generation.
Before the advent of Language Learning Models (LLMs) for Text-to-SQL, solutions involved template-based approaches and pattern matching, where the system matches the input to one of the pre-defined templates. Once a matching template is identified, the system would fill in the placeholders with the appropriate values extracted from the user input.
Question: "List all products where the price is greater than 100”
Template matched: SELECT * FROM {table} WHERE {column} > {value};
SQL: SELECT * FROM products WHERE price > 100;
With a pattern-matching approach instead, developers must define rules or patterns to recognize SQL components in user queries.
"List" -> SELECT
"all products" -> FROM products
"where the price is greater than" -> WHERE price >
The process required substantial data preparation and manual effort to achieve the necessary format and template, making it a labor-intensive and less flexible solution.
The Paradigm Shift: LLMs
The paradigm shift occurred with the introduction of LLMs, representing a transformative moment in the Text-to-SQL landscape. These models, with their vast knowledge bases and advanced context-understanding capabilities, offered a radical departure from previous methodologies. Demonstrating exceptional performance, LLMs could generate accurate SQL queries from natural language descriptions without the need for meticulously curated training datasets. Their intricate architectures, coupled with extensive data used for pre-training, allowed them to decipher complex relationships between words and contexts, overcoming many challenges inherent in earlier methods.
While the adoption of LLMs has marked a significant leap forward for natural language interaction with databases, the true challenge still exists in refining, optimizing, and providing data context to these models in a reliable manner. Considerations include user intent, dialect-specific elements, efficient database metadata retrieval, and accuracy evaluation.
Preset has put in the work and developed a cutting-edge text-to-SQL solution. It can compete with state-of-the-art approaches, as it's based on the same LLM research papers that power SOTA SQL solutions. Let's dive in.
Preset's Approach to Text-to-SQL Solution
AI Assist, Preset's innovative solution to the complex Text-to-SQL conundrum, significantly evolves data retrieval by integrating LLMs into the process of generating SQL queries from natural language but the path wasn’t clear from the beginning.
The first thing we noticed while developing the solution was the necessity for a deterministic method to evaluate the accuracy of the generated SQL. We had a clear goal of ensuring that at least 75% of the SQL generated was accurate across Postgres, BigQuery, and Snowflake dialects. However, we felt that the accuracy was, at most, 50%. That’s when we started wearing our researcher's hat and started building the foundation for our accuracy evaluation framework.
We were gradually transforming into these new enigmatic entities, prompt engineers!
Prompt Engineering
Prompt engineering plays a key role in AI Assist's Text-to-SQL generation process. It involves numerous revisions of the prompt (the context and instructions given to the Language Model) to achieve the desired output.
An effective prompt consists of several components: precise word choice to guide the Language Model, appropriate context that provides sufficient but not excessive database metadata, and sample data that align with the intent of the input question we are addressing.
It begins with the transformation of user queries and database metadata into vector representations, or embeddings, using the OpenAI embedding service. In simple words, vectors are lists of numbers that represent words or sentences, allowing computers to understand and compare their meanings. These vectors capture the semantic essence of the text, providing a concise, machine-interpretable representation.
To match and retrieve related tables from the database, AI Assist uses cosine similarity, a measure of similarity between two non-zero vectors that allows AI Assist to identify tables that are semantically related to the user query based on their embeddings.
Furthermore, AI Assist employs a Natural Language Processing (NLP)-based similarity search on sample data to ensure that the results generated are relevant. By comparing the user query embeddings with the embeddings of sample data, AI Assist can further refine the SQL query to include specific data points that closely match the user's intent.
Now that the instructions are prepared and the context is complete with all the necessary components, the challenging part begins!
To ensure the accuracy of the SQL queries generated, AI Assist undergoes rigorous testing on the Spider dataset. The Spider dataset is a large-scale, complex, and cross-domain semantic parsing and text-to-SQL dataset, which is widely used in academic research. One notable research paper, "Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task," details the creation and structure of this dataset. This paper illustrates why Spider is an excellent tool for verifying the accuracy of generated queries, as it contains a diverse set of complex SQL queries and corresponding natural language utterances, providing a comprehensive benchmark for testing.
Despite our best efforts and intentions, achieving accuracy doesn't happen instantly. AI Assist's system uses a sequence of requests to the OpenAI API, including dialect transpilation, fixer prompts, and suggestion prompts. Dialect transpilation converts the user's question into a format the model can more easily understand, while fixer and suggestion prompts further refine the generated SQL query.
This multi-step method results in a sophisticated, self-improving text-to-SQL generation pipeline which ultimately brought us to our 75% accuracy target and beyond!
While focusing on accuracy, we recognized the necessity for a scalable solution to manage the embedding process. That's where vector storage and retrieval comes into play for tracking, caching, matching, and retrieving this metadata.
Tracking and Caching
As mentioned earlier, the prompt requires database metadata to assist the LLM in generating a suitable SQL query. For that reason, AI Assist diligently tracks schema changes, table definitions, and sample data modifications. This real-time tracking ensures adaptability to evolving data structures.
We realized that a Retrieval-augmented Generation (RAG) architecture was essential to track and cache database metadata, such as tables, columns, and data types. It is a crucial element of the application as it minimizes the need for repeated and potentially costly database queries to retrieve metadata information each time a user query is processed. By storing this metadata in a cache along with vectors, the LLM can quickly access the necessary information.
The RAG architecture also allows for efficient similarity matching. The database metadata that aligns with the user's intent is identified and retrieved.
We only share the most relevant database information with OpenAI, which includes:
- Schema names
- Tables and column names
- Column types
- Sample data (this is optional and can be disabled in the workspace settings)
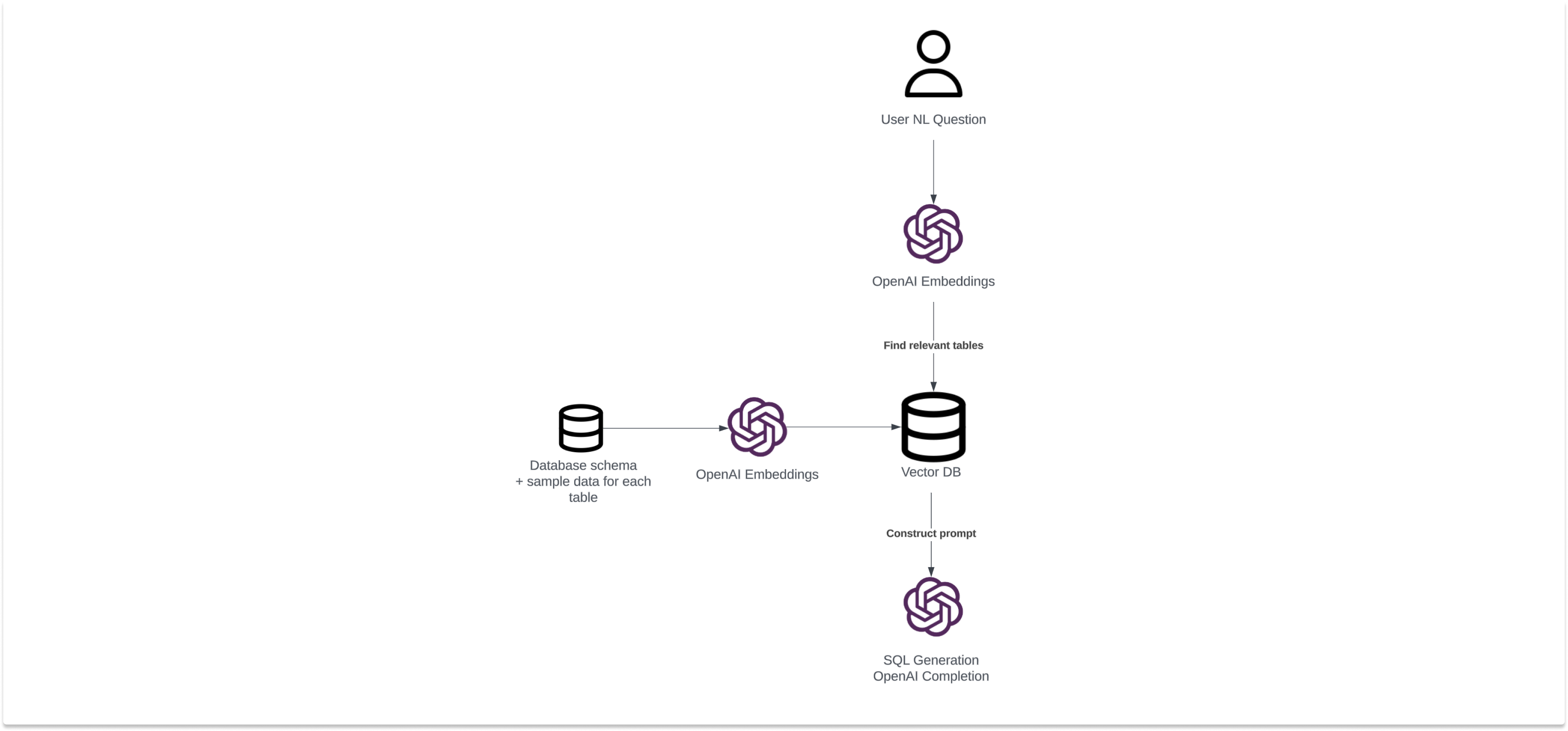
The RAG implementation requires an efficient vector storage solution for storing embeddings and enabling similarity matching and data retrieval. We sought a solution that would seamlessly integrate with our architecture and effectively serve both vector similarity search and data retrieval functions.
Vector DB Solution
Preset employs pgvector for Postgres for individual workspaces, transforming table definitions, comments, and metadata into embeddings to enable our database metadata RAG solution.
Postgres has been an established solution for the Superset metadata database within Preset's ecosystem. As such, the decision to use pgvector, a Postgres extension for high-performance vector computations, was a natural and strategic choice. The existing infrastructure and familiarity with Postgres made it an ideal candidate to seamlessly integrate pgvector.
The advantages of using Postgres and pgvector are manifold. Postgres is renowned for its robustness, reliability, and feature-rich nature, which includes full ACID compliance, views, stored procedures, and a multitude of indexing methods. On the other hand, pgvector adds a crucial dimension to this already powerful database system by facilitating high-speed similarity search on vectors.
When combined, these technologies provide a potent solution for our requirements. The transformation of table definitions, comments, and metadata into embeddings becomes a streamlined process, with pgvector significantly enhancing the efficiency of these operations.
Conclusion: Shaping the Future of BI
As we dive into the technical intricacies of AI Assist, it becomes evident that Preset is not just building a Text-to-SQL solution; we are shaping the future of Business Intelligence (BI). Developers and data-savvy BI professionals can now envision a landscape where natural language seamlessly translates into SQL, opening new frontiers in data exploration and interaction. AI Assist, with its innovative implementation, is set to redefine how we interact with and derive insights from our data, propelling us into a new era of BI excellence. Embrace the revolution – AI Assist is just the beginning of how AI will transform the way you engage with your data on Apache Superset in the cloud.
AI Assist brings considerable benefits to our users:
- SQL writers of any skill level can use AI Assist to get accurate results quickly, thus increasing productivity and efficiency.
- AI Assist aids in locating the appropriate data tables, columns, etc., to use and join, reducing the time spent on manual data exploration.
- The results from queries can be easily saved to a dataset, enabling chart creation and streamlining the data visualization process.
- AI Assist enhances your team’s self-service analytics experience by simplifying data retrieval and exploration, fostering a more data-driven culture within the organization and further democratizing your data by empowering users that are not SQL-fluent.
Get started with AI Assist
Ready to unlock the power of AI in your data analysis? To activate this feature, your team admin needs to enable AI Assist for your workspace.
AI Assist is available for Preset customers on the Professional and Enterprise Plans. This feature is not currently available on the Starter Plan or for Professional trials. Don't have a Preset account yet? You can sign up for a free account today and contact our Sales team to upgrade and gain access to AI Assist.
Related Reading
- Introducing Preset AI Assist — The announcement post for AI Assist
- AI in BI: the Path to Full Self-Driving Analytics — Max's vision for AI-powered analytics
- Introducing Promptimize — Our open-source toolkit for test-driven prompt engineering
- GPT x Apache Superset — Early experiments with LLMs in analytics workflows
