


Real Time Databases vs Time Series Databases




Data technology is one of the fastest changing parts of the broader technology landscape. As information science practitioners in the field, it can be easy to get overwhelmed keeping up with the constant stream of new technologies, databases, ETL tools, SaaS middleware, analytics tools, conceptual paradigms, and so much more. In particular, I have noticed confusion recently between:
- real-time databases
- time series databases
- and real-time analytics
In this post, I will attempt to straighten out the nuances of each of these terms, what they really mean, what technologies are operating in these spaces, and mention both open source and closed source examples.
Real-time databases
'Real-time' just means faster right?
Sort of. The term 'real-time' in this context describes the performance guarantee of a database system. It means that a given database is able to write and/or read data inside a strict performance envelope, usually defined on the order of seconds to milliseconds.
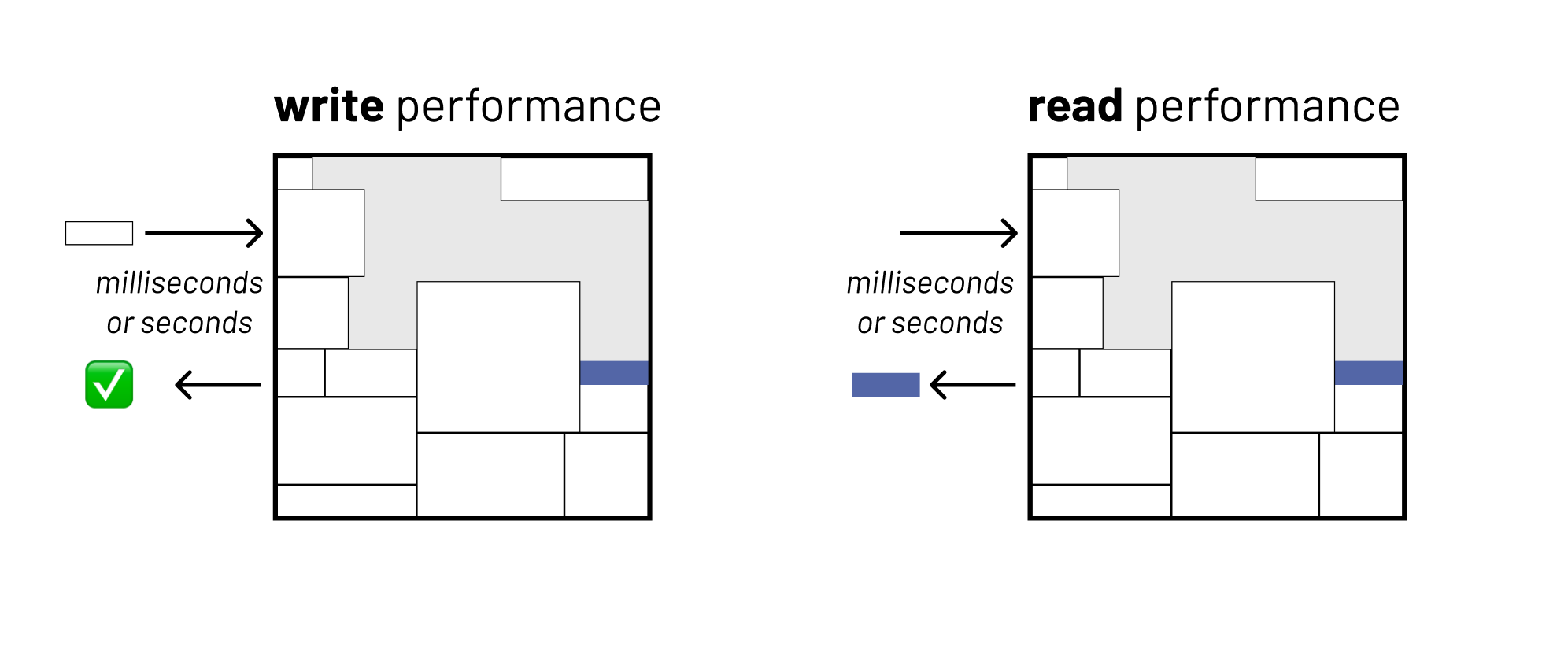
Why wouldn't we want our data systems to be faster? Won't everything be real-time eventually?
What enables this technology under the hood is often the combination of a cluster architecture, super fast in-memory cache, and slower distributed databases.
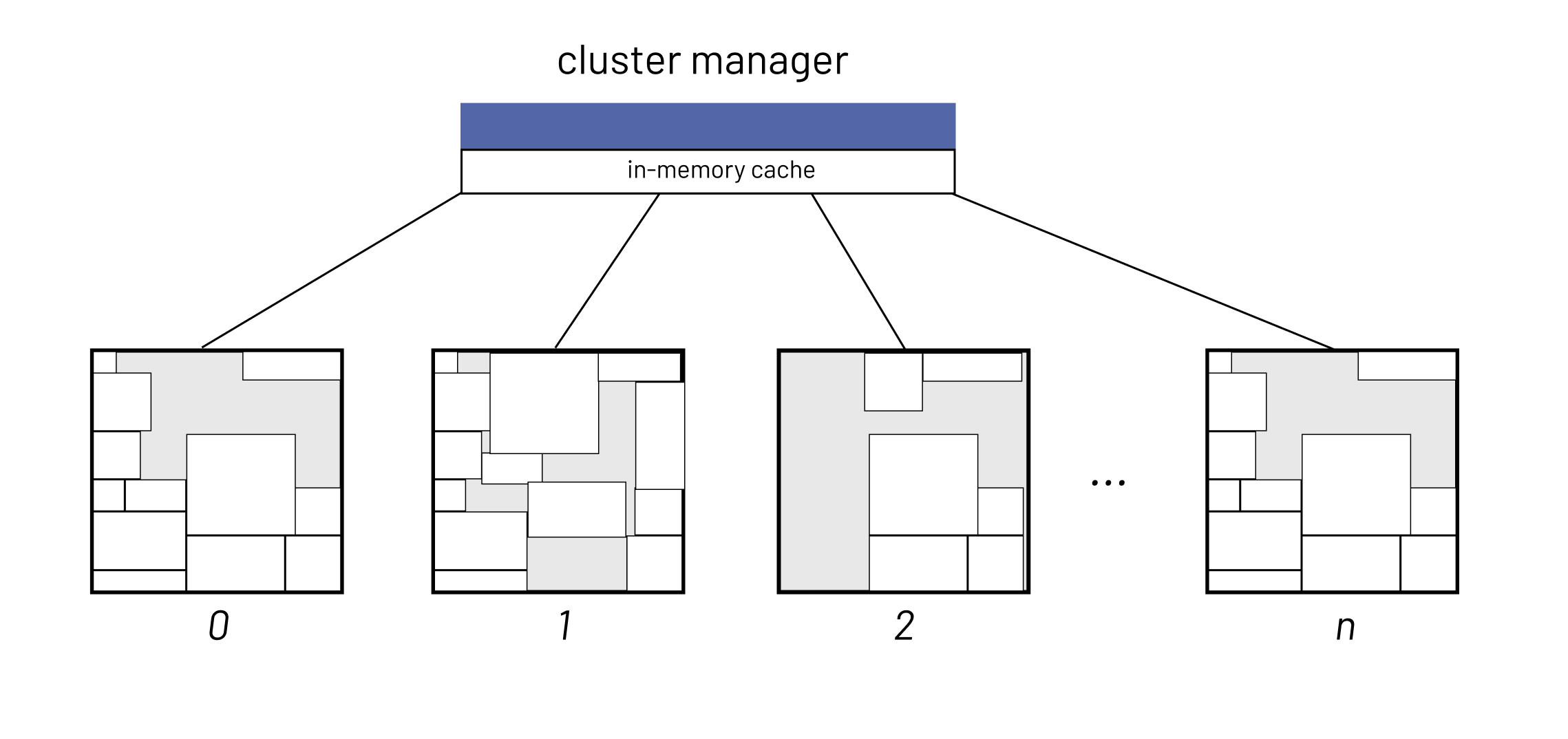
Oftentimes, these databases are relational but they don't have to be.
In recent years, a number of managed real-time databases have emerged which brings down the barrier to entry. Though a self-managed solution will require a significant amount of engineering resources to support, the cost of these technical pillars is built in with a managed database.
When does it make sense to use a real-time database system?
Real-time databases should only be used when read/write performance must be within a defined time-period for a clear business need that's in the order of a few seconds to milliseconds. Classic real-world use cases include fraud and anomaly detection in financial services, interactive real-time applications (like gaming), and network security.
Here's a list of some popular real-time databases:
Time series database
What is time series data?
Time series databases are optimized for storing the data model of time series data. A time series can be thought of as a sequence of values with a particular order, usually measurements of interest taken over time. Time series data is everywhere, from weather data, to price fluctuations in the stock market, to senseor data, and to clickstream data from websites and apps. Time series databases are optimized for storing and retrieving time series data at scale. These databases are also optimized for time series analysis, which focuses on machine learning and other statistical techniques for processing this type of data.
What makes time series databases suited for time series data?
Often this means a column-oriented storage implementation and time-based partitioning of the data, but these aren't always true. For example, TimescaleDB has a mix of both to reflect the reality that end-users often use a mix of query types.
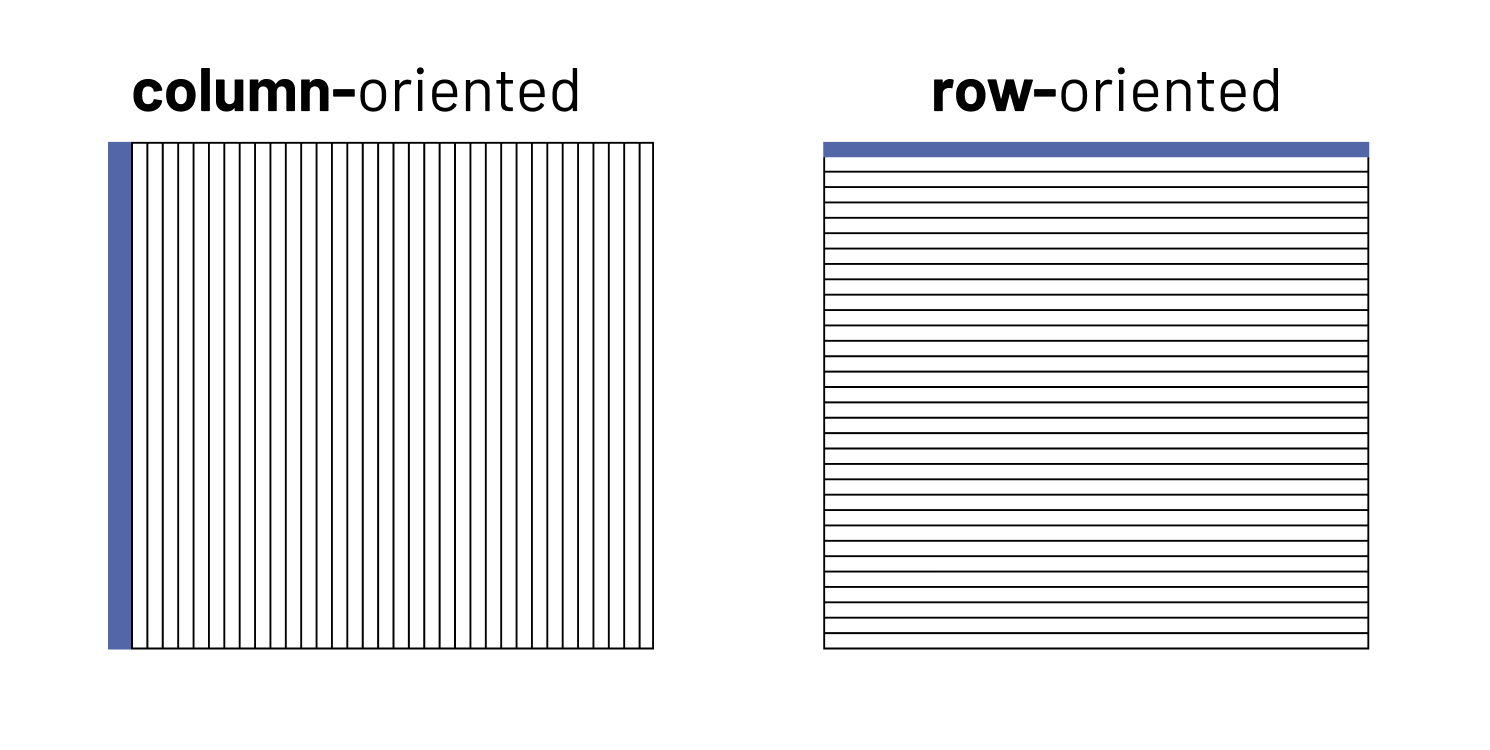
Since historical time series datasets are often huge, time series databases sometimes make use of cluster architectures able to handle large data volume and velocity. Time series databases often pack other interesting optimizations in how data is organized that can speed retrieval of chunks of time series data and increase the rate at which it can be written.
All this comes with a performance drawback for other, non-time series data types. Though plenty of time series databases can competently store other data types as well, what SQL JOINs can be performed are usually limited.
Are real-time time series databases a thing?
Absolutely! There are a number of database technologies that are designed for both a real-time performance envelope and time series data. Apache Druid is a well-known and widely used example that supports both data models.
Here's a list of time series databases, some of which also can provide real-time performance, depending on the needed performance envelope:
Real-time analytics
So what is real-time analytics anyway?
All this brings us to real-time analytics, where things get significantly fuzzier. There's a dizzying array of definitions out there so I will attempt to pick what I think is the best one.
Conceptually, real-time analytics is a capability enabled by an entire data stack that satisfies the real-time performance requirements from ingestion up to the BI (or analytics) layer. Real-time analytics is the outcome of a set of technical decisions in the data stack, rather than a specific technology by itself.
What are the barriers to deploying this sort of data system?
Data entering a real-time analytics stack needs to be ingested (usually with a streaming framework like Kafka), stored, retrieved , analyzed, and visualized by a real-time analytics platform all within a tight performance envelope. This describes a full, complex system that vastly outstrips the complexity of just a real-time or time series database.
When will this data-stack be ready for my organization's needs?
While real-time analytics sounds like a really good thing that any organization could reasonably want, for the reasons discussed above (cost, complexity, maintenance, lack of a compelling business need), I would argue this is often not the case. In fact, there are not so many real-world situations where a real-time analytics stack would be worth the cost or complexity to deploy and maintain.
For real-time databases, data freshness is super important. Historical data is often deprioritized when it comes to real-time workloads.
Use-cases around fraud detection, ultra-high frequency trading systems, and cases where the end-to-end nature of the business is real-time (Uber Eats, Lyft, Doordash, etc) all come to mind as justifications for deploying a real-time analytics stack.
Conclusion
Notice that we didn't talk much about machine learning or big data in this post. That's because both of these exist independently of the data systems themselves, and you can run big data and machine learning workloads in all of these types of systems.
To wrap things up, here's a simple summary of the differences we discussed above:
- Real-time database: a data store with strict performance guarantees (milliseconds to seconds) for reads and / or writes
- Time series database: a data store optimized for storing and querying time series datasets
- Real-time analytics: a technical and organizational outcome of reducing latency across the entire data stack, ideally to meet a specific operational need.
Why are we interested in the differences at Preset? Because we are supporting and commercializing Apache Superset, a modern open-source BI platform. Our aspiration is for Superset to be able to query any real-time data store, query any time series data store, and support an organization's needs around real-time analytics.
Related Reading
- Visualizing ClickHouse Data — Connect Superset to ClickHouse, a popular real-time analytics database
- Time Series Forecasting in Apache Superset — Predictive analytics with Apache Druid
- Real-Time Analytics in Apache Superset — Building real-time dashboards
- Querying Federated Data with Trino — Query across multiple database types
