


Querying Federated Data Using Trino and Apache Superset




I recently had the privilege of working with Srini and a bunch of folks from the Superset community and it’s been wonderful to see a lot of the problems that get solved in a visualization platform. It’s refreshing to think through the data analytics problems from the lens of visuals that appeal to our most basic evolutionary sense of sight that relay concepts faster than a ten page paper could.
You see, I come from the Trino project and our level of focus is typically aimed at speeding up ad-hoc queries, particularly joins, across heterogeneous data sources. This may be the first time you have heard of Trino, but you've likely heard of the project from which it was forked, Presto. If you're new to Superset, check out our Apache Superset overview to learn why it's become the leading open-source BI platform.
If you want to learn more about why the creators of Presto now work on Trino (formerly PrestoSQL) you can read the renaming blog that they produced earlier this year. Before you commit too much to this blog, I’d like to let you know why you should even care about Trino as a Superset user.
Introduction to Trino
The first thing I like to make sure people know about when discussing Trino is that it is a SQL query engine, but not a SQL database. What does that mean? Here's one view of the internals of a traditional database system:
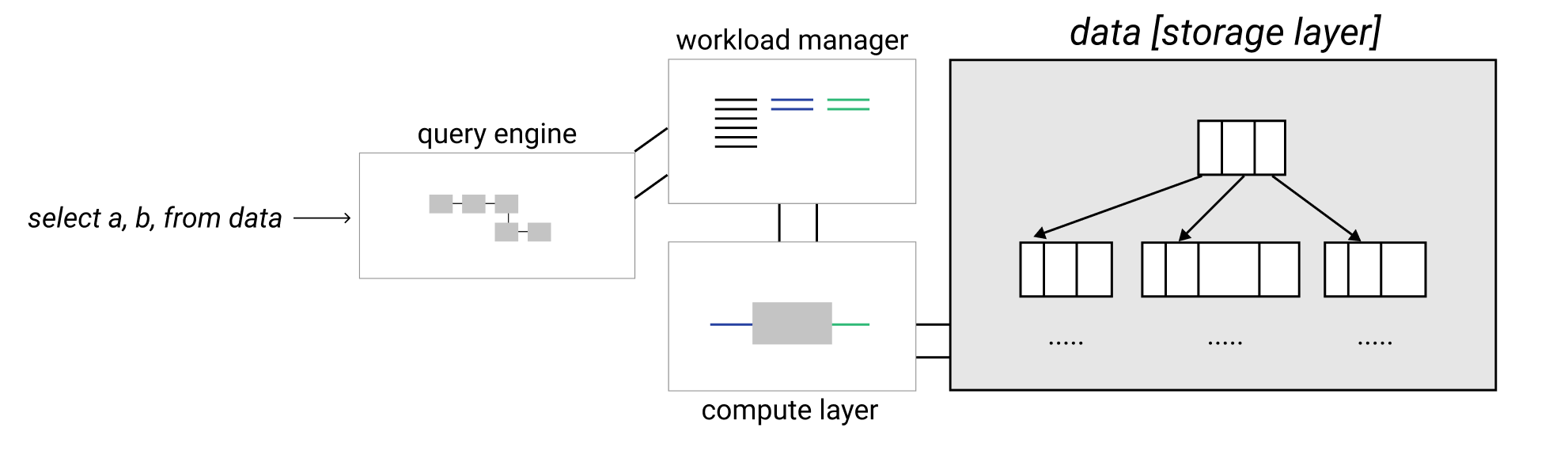
Traditional databases typically consist of a query engine and a storage engine. Trino is just a query engine and does not store data. Instead Trino interacts with various databases that store their own data in their own formats.
Trino parses and analyzes the SQL query you pass in, creates and optimizes a query execution plan that includes the data sources, and then schedules worker nodes that are able to intelligently query the underlying databases they connect to.
I say intelligently, specifically talking about pushdown queries. That’s right, the most intelligent thing for Trino to do is to avoid making more work for itself, and try to offload that work to the underlying database. This makes sense as the underlying databases generally have special indexes and data that are stored in a specific format to optimize the read time. It would be silly of Trino to ignore all of that optimized reading capability and do a linear scan of all the data to run the query itself.
The goal in most optimizations for Trino is to push down the query to the database and only get back the smallest amount of data needed to join with another dataset from another database, do some further Trino specific processing, or simply return as the correct result set for the query.
Why Trino?
So I still have not really answered your question of why you should care about Trino. The short answer is, Trino acts as a single access point to query all data sources. That’s it. Oh and it’s super fast at ad-hoc queries over various data sources. It has a connector architecture that allows it to speak the language of a whole bunch of databases.
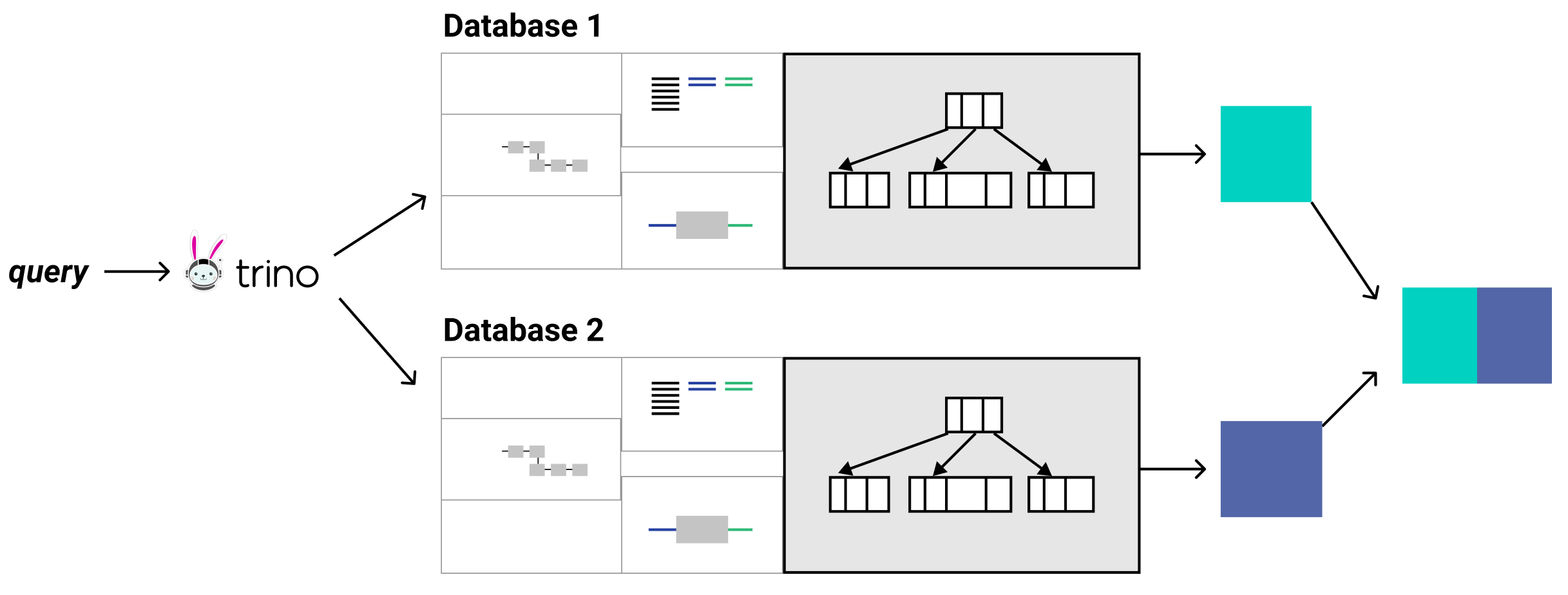
If you have a special use case, you can write your own connector that abstracts any database or service away to just be another table in Trino’s domain. Pretty cool right? But that’s actually rarely needed because the most common databases already have a connector written for them. If not, more connectors are getting added by Trino’s open source community every few months.
Querying MongoDB in Apache Superset
One immediate benefit that Trino brings to Superset users is the ability to query MongoDB. MongoDB is one of those databases that has been highly sought after but still hasn’t been supported for Superset users that want to query that database to visualize on Superset. With Trino it’s incredibly simple to set up a MongoDB catalog and start running SQL queries on it.
- Trino opens up a path for you to visualize your MongoDB data in a system like Superset that didn’t exist before.
- Trino is able to map standardized ANSI SQL that it uses to the Mongo specific query language. To extrapolate this point, that means that if you have five different data stores, each with their own independent query language, your data science or analyst team just need to know SQL to access them through Trino.
- You are able to join data across tables of different databases like an application database like MongoDB with an operational database like MySQL. Further, using Trino even enables joining data sources with themselves where joins are not supported, like in MongoDB. Did it happen yet? Is your mind blown?
Getting Started with Trino
So what is required to give Trino a test drive? The easiest way to try out Trino is to use Docker. First I'll go over some requirements of Trino for a general installation, but you really don’t need to worry about this too much if you are just testing out Trino. I will provide a link to a preconfigured Docker Compose setup with instructions on how to use it. These instructions are a basic overview of the more complete installation instructions if you’re really going for it! If you’re not that interested in the installation, feel free to skip ahead to the Using Trino With Docker section.
Trino Requirements
The first requirement is that Trino must be run on a Linux machine. There are some folks in the community that have gotten Trino to run on Windows for testing using runtime environments like cygwin but this is not supported officially. However, in our world of containerization, this is less of an issue and you will be able to at least test this on Docker no matter which operating system you use.
Trino is written in Java and so it requires the Java Runtime Environment (JRE). Trino requires a 64-bit version of Java 11, with a minimum required version of 11.0.7. Newer patch versions such as 11.0.8 or 11.0.9 are recommended. The launch scripts for Trino bin/launcher, also require python version 2.6.x, 2.7.x, or 3.x.
Trino Configuration
To configure Trino, you need to first know the Trino configuration directory. If you were installing Trino by hand, the default would be in a etc/ directory relative to the installation directory. For our example, I'm going to use the default installation directory of the Trino Docker image, which is set in the run-trino script as /etc/trino. We need to create four files underneath this base directory. I will describe what these files do and you can see an example in the Docker image I have created below.
config.properties: This is the primary configuration for each node in the trino cluster. There are plenty of options that can be set here, but you’ll typically want to use the default settings when testing. The required configurations include indicating if the node is the coordinator, setting the port that Trino communicates on, and the discovery node url so that Trino servers can find each other.jvm.config: This configuration contains the command line arguments you will pass down to the java process that runs Trino.log.properties: This configuration is helpful to indicate the log levels of various java classes in Trino. It can be left empty to use the default log level for all classesnode.properties: This configuration is used to uniquely identify nodes in the cluster and specify locations of directories in the node.
The next directory you need to know about is the catalog/ directory, located in the root configuration directory. In the Docker container, it will be in /etc/trino/catalog. This is the directory that will contain the catalog configurations that Trino will use to connect to the different data sources. For our example, we’ll configure two catalogs, the mongo catalog, and the tpch catalog. The tpch catalog is a simple data generation catalog that simply needs the conector.name property to be configured and is located in /etc/trino/catalog/tpch.properties.
connector.name=tpchThe mongo catalog just needs the connector.name to specify which connector plugin to use, and the mongodb.seeds property to point to a comma separated list of mongo servers. Edit mongo.properties:
connector.name=mongodb
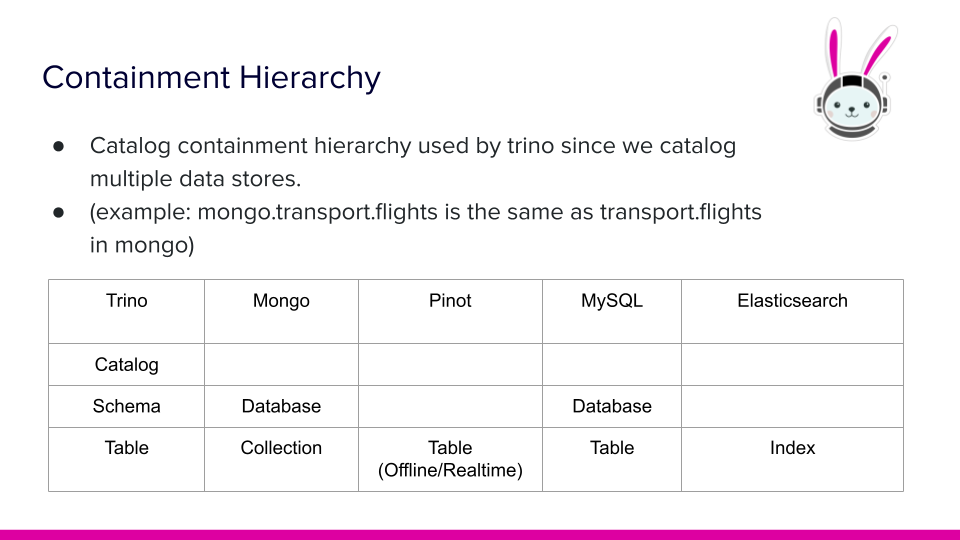
mongodb.seeds=mongodb:27017Note: the name of the configuration file becomes the name of the catalog in Trino. For example, if we name this file /etc/trino/catalog/mongo.properties, then the table (or collection in MongoDB) in the transport database and the flights collection would be addressed as mongo.transport.flights.
In Trino, catalogs point to data sources like MongoDB. Schemas point to the next level of containment (in MongoDB this is equivalent to a database). The last level is generally called a table but Mongo calls this a collection (since they’re dealing with documents).
Using Trino with Docker
Trino ships with a Docker image that does a lot of the setup necessary for Trino to run. Outside of simply running a Docker container, there are a few things that need to happen for setup. First, in order to use a database like MongoDB, we actually need to run a MongoDB container as well using the official Mongo image.
The main settings we need to mind are that the hostname of mongodb matches the instance name, and the mongodb instance is on the trino-network that the trino-coordinator instance will also join. Also be sure to expose the 27017 port on the network. Last configuration to point out is that mongo will point to a relative directory on the local filesystem to store data. This can be cleared out when completed.
Finally, we will use the trinodb/trino image for the trino-coordinator instance, and use the volumes option to map our local custom configurations for Trino to the /etc/trino directory we discussed before in this post. Trino should also be added to the trino-network and expose ports 8080 which is how external clients like Superset can access Trino. Below is an example of the docker-compose.yml file. The full configurations can be found in this getting started with Trino repository. Note: The repository is in a preliminary phase and can be force merged at any time.
version: '3.7'
services:
trino-coordinator:
image: 'trinodb/trino:latest'
hostname: trino-coordinator
ports:
- '8080:8080'
volumes:
- ./etc:/etc/trino
networks:
- trino-network
mongodb:
image: 'mongo:latest'
hostname: mongodb
ports:
- '27017:27017'
volumes:
- ./mongodb/database:/data/db
networks:
- trino-network
networks:
trino-network:
driver: bridgeNow to the big reveal. Before jumping right in, you will need to run the mongodb and trino-coordinator instances. To do this, navigate to the root directory that contains the docker-compose.yml and the etc/ directory and run:
docker-compsoe up -dRunning Your First Query
Your first query will actually be to generate data from the tpch catalog.
CREATE TABLE mongo.local.customer
AS SELECT * FROM tpch.tiny.customer;Then, let's query the data that was loaded into mongo catalog.
SELECT custkey, name, nationkey, phone
FROM mongo.local.customer LIMIT 5;The output should look like this.
|custkey|name |nationkey|phone |
|-------|------------------|---------|---------------|
|751 |Customer#000000751|0 |10-658-550-2257|
|752 |Customer#000000752|8 |18-924-993-6038|
|753 |Customer#000000753|17 |27-817-126-3646|
|754 |Customer#000000754|0 |10-646-595-5871|
|755 |Customer#000000755|16 |26-395-247-2207|If you've reached this far, congratulations, you now know how to set up catalogs and query them through Trino! The benefits at this point should be clear. For those who want to skip the infrastructure setup, Preset Cloud offers Trino connectivity with enterprise security and zero maintenance. But most people don't like looking at CLI output to visualize data.
In the upcoming part 2 post, Srini is going to cover how you can query your Trino cluster using Superset to visualize data!
Related Reading
- Real-Time vs Time-Series Databases — Understanding different database types for analytics
- Visualizing ClickHouse Data — Connect Superset to ClickHouse
- Connecting Superset to BigQuery — Cloud data warehouse tutorial
- Visualizing Data Lake with Athena — Query your S3 data lake with Superset
