


Announcing Preset Cloud's Integration with dbt's Semantic Layer







Preset is excited to announce our integration with dbt's Semantic Layer as a Metrics Ready integration to allow discovery and collaboration on dbt metric definitions within Preset!
How to use dbt metrics in Preset
dbt Labs recently launched first-class support for metrics in the dbt semantic layer. This allows using dbt not only as a source of truth for models but also for metrics. Metrics can be defined once, under source control and with proper code review, and be reused consistently across different tools. In this blog post, we’ll show how to consume these metrics in Apache Superset with Preset.
What’s in a metric?
Metrics in dbt are defined in any YAML file under the metrics: key, and are associated with a specific model. Here’s the example from their official documentation:
# models/marts/product/schema.yml
version: 2
models:
- name: dim_customers
...
metrics:
- name: rolling_new_customers
label: New Customers
model: ref('dim_customers')
description: "The 14 day rolling count of paying customers using the product"
calculation_method: count_distinct
expression: user_id
timestamp: signup_date
time_grains: [day, week, month, quarter, year]
dimensions:
- plan
- country
window:
count: 14
period: day
filters:
- field: is_paying
operator: 'is'
value: 'true'
- field: lifetime_value
operator: '>='
value: '100'
- field: company_name
operator: '!='
value: "'Acme, Inc'"
- field: signup_date
operator: '>='
value: "'2020-01-01'"
# general properties
config:
enabled: true | false
treat_null_values_as_zero: true | false
meta: {team: Finance}Translate to SQL, the metric would look somewhat like this:
SELECT COUNT(DISTINCT user_id)
FROM dim_customers
WHERE
is_paying IS TRUE
AND lifetime_value >= 100
AND company_name != 'Acme, Inc'
AND signup_date >= '2020-01-01'The most important thing to know about metrics is that they are not pre-aggregated, even though they will show up in the dbt DAG. Instead, it’s up to 3rd party tools (like Superset) to compute them on-the-fly as needed.
Being computed on-the-fly is great for exploration and prevents the proliferation of metrics and duplication of code. Instead of having rolling_new_customers_per_country, rolling_new_customers_in_argentina, etc., each one a slight variation of the other, the metric is defined only once. The user can then slice and dice the metric, computing it at different aggregation levels and with ad-hoc filters, as needed to answer their questions.
The metric definition provides the dimensions that are relevant to the metric (plan and country in the example above), as well as relevant time grains and the corresponding time column (signup_date).
Representing dbt metrics in Superset
Superset has a semantic layer model that is very similar to the dbt model: a dbt model can be seen as a Superset dataset, and both can contain metrics. In both tools metric are associated with a single model/dataset, are computed on the fly, and can be grouped/filtered in ad-hoc way across different associated dimensions.
There is one major difference, though: Superset metrics are defined by a single aggregation expression, while dbt metrics also have a list of associated filters. The metric rolling_new_customers above has 4 different predicates that need to be applied to the model in order to compute the aggregation.
Fortunately, there’s a well known solution for this problem, using a case expression. We can represent the rolling_new_customers metric as single aggregation expressions this way:
SELECT COUNT(DISTINT
CASE
WHEN
is_paying is true
AND lifetime_value >= 100
AND company_name != 'Acme, Inc'
AND signup_date >= '2020-01-01'
THEN user_id
END
)The expression above leverages the fact that CASE / END returns a NULL when there are no matches, and SQL expressions like COUNT ignore null values.
Even though the two queries will return identical values, there are performance differences between them. The Superset query has to scan the whole table, while the dbt query can benefit from indexes if they’re available, skipping rows. On the other hand, Superset can compute multiple metrics from the same model/dataset with a single query, while the dbt query with predicate requires one query for each metric, even if they are in the same parent model. As usual, it depends from case to case.
Here’s an example of the customers dataset from the Jaffle Shop example, with a metric new_customers defined in dbt as:
metrics:
- name: new_customers
label: New Customers
model: ref('customers')
description: "The number of paid customers using the product"
type: count
sql: customer_id
timestamp: first_order_date
time_grains: [day, week, month]
dimensions:
- first_name
filters:
- field: number_of_orders
operator: '>'
value: '0'In Superset:
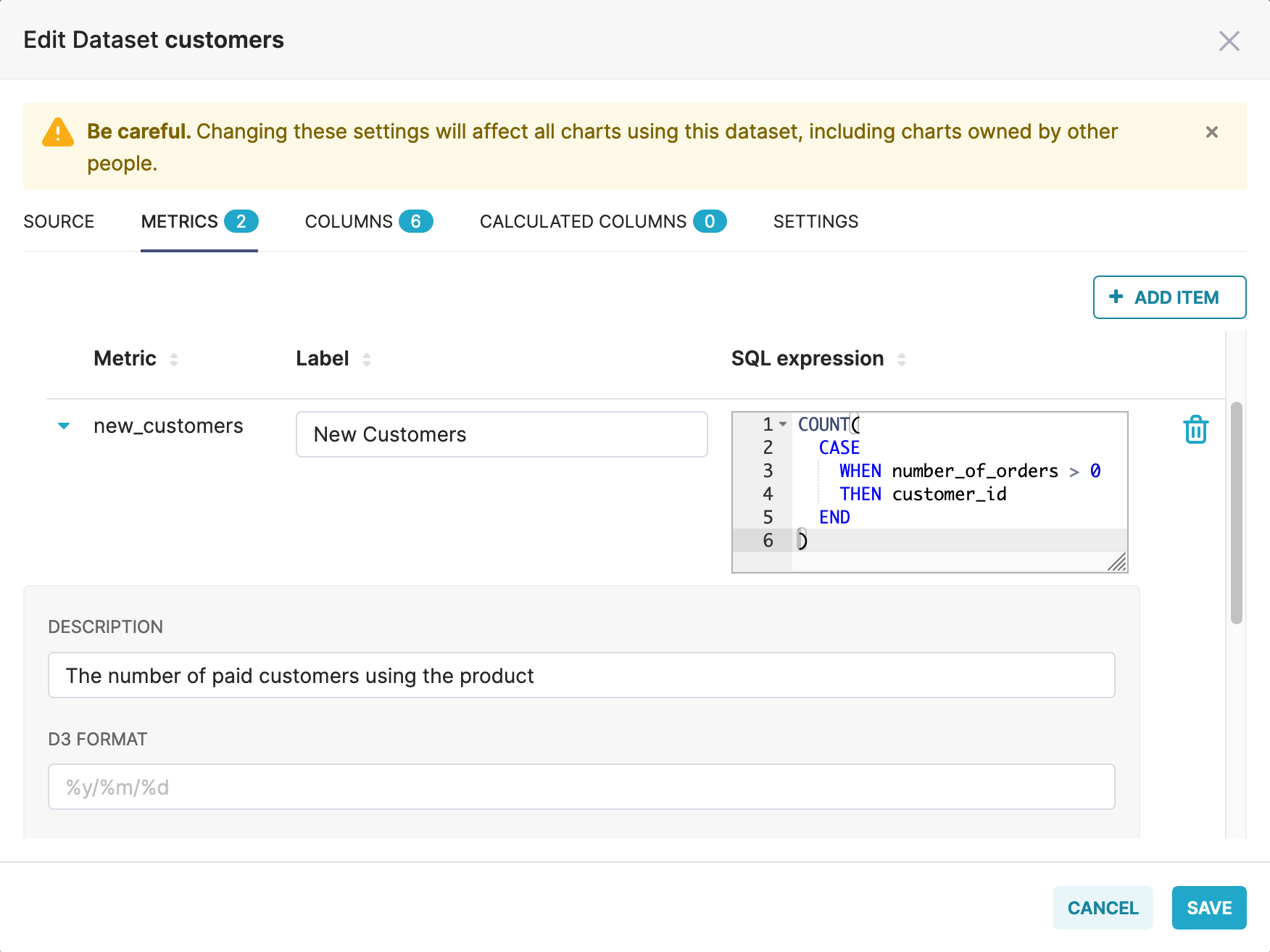
Using dbt metrics in Preset
Now that we understand how metrics are represented in dbt and how they are translated into Superset, how do we use them? The easiest way to do this is using the Preset CLI to keep them in sync. Our blog post Announcing Preset Cloud's Integration with dbt describes how to setup up a continuous deployment model where changes to the dbt model are automatically synchronized to a Preset workspace.
For a one-time synchronization all you need to do is run:
$ preset-cli auth # only needed once
$ preset-cli superset sync dbt-core /path/to/dbt_project.ymlThe command above will prompt you for the Preset workspace where the models and metrics should be synchronized, assuming you have more than one.
Alternatively, if you’re using dbt Cloud you can run:
$ preset-cli auth # only needed once
$ preset-cli superset sync dbt-cloud $ACCESS_TOKEN $JOB_IDWhere $ACCESS_TOKEN is a service token with “Metadata Only” permissions, and $JOB_ID is the ID of the job to be synchronized, which can be found in the URL of the job in dbt Cloud. Note that for dbt Cloud the database must be created first in the Preset workspace, with the exact same name as the dbt database (you can run the command first to see the expected name).
Both commands can be used to synchronize only a subset of the models, using a syntax that should be familiar to dbt users:
$ preset-cli superset sync dbt-core \
> --select +dim_customers+ \
> --exclude tag:testThe command above will synchronize the dim_customers model with its ancestors and descendants, excluding anything tagged as test.
Once the models and metrics are imported into the Preset workspace as datasets and metrics, exploration is easy — this is where Apache Superset shines. Just drag and drop the metric in the chart builder and choose dimensions to group by and filter:
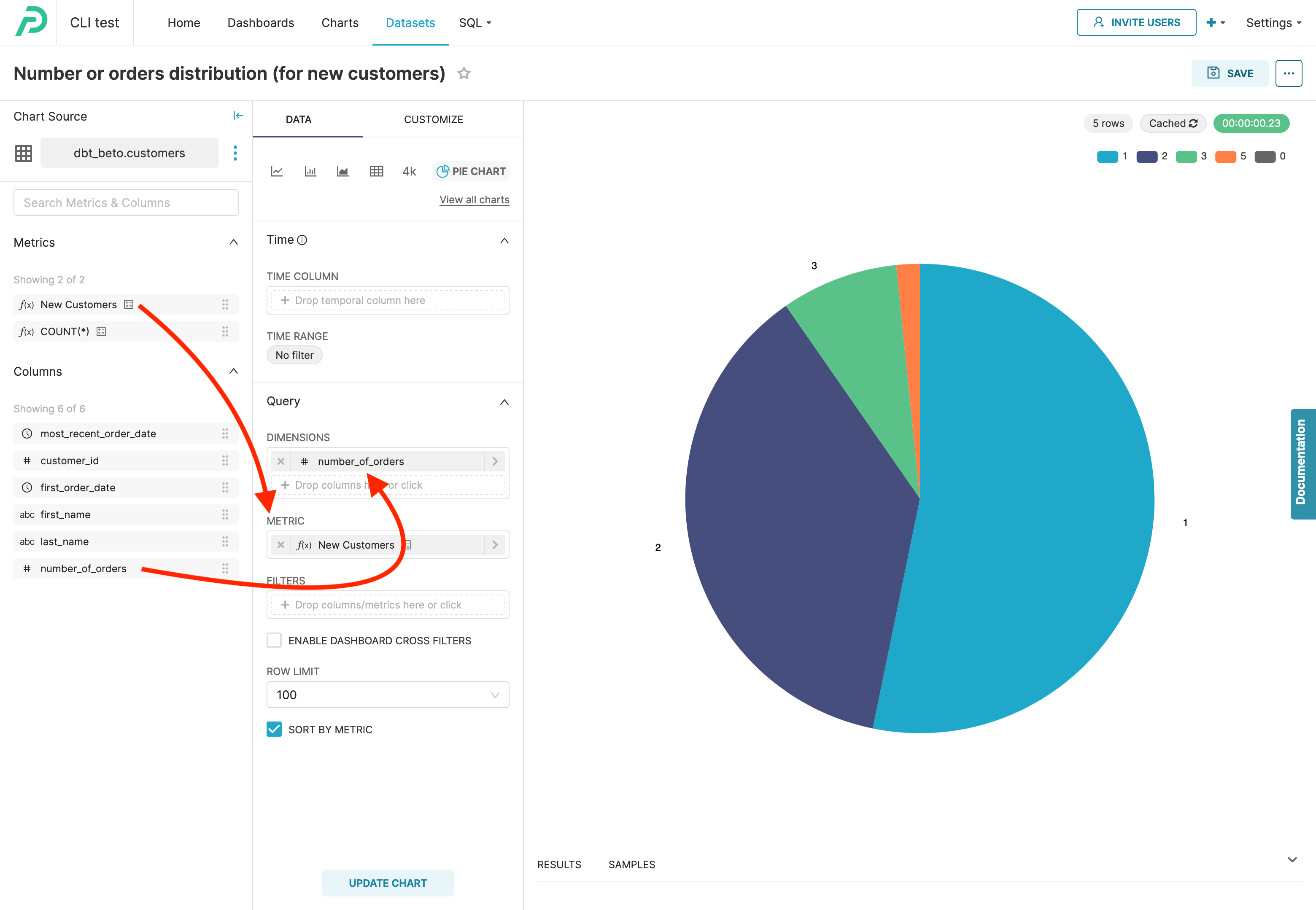
Coming next
Currently, the recommended way to keep the dbt models and metrics in sync with Superset is via a pipeline like GitHub Actions, where changes to the dbt project are pushed to Preset every time there is a change. While this can be a fire-and-forget action, it can be complex to setup.
To simplify the process, we’re improving Preset so that the integration with dbt Cloud can be configured from the browser. Users will be able to configure the dbt integration from within workspaces, during the database configuration phase, and Preset will take care or keeping models and metrics in sync between dbt and the workspace.
We are also working on a native integration with dbt cloud's Semantic Layer; this will allow for a metric-first approach to exploring data that we’re excited about!
