


Accessing APIs with Superset




Back in 2017, when I started working as a Superset developer, one of the most common requests I would receive from users was to add support for accessing data that was stored in Google Sheets.

Google Sheets is not a good database. It’s terrible, actually. It has no transactions, no schema enforcement, no isolation, nothing that a modern database has — because, well, it’s not a database! But it’s great as a spreadsheet, and it has a very user friendly visual interface for inputting data, so sometimes that’s where your data is stored.
But how do you visualize it in a BI tool like Apache Superset?
Shillelagh is the Python library that I wrote to solve this problem. It allows Python programs (like Superset) to treat Google Sheets as a database: each tab in a spreadsheet is accessed like a table, and users can read rows, insert new rows, or even update and delete data.
🍀 A shillelagh (ʃɪˈleɪlɪ) is a wooden walking stick and club or cudgel, typically made from a stout knotty blackthorn stick with a large knob at the top. It is associated with Ireland and Irish folklore. Other spelling variants include shillelah, shillalah, and shillaly.
Because it provides a SQL interface to Google Sheets, and Superset can talk to any database that supports SQL, Shillelagh allows Superset to access a spreadsheet natively. Just use the full Google Sheet URL as a table name in SQL Lab:
> SELECT * FROM "https://docs.google.com/spreadsheets/d/1LcWZMsdCl92g7nA-D6qGRqg1T5TiHyuKJUY1u9XAnsk/edit#gid=0"
country cnt
--------- -----
BR 2
BR 4
ZA 7
CR 11
CR 11
FR 100
AR 42Similarly, it’s possible to create datasets from spreadsheets defined in the “Google Sheets” database connector:
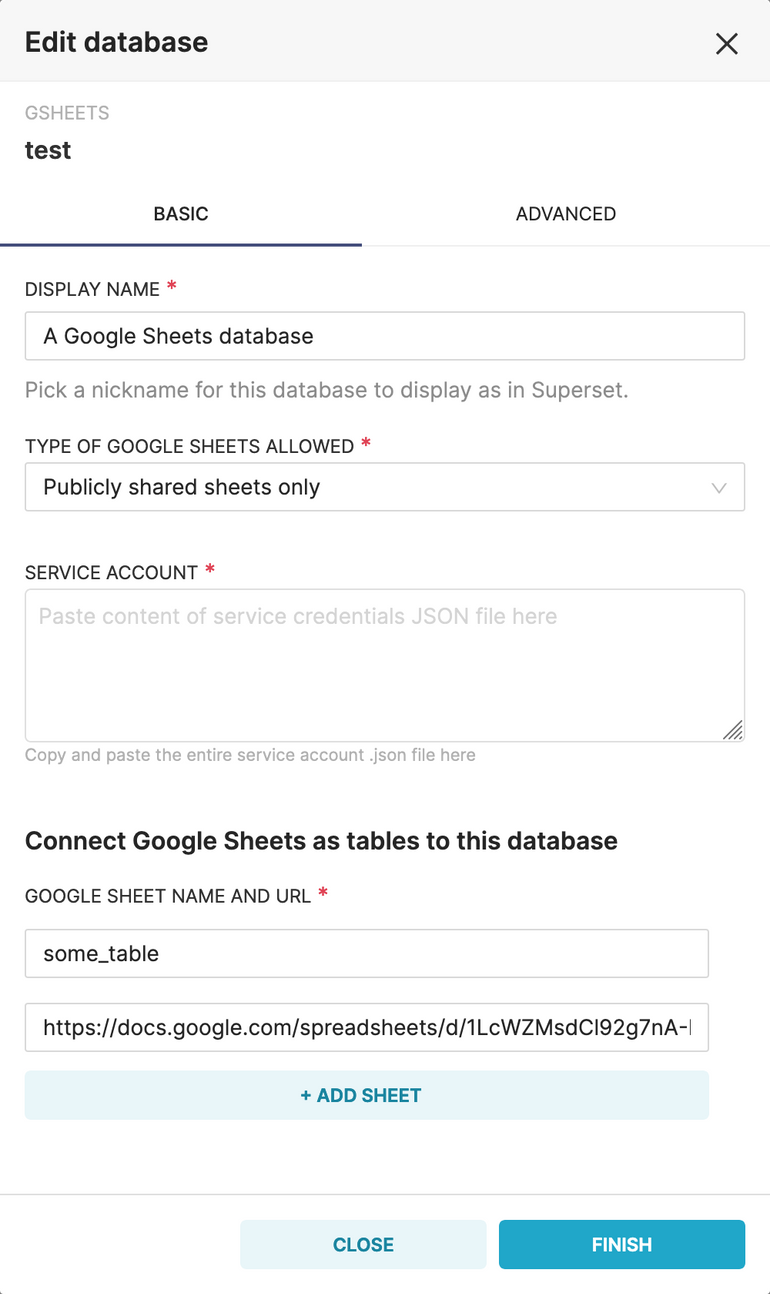
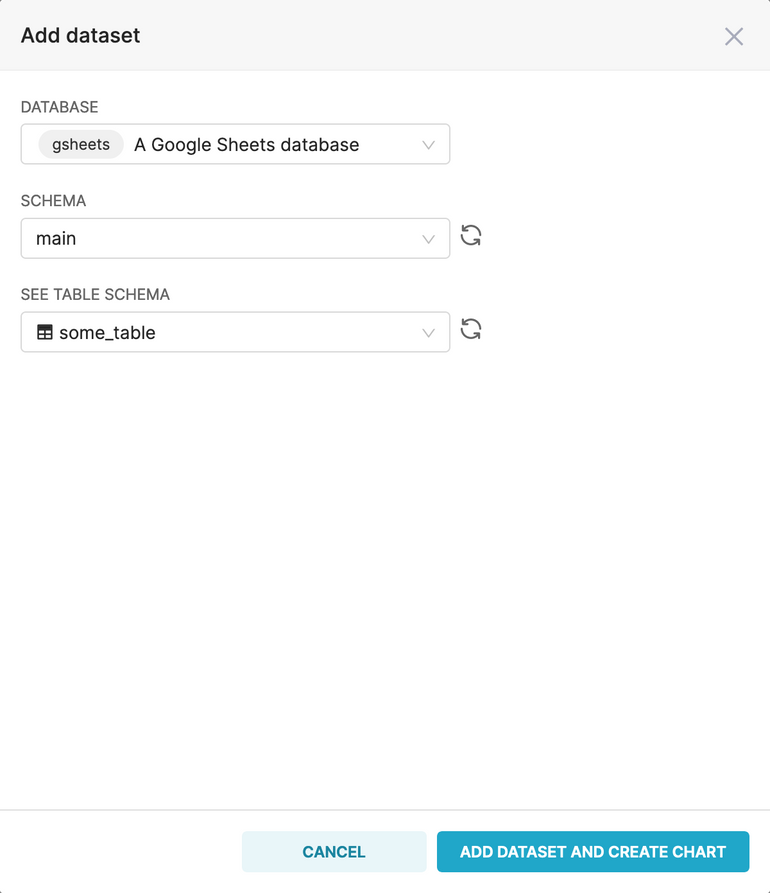
If you’re interested you can read more about connecting Superset to Google Sheets in the blog post Visualize Data in Preset Cloud Without a Database Using Google Sheets.
While Shillelagh was built with the main goal of supporting Google Sheets, the library offers a developer-friendly interface to support other APIs as well. In fact, this blog post I want to show how to use Shillelagh to access almost any API!
Creating a Shillelagh database
Shillelagh connects to different APIs via interfaces called adapters. The Google Sheets database in Superset is a custom version of a Shillelagh database, with only one adapter enabled: the Google Sheets API adapter. To unleash the full power of Shillelagh and all its different adapters we need to add a Shillelagh database to Superset:
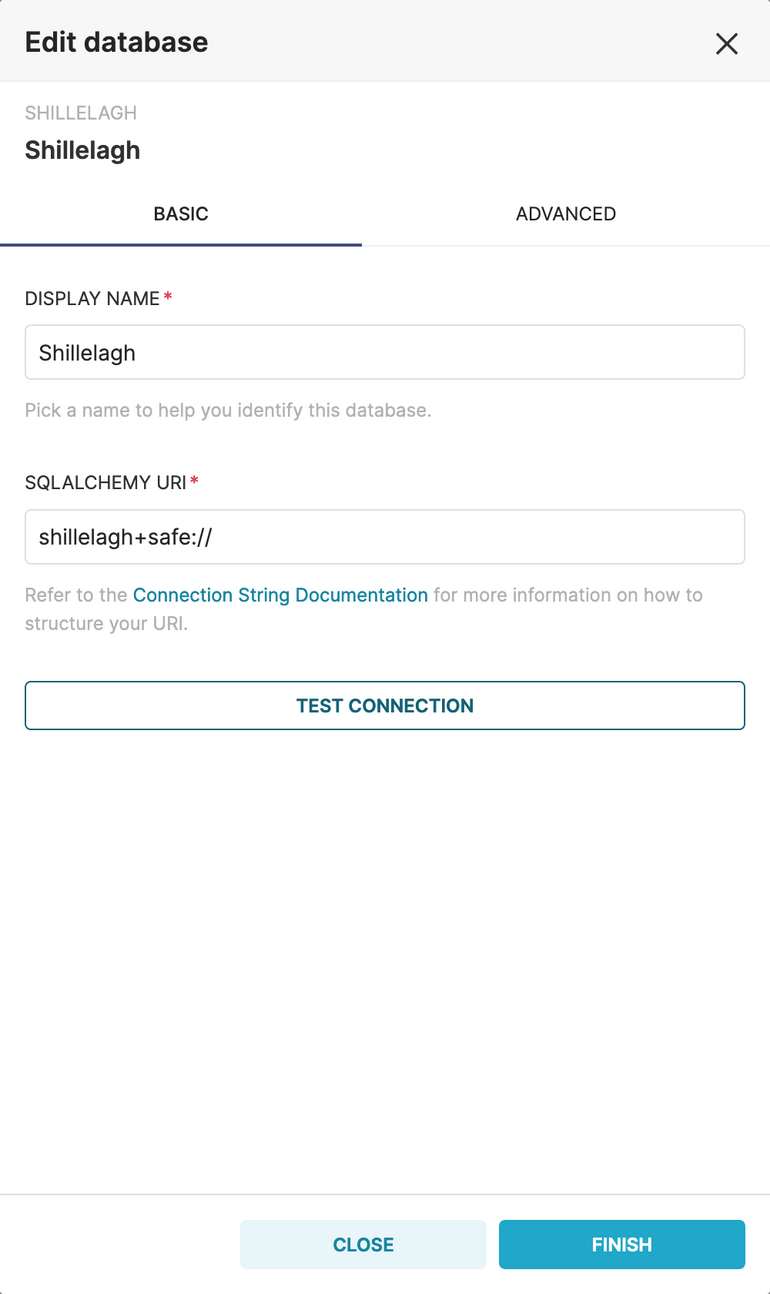
🍀 Why shillelagh+safe:// and not just shillelagh://? Some of the adapters that Shillelagh has can read files from the filesystem, and are potentially unsafe. Superset explicitly prevents the shillelagh:// database to be used for that reason, similarly to how it does for sqlite://. When using shillelagh+safe:// though, only adapters that are considered “safe” — adapters that only read remote data — can be loaded. In addition, the available adapters are not loaded automatically, and instead need to be listed explicitly, to prevent 3rd parties from injecting malicious adapters.
Before finishing the database connection we need to go into the “Advanced” section and add the following configuration to the “Engine Parameters” under the “Other” pane:
{
"connect_args": {
"adapters": [
"datasetteapi",
"genericjsonapi",
"githubapi",
"htmltableapi",
"s3selectapi",
"socrataapi",
"weatherapi"
]
}
}This is the list of all the adapters we want to enable in the database.
Alternatively, you can simply import this database into your workspace.
Accessing APIs
Now that we have a Shillelagh database set up in Superset, let’s head to SQL Lab and run some interesting queries.
Reading files from AWS S3
You can use Shillelagh to query CSV, JSON, and Parquet files stored in S3 buckets. This requires authentication even if you’re accessing public data, since it relies on Amazon S3 Select which does not support anonymous access.
In order to authenticate we need to add AWS credentials to the database connection. To do that, edit the Shillelagh database that we created and add the following fields to the engine parameters:
{
"connect_args": {
"adapters": [
"datasetteapi",
"genericjsonapi",
"githubapi",
"htmltableapi",
"s3selectapi",
"socrataapi",
"weatherapi"
],
**"adapter_kwargs": {
"s3selectapi": {
"aws_access_key_id": "XXX",
"aws_secret_access_key": "YYY"
}
}**
}
}With the credentials, we can now query many of the public datasets available at the Registry of Open Data on AWS. For example, NOAA offers historical precipitation (rain) data for more than a hundred thousand weather stations around the world in the noaa-ghcn-pds bucket, both in CSV and Parquet files.
We can browse available files using the AWS CLI. Since we have the data available both as CSV and Parquet let’s use the latter, since it’s better at encoding different types of columns:
$ aws s3 ls --no-sign-request s3://noaa-ghcn-pds/parquet/by_station/ | head
PRE STATION=ACW00011604/
PRE STATION=ACW00011647/
PRE STATION=AE000041196/
PRE STATION=AEM00041194/
PRE STATION=AEM00041217/
PRE STATION=AEM00041218/
PRE STATION=AF000040930/
PRE STATION=AFM00040938/
PRE STATION=AFM00040948/
PRE STATION=AFM00040990/Let’s look at the average precipitation in San Mateo, CA (station US1CASM0015), for the last 2021:
> SELECT AVG(DATA_VALUE)
. FROM "s3://noaa-ghcn-pds/parquet/by_station/STATION=US1CASM0015/ELEMENT=PRCP/84b6a4e08e774e05a9e499b0e6edc222_0.snappy.parquet"
. WHERE "DATE" LIKE '2021%';
AVG(DATA_VALUE)
-----------------
21.2247That’s 21mm, or little under one inch.
Have you ever had a work week where the days are beautiful and sunny, and when you make plans for the weekend it rains? We can check if it rains more on weekends than during work days with a simple query:
> SELECT
. AVG(DATA_VALUE) AS avg_precipitation,
. STRFTIME(
. '%w',
. DATE(
. SUBSTR("DATE", 1, 4)
. || '-' ||
. SUBSTR("DATE", 5, 2)
. || '-' ||
. SUBSTR("DATE", 7, 2)
. )
. ) AS dow
. FROM "s3://noaa-ghcn-pds/parquet/by_station/STATION=US1CASM0015/ELEMENT=PRCP/84b6a4e08e774e05a9e499b0e6edc222_0.snappy.parquet"
. GROUP BY 2;
avg_precipitation dow
------------------- -----
14.3808 0
19.9247 1
14.2845 2
14.0435 3
18.1663 4
16.9959 5
16.2296 6In addition to public data, you can use the adapter to access any private buckets that your AWS credentials have access to. For example, you could configure applications to log to an S3 buckets, and use Shillelagh to aggregate and visualize that data in Superset.
While accessing Parquet and CSV files is pretty straightforward, with JSON the SQL engine needs more information in order to process the files. Imagine you have a JSON file stored in S3 with the following contents:
{
"author": "zak@example.org",
"users": [
{"id": 1, "name": "Alice", "email": "alice@example.org"},
{"id": 2, "name": "Bob", "email": "bob@example.org"}
]
}To query the data above we need to inform Shillelagh that the rows we are interesting in are inside the users attribute. To that, we use a JSON Path expression as an anchor in the URL. In this case, we need to pass $[*].users[*]:
> SELECT *
. FROM "s3://bucket/file.json?Type=DOCUMENT#**$[*].users[*]**"
. WHERE name = 'Alice';
id name email
---- ------ -----------------
1 Alice alice@example.orgNote that we also pass Type=DOCUMENT to declare that the file holds a single document. Sometimes the JSON file is structured differently, with each line being a separate document:
{"id": 1, "name": "Alice", "email": "alice@example.org"}
{"id": 2, "name": "Bob", "email": "bob@example.org"}For files like this we need to specify the type as LINES:
> SELECT * FROM "s3://bucket/file.json?Type=LINES";GitHub
Shillelagh has an adapter that supports querying GitHub for Pull Requests:
> SELECT title, number
. FROM "https://api.github.com/repos/apache/superset/pulls"
. WHERE
. state = 'open' AND
. username = 'betodealmeida'
title number
--------------------------------------------------------- --------
feat: safer insert RLS 20323
[WIP] feat: use personal access token in OAuth2 databases 20280
feat: a native SQLAlchemy dialect for Superset 14225This can be useful to track status of PRs from your team in a dashboard. Note that if you’re querying a project with many PRs the requests might be throttled by GitHub. You can decrease the throttling rate by authenticating with an access token:
{
"connect_args": {
"adapters": [
"datasetteapi",
"genericjsonapi",
"githubapi",
"htmltableapi",
"s3selectapi",
"socrataapi",
"weatherapi"
],
**"adapter_kwargs": {
"githubapi": {
"access_token": "XXX"
}
}**
}
}Currently only the API for PRs is supported, but adding new endpoints is relatively simple and doesn’t require any logic other than declaring the schema of the response. Feel free to open a ticker or a PR in the Shillelagh repository!
Socrata
The Socrata Open Data API is a simple API with over one hundred different data catalogs for governments, non-profits, and NGOs around the world, including the CDC. You can search available datasets in the Open Data Network website, or browse by category (finance, environment, economy, etc.).
Socrata URLs usually look like [https://example.org/resource/abcd-ef01.json](https://example.org/resource/abcd-ef01.json), and can be queried directly:
-- weekly number of double vaccinated people in the US
> SELECT
. date, administered_dose1_recip_4
. FROM "https://data.cdc.gov/resource/unsk-b7fc.json"
. WHERE location = 'US'
. ORDER BY date DESC
. LIMIT 10;
date administered_dose1_recip_4
---------- ----------------------------
2022-12-07 91.6
2022-11-30 91.5
2022-11-23 91.7
2022-11-16 91.6
2022-11-09 91.4
2022-11-02 91.2
2022-10-26 91.1
2022-10-19 91
2022-10-12 90.8
2022-10-05 90.6Fetching weather data
Shillelagh has an adapter for weather data that reads from the aptly named Weather API. Access to the last 7 days of hourly data is free, but requires registration to get an access token, which should be added to the database configuration:
{
"connect_args": {
"adapters": [
"datasetteapi",
"genericjsonapi",
"githubapi",
"htmltableapi",
"s3selectapi",
"socrataapi",
"weatherapi"
],
**"adapter_kwargs": {
"weatherapi": {
"api_key": "XXX"
}
}**
}
}Once you have added the API key you can query for a city name or ZIP code. For example, to get the average daily temperature in Bodega Bay, CA (94923):
> SELECT
. DATETIME(time, 'start of day') AS day,
. temp_c,
. temp_f
. FROM "https://api.weatherapi.com/v1/history.json?q=94923"
. GROUP BY 1;
day AVG(temp_c) AVG(temp_f)
------------------- ------------- -------------
2022-12-02 00:00:00 5.275 41.4937
2022-12-03 00:00:00 4.64167 40.3542
2022-12-04 00:00:00 7.94583 46.2958
2022-12-05 00:00:00 9.62083 49.3125
2022-12-06 00:00:00 8.27917 46.9042
2022-12-07 00:00:00 8.625 47.5292
2022-12-08 00:00:00 7.45833 45.425
2022-12-09 00:00:00 9.225 48.6Accessing Datasette instances
Datasette is an open source multi-tool for exploring and publishing data, aimed at data journalists, museum curators, archivists, local governments, scientists, researchers, and “anyone else who has data that they wish to share with the world”.
The website has a list of examples of different data that can be accessed. Here’s a simple query finding 10 food trucks selling burritos in San Francisco, CA:
> SELECT Address
. FROM "https://san-francisco.datasettes.com/food-trucks/Mobile_Food_Facility_Permit"
. WHERE LOWER(FoodItems) LIKE '%burrito%'
. LIMIT 10;
Address
---------------------
1800 FOLSOM ST
345 WILLIAMS AVE
660 MARIPOSA ST
1800 EVANS AVE
1700 EVANS AVE
180 NEW MONTGOMERY ST
1700 EVANS AVE
1495 WALLACE AVE
359 POTRERO AVE
1800 FOLSOM STInteracting with generic JSON APIs
In all the examples above, Shillelagh knows how to interact with the APIs in order to filter as much data as possible on the service, instead of locally. Predicates like WHERE id = 42 are converted into parameters that are passed to the API endpoints, for example, ?id=42, making the calls relatively efficient (data still needs to be joined and aggregated locally). The downside is that an adapter needs to be explicitly built for each API for this to work.
Shillelagh also supports generic JSON APIs. For example, imagine an API at https://whales.example.org/ that returns data like this:
{
"results": [
{
"id": 1,
"common name": "bottlenose dolphin",
"scientific name": "Tursiops truncatus"
}
{
"id": 2,
"common name": "Southern right whale",
"scientific name": "Euballaena australis"
}
]
}We can query the endpoint with Shillelagh:
> SELECT "scientific name"
. FROM "https://whales.example.org/#$.results[*]"
. WHERE "common name" LIKE '%dolphin%';
scientific name
---------------------
Tursiops truncatusA few things to note:
- We need to indicate where the data lives in the JSON payload, using a JSON Path expression. In the hypothetical payload above the rows live inside the
resultskey, so the JSON Path to retrieve all the rows is$.results[*], which is added as an anchor to the URL. - The query above will fetch all the data from the endpoint, and filter it locally. If the API supports a way of filtering the data you might want to leverage it, for example:
> SELECT "scientific name"
. FROM "https://whales.example.org/**?common_name~=dolphin**#$.results[*];
scientific name
---------------------
Tursiops truncatusIt’s possible to combine both, filtering in the URL and using a SQL predicate, depending on the API. Note that we do something similar in the Weather API adapter, where the location needs to be specified as a URL parameter, since it’s not part of the payload schema and should always be present:
> SELECT * FROM "https://api.weatherapi.com/v1/history.json?q=**94923**"For a real life example we can use this to fetch the list of holidays in the US for next year. This could be useful to add annotations to a chart in Superset. Here’s how easy it is to fetch the data:
> SELECT date, name
. FROM "https://date.nager.at/api/v3/publicholidays/2023/US";
date name
---------- ---------------------------
2023-01-02 New Year's Day
2023-01-16 Martin Luther King, Jr. Day
2023-02-20 Washington's Birthday
2023-04-07 Good Friday
2023-04-07 Good Friday
2023-05-29 Memorial Day
2023-06-19 Juneteenth
2023-07-04 Independence Day
2023-09-04 Labour Day
2023-10-09 Columbus Day
2023-11-10 Veterans Day
2023-11-23 Thanksgiving Day
2023-12-25 Christmas DayScraping HTML tables
Similarly to generic JSON endpoints, Shillelagh also has an adapter that can fetch data from HTML tables by simply querying the page URL. By default the first table found will be returned, but other tables can be specified with an anchor. For example, to see the top countries that have won the World Cup:
> SELECT * FROM "https://en.wikipedia.org/wiki/List_of_FIFA_World_Cup_finals**#4**"
. WHERE Winners > 0;
Team Winners Runner-ups Total finals Years won Years runners-up
-------------- --------- ------------ -------------- ---------------------------- ----------------------
Brazil 5 2 7 1958, 1962, 1970, 1994, 2002 1950, 1998
Germany 4 4 8 1954, 1974, 1990, 2014 1966, 1982, 1986, 2002
Italy 4 2 6 1934, 1938, 1982, 2006 1970, 1994
Argentina 2 3 5 1978, 1986 1930, 1990, 2014
France 2 1 3 1998, 2018 2006
Uruguay 2 0 2 1930, 1950 –
England 1 0 1 1966 –
Spain 1 0 1 2010 –In the example above we are interested in the 5th table in the page, so we append the #4 anchor to the URL.
Final notes
Shillelagh was written as a way to bridge the SQL world of Apache Superset with all the countless APIs that are available these days, making it easy to bring the data into charts and dashboards. Hopefully this article has given some ideas of how to use to enrich your existing visualizations with interesting data.
Want to take your integrations further? Check out the Preset API for programmatic access to dashboards, datasets, and more.
