


Superset Announces Elasticsearch Support!







At Preset, we love open source.
The Superset open-source community is active with daily contributions flowing in from passionate contributors around the world. New features, fixes, code improvements or just quick asks for help - this is open source at it's best. Together, we generate a positive feedback loop that pushes innovation, quality and an inclusive community.
Before we begin, thanks to everyone from the Superset community who requested support for Elasticsearch. Your feedback made it clear that this is an important integration, and we’re excited to share what we’ve built.
Elasticsearch support for SQL Queries
You may already have heard, but Elastic recently released support for SQL queries. SQL being as widespread as it is, this enables all sorts of new integrations.
This got us thinking - what could be the simplest and best solution to add Elasticsearch support on Superset?
Connecting Python and Elasticsearch
Superset is written in Python and uses SQLAlchemy to connect to SQL-speaking databases. Until now, there was no option to connect to Elasticsearch from SQLAlchemy.
We chose the following process for building this:
- Implement a python database driver for Elasticsearch that follows the DBAPI specification
- Create a SQLAlchemy dialect for Elasticsearch. For context, SQLAlchemy a popular SQL toolkit and Python Object Relationship Mapper (ORM)
- Open-source the code for all this
- Publish 1 and 2 as a Pypi (Python Package Index) package
With this driver and dialect in the open, Elasticsearch is now accessible to a wide range of existing python applications (including Superset!). Below, we have provided a quick guide to installation with code snippets.
Let's take a look on how to use it.
Installation
pip install elasticsearch-dbapiIf you have an available elasticsearch cluster you can use it, if not you can clone the project and start one (Kibana included):
git clone git@github.com:preset-io/elasticsearch-dbapi.git
cd elasticsearch-dbapi
docker-compose up -dNow, wait a few seconds and then:
Access Kibana (http://localhost:5601) to import the provided sample Flights data.
Finally, write a simple python script to query our cluster:
from es.elastic.api import connect
conn = connect(host='localhost')
curs = conn.cursor().execute(
"select * from kibana_sample_data_flights LIMIT 10"
)
print([row for row in curs])How easy was that?
As a follow up, if you're curious on how to write a Python Database API Specification (dbapi) check out PEP-249.
Integrating Python, Elasticsearch and Apache Superset
Now that you have set up your Python and Elasticsearch, it's time to integrate with Superset. Superset implements an abstract database (DB) specification. This generic DB integration can be specifically implemented to support any kind of DB that has a python driver and is compliant with PEP-249. This specification creates an abstract layer between Superset and any DB engine.
Using this set up, let's see what flight carrier has canceled more flights.
First, let's look at all of the data from the Flights dataset charts and dashboard.
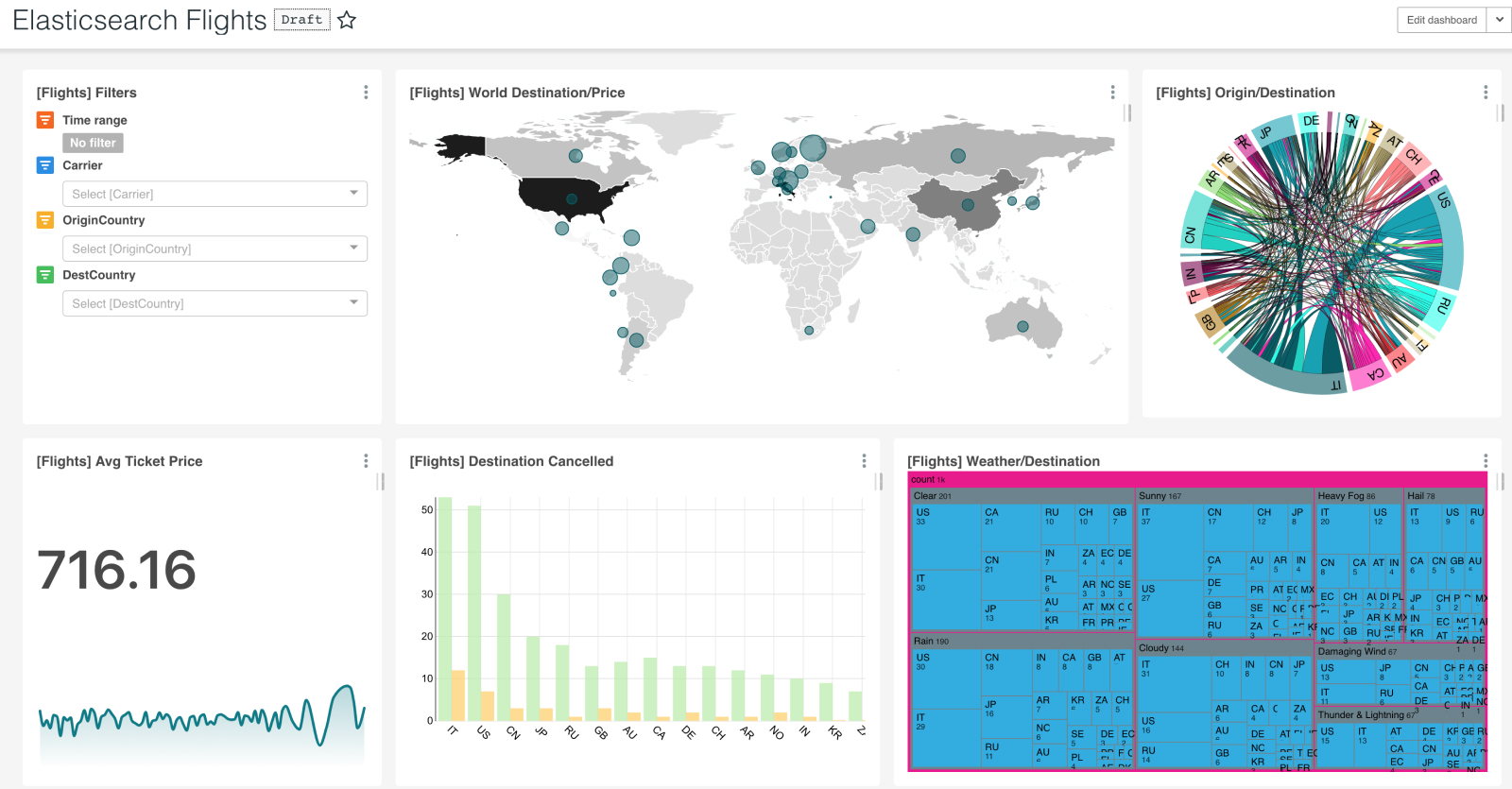
Navigate to SQL Lab.
Protip: there is no concept of schema on Elasticsearch so we expose a "default" schema
It's also important to remember that Indexes are treated like Relational Database Management System (RDBMS) tables.
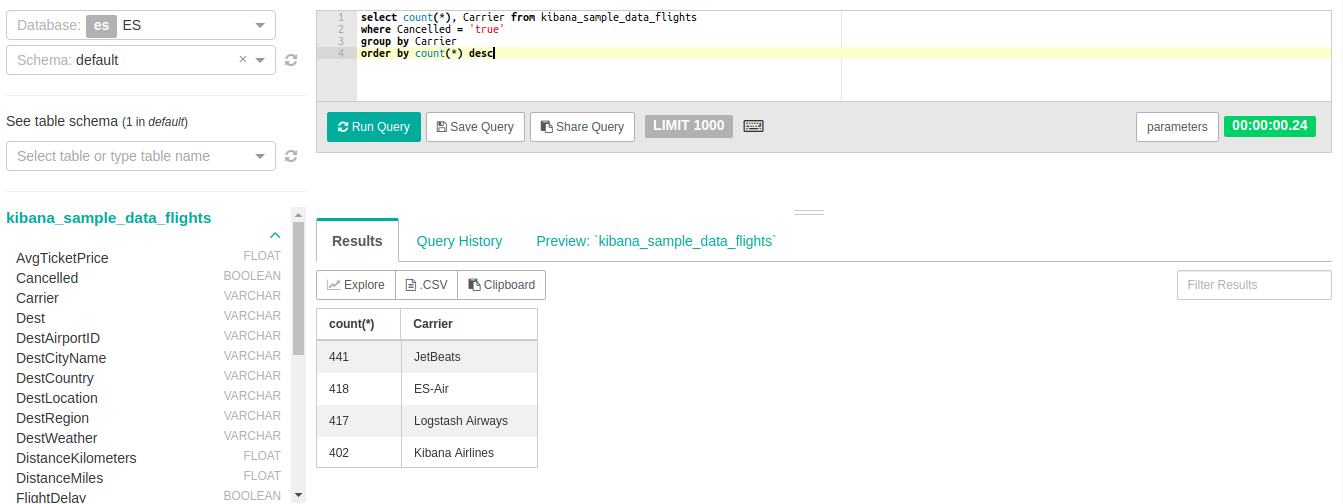
"JetBeats" is the dreaded winner. Happy Flying and thanks for reading our how to guide and example.
Here are some additional resources for you:
- The pull request adding Elasticsearch support to Superset
- Learn more and star the Apache Superset Open Source Project
- Create your first Dashboard in Apache Superset
- The elasticsearch-dbapi Python package, and the related repository on Github
- Contribute to Apache Superset
Related Reading
- Building a Database Connector for Superset: How database connectors work under the hood
- Real-Time vs Time-Series Databases: Understanding different database types
- Connecting Superset to BigQuery: Cloud data warehouse tutorial
- Visualizing ClickHouse Data: Another analytics database tutorial
